G$^2$VLM: Geometry Grounded Vision Language Model with Unified 3D Reconstruction and Spatial Reasoning
Abstract: Vision-LLMs (VLMs) still lack robustness in spatial intelligence, demonstrating poor performance on spatial understanding and reasoning tasks. We attribute this gap to the absence of a visual geometry learning process capable of reconstructing 3D space from 2D images. We present G$2$VLM, a geometry grounded vision-LLM that bridges two fundamental aspects of spatial intelligence: spatial 3D reconstruction and spatial understanding. G$2$VLM natively leverages learned 3D visual geometry features to directly predict 3D attributes and enhance spatial reasoning tasks via in-context learning and interleaved reasoning. Our unified design is highly scalable for spatial understanding: it trains on abundant multi-view image and video data, while simultaneously leveraging the benefits of 3D visual priors that are typically only derived from hard-to-collect annotations. Experimental results demonstrate G$2$VLM is proficient in both tasks, achieving comparable results to state-of-the-art feed-forward 3D reconstruction models and achieving better or competitive results across spatial understanding and reasoning tasks. By unifying a semantically strong VLM with low-level 3D vision tasks, we hope G$2$VLM can serve as a strong baseline for the community and unlock more future applications, such as 3D scene editing.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces SpaceLM, a smart computer model that can both:
- rebuild a 3D scene from regular photos or video, and
- understand where things are, how they are arranged, and how they move.
Think of SpaceLM like a superpowered “photo-to-3D” and “spatial reasoning” assistant. It doesn’t just recognize what’s in pictures (like a cat or a chair); it also figures out where those things are in 3D space and uses that to answer tricky questions about the scene.
What questions did the researchers ask?
The team wanted to fix a common weakness in today’s Vision-LLMs (VLMs). These are AI systems that look at images and talk about them. Many VLMs are good at recognizing objects, but not so good at understanding the layout of a scene. The paper asks:
- How can we help a VLM understand 3D space better, not just flat 2D images?
- Can a model learn to build 3D scenes and use that extra 3D knowledge to reason about questions like “Which object is behind the table?” or “From this angle, what would you see?”
- Can we do both tasks—3D reconstruction and spatial reasoning—in one unified model?
How did they build SpaceLM?
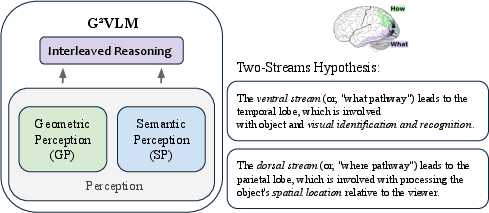
To make this work, the authors designed SpaceLM with two “specialist paths” that work together, inspired by how the brain processes vision:
Two pathways: the “What” and the “Where”
- The “What pathway” (Semantic Expert): This part is good at understanding what’s in the image—objects, actions, and general visual content. It’s like the part of your brain that recognizes faces or reads signs.
- The “Where pathway” (Geometry Expert): This part focuses on 3D geometry—depth, camera position, and the 3D location of pixels. It’s like the part of your brain that helps you judge distance and find your way around a room.
These two specialists share information using a system called “shared attention.” Imagine a team meeting where both experts listen and talk to each other, so the final answer combines object knowledge with 3D spatial awareness.
Learning in two stages
- Stage 1: Teach the Geometry Expert. It is trained from scratch using datasets that include 3D information (like depth and camera positions). This helps it learn to build 3D scenes from regular photos.
- Stage 2: Teach the Semantic Expert to use the geometry. Now both parts of the model are trained together on spatial reasoning tasks (like answering “which object is closer?”). During this stage, the model uses lots of multi-view images and videos. In one version (SpaceLM-SR), they also continue training the geometry part so both skills improve together.
What do “3D reconstruction” and “spatial reasoning” mean here?
- 3D reconstruction: Turning 2D images into a 3D map—like placing dots in space to show where each pixel would be in a 3D world. This includes:
- Depth estimation: figuring out how far each pixel is from the camera.
- Point maps: a 3D position for each pixel.
- Camera pose: where the camera was and which direction it pointed.
- Spatial reasoning: Answering questions like:
- “Which box is behind the chair?”
- “If you rotate the camera 90°, what will you see?”
