- The paper presents a comprehensive survey comparing traditional geometric methods with neural scene representations to assess their utility in robotics.
- It explains the trade-offs in memory efficiency, resolution, and computational demands, highlighting improvements with foundation models.
- The study emphasizes practical implications for robotic modules in perception, mapping, and manipulation while proposing unified future approaches.
Summary of "What Is The Best 3D Scene Representation for Robotics? From Geometric to Foundation Models"
This paper undertakes a comprehensive survey of existing 3D scene representation methods within the context of robotics, exploring both traditional geometric models and modern neural techniques. The authors deliberate the advantages and challenges associated with each representation, scrutinizing their applicability across various robotic modules. The exploration pivots around finding the optimal representation to facilitate robotic autonomy, emphasizing the emergence of foundation models as a potential unified solution for future applications.
Traditional vs. Neural Scene Representations
Geometric Representations
Geometric representations such as point clouds, voxels, and Signed Distance Functions (SDF) have traditionally underpinned robotic scene understanding. Point clouds offer straightforward surface representation but at the cost of memory inefficiencies and sparse data challenges. Voxel grids provide structured volumetric mapping, efficient for computational querying yet limiting in resolution due to discretization constraints. SDFs facilitate precise surface modeling with implicit functions, crucial for applications requiring high geometric fidelity, though computationally demanding.
Neural Scene Representations
Neural Radiance Fields (NeRF) utilize multi-layer perceptrons to encode 3D scenes, offering continuous volumetric representation. NeRF excels in producing photorealistic views but struggles with geometric precision necessary for certain robotic applications. However, enhancements like NeuS and VolSDF have introduced implicit surface modeling into NeRF frameworks, working towards better geometric fidelity.
3D Gaussian Splatting (3DGS) emerges as a real-time rendering solution, modeling scenes with anisotropic Gaussians for efficient rasterization. Despite speed advantages, memory overhead remains a challenge, pushing for advancements in compression techniques and hybrid representation models. Foundation models represent scenes as tokenized embeddings, offering open-vocabulary and zero-shot capabilities across tasks, which are pivotal in integrating language understanding with robotic spatial reasoning.
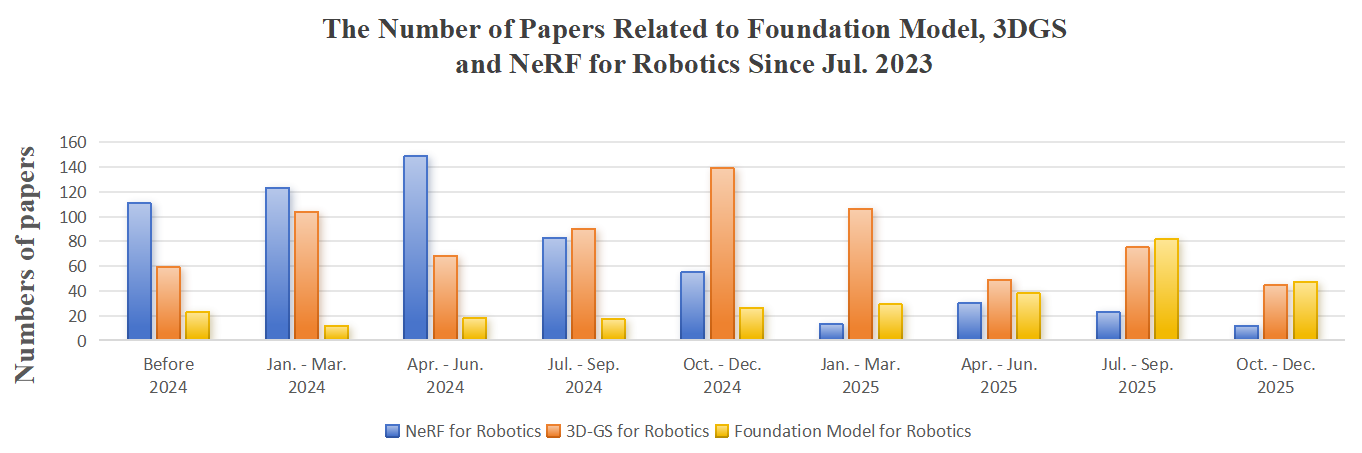
Figure 1: A shift from NeRF to 3DGS and foundation models over time illustrates evolving research focus within the robotics community.
Application in Robotic Modules
Perception
Perception in robotics leverages both object-centric and scene-level semantic representations. Traditional methods use explicit geometric encodings for real-time object detection, while NeRF and 3DGS integrate continuous geometry for more sophisticated understanding. Foundation models feature open-vocabulary grounding, enhancing perception with language-based semantics, a promising direction for natural interaction in robotics.
Mapping and Localization
Mapping applications, from SLAM to global localization, benefit differently from each representation. NeRF and 3DGS enable dense photorealistic renderings crucial for navigation and teleoperation. Meanwhile, explicit geometric encodings ensure robust localization performance through established methods like ICP and NDT. Foundation models, by leveraging semantic understanding and language grounding, propose transformative approaches for localization through vision-language integration.

Figure 2: Mapping and localization strategies span different scale applications, showcasing diverse representation utilities.
Manipulation and Navigation
Manipulation demands precise geometric modeling for object interaction, where traditional representations offer established solutions. However, NeRF-based approaches are emerging with potential for handling transparent and complex objects. For navigation, neural representations provide insights for sophisticated trajectory planning beyond traditional occupancy maps, especially when coupled with semantic and linguistic embeddings from foundation models.
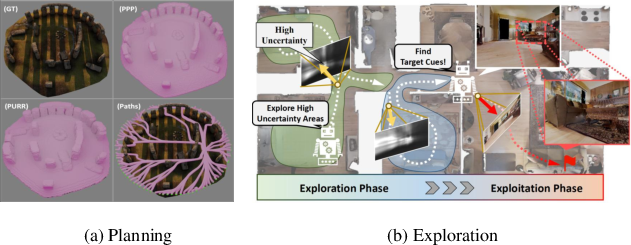
Figure 3: Navigation frameworks demonstrate the potential of neural scene representations in enhancing robotic interaction with environments.
Implications and Future Directions
The paper highlights critical challenges in current scene representation implementations, particularly concerning scalability, memory efficiency, and applicability to diverse robotic tasks. Foundation models suggest a unifying framework, with robust semantic capabilities facilitating holistic scene comprehension across modules. Future research should address data scarcity through simulation and generative models, emphasizing scalable architectures for real-time deployment.
Conclusion
The paper delineates the evolving landscape of 3D scene representations in robotics, advocating for the integration of foundation models to bridge existing gaps between geometric precision and computational feasibility. This approach could eventually facilitate general-purpose robotic intelligence, enabling flexible, adaptive, and coherent interactions across complex environments, mirroring the adaptability observed in human cognition and learning systems.