- “Is the robot’s arm to the left of the table?”
A simple analogy
- Imagine you’re playing Minecraft and building a house. The “What” expert knows what blocks and furniture you used. The “Where” expert knows the exact coordinates of every block and the position of your camera. SpaceLM combines both so it can answer questions like “Which room is above the kitchen?” and also build or edit the scene.
What did they find?
The researchers tested SpaceLM on two types of tasks: building the 3D scene and reasoning about it.
- 3D reconstruction: SpaceLM performed as well as leading specialized 3D models on tasks like estimating depth and camera position. For example, on the Sintel benchmark for depth, it improved a key error measure compared to a strong model (VGGT).
- Spatial reasoning: SpaceLM did even better. On several benchmarks designed to test spatial understanding (like SPAR-Bench, MindCube, and OmniSpatial), SpaceLM and its spatial-reasoning version (SpaceLM-SR) matched or beat much larger and popular models. On SPAR-Bench, SpaceLM-SR even scored about 18.5 points higher than GPT-4o, while being a much smaller model.
Why is this important?
- It shows that giving a model a built-in sense of 3D geometry makes it better at understanding scenes, not just naming objects.
- It proves one model can do both low-level geometry (building 3D maps) and high-level reasoning (answering complex spatial questions).
What’s the impact of this research?
SpaceLM could be useful in many areas:
- Robotics: Helping robots understand where things are to move safely and manipulate objects.
- AR/VR and 3D editing: Turning phone videos into editable 3D scenes and answering “what happens if I move the camera here?”
- Smart homes and assistance: Understanding room layouts and helping plan tasks.
- Education and games: Teaching geometry and physics with real-world scenes.
It also suggests a better way to build Vision-LLMs:
- Don’t just train models to recognize “what.” Teach them “where” too. When the model can rebuild 3D scenes, its answers become more accurate and useful.
- This approach scales well: after the geometry expert is trained, the combined model can learn better reasoning from lots of regular multi-view images and videos.
In short, SpaceLM shows that mixing 3D scene-building with language understanding makes AI not just smarter, but more grounded in the real physical world—closer to the way people see, think, and move through space.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list highlights what remains missing, uncertain, or unexplored, with concrete directions to guide future research:
- Interleaved reasoning mechanism is under-specified: the paper does not detail how predicted 3D geometry is inserted into the LLM’s token stream, how prompts/templates reference geometry, or how intermediate geometric outputs guide step-by-step reasoning. Provide explicit protocols, formats, and ablations on different integration strategies.
- Alignment between geometric and semantic representations is implicit: there is no explicit alignment loss or adapter to ensure the semantic expert reliably “reads” geometry tokens through shared self-attention. Investigate explicit cross-modal alignment (e.g., contrastive or distillation objectives, cross-attention bridges) and quantify gains over the current implicit approach.
- No uncertainty or confidence modeling for geometry predictions: the model outputs point maps, normals, and poses without calibrated confidence/uncertainty estimates, which limits downstream reasoning and robustness. Add uncertainty heads, probabilistic losses, or ensemble methods; evaluate how uncertainty weighting affects spatial reasoning accuracy.
- Metric scale and camera intrinsics are not addressed for real-world deployment: predictions rely on scale factors and Sim(3) alignment; there is no strategy to recover metric scale or handle unknown intrinsics in robotics/embodied tasks. Explore self-calibration, IMU fusion, or learned scale priors; benchmark on tasks requiring absolute metric fidelity.
- Dynamic scene handling is untested: feed-forward geometry can struggle with moving objects, motion blur, rolling shutter, and non-Lambertian surfaces; the paper presents qualitative examples but no quantitative evaluation. Add dynamic-scene benchmarks (e.g., KITTI, Waymo, DAVIS), motion segmentation, or scene flow to assess robustness.
- Limited long-horizon spatio-temporal evaluation: OST-Bench results are reported on a ≤15-frame subset; memory and long-context capabilities remain unclear. Evaluate full-length sequences, memory persistence, loop closure, and scaling laws with longer videos.
- Failure mode analysis is missing on geometry tasks: SpaceLM underperforms SOTA on several metrics (e.g., point accuracy/completion, pose AUC), but the paper lacks diagnostics (e.g., textureless regions, wide baselines, extreme viewpoints). Provide systematic error breakdowns and targeted architectural/data remedies.
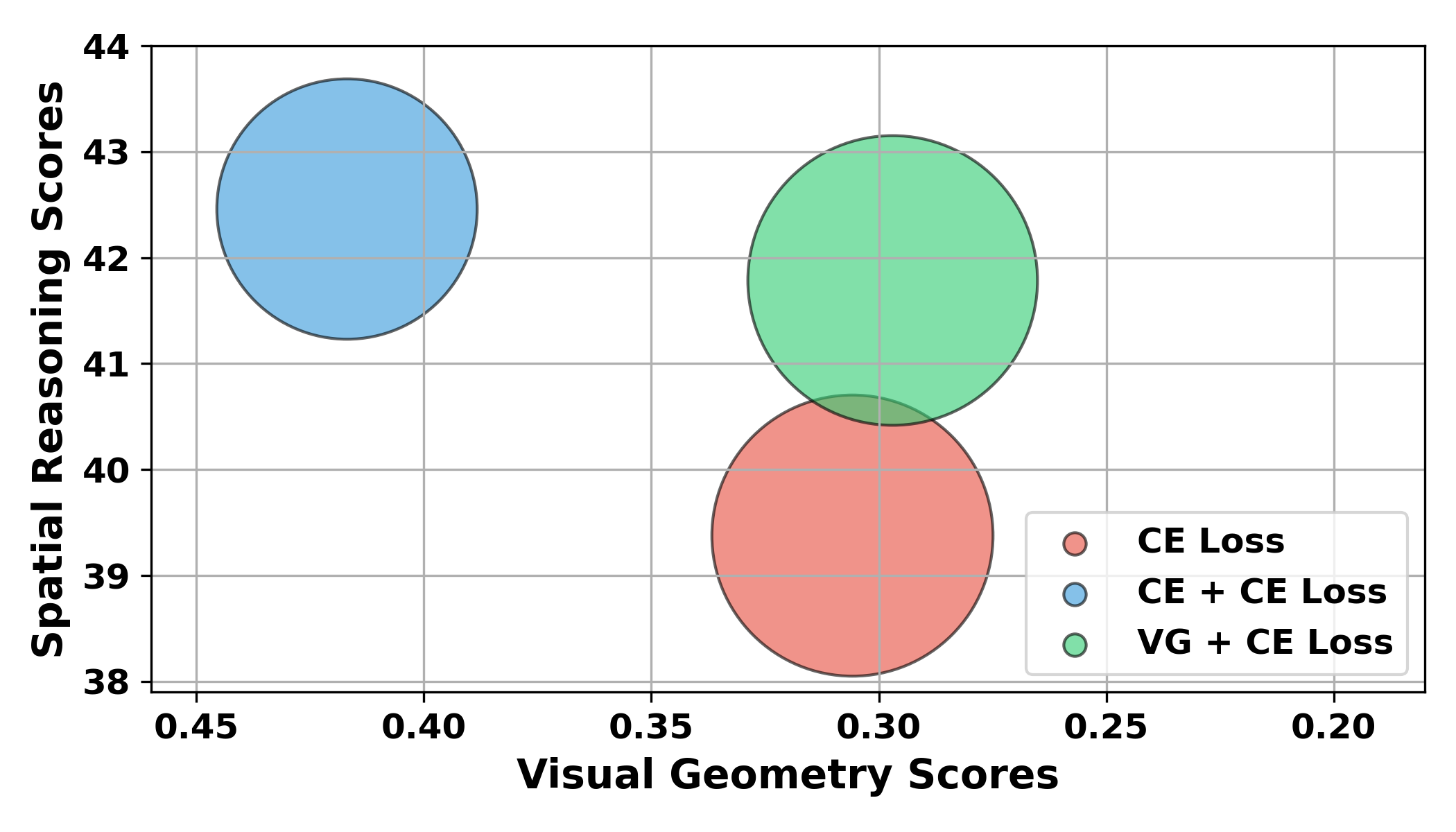
- Scalability constraints for joint training with VG+CE loss: authors note this approach is strongest but requires large-scale 3D annotations, limiting scalability. Explore self-supervised or weakly supervised geometric training signals from videos (e.g., multi-view consistency, photometric reconstruction) to reduce dependence on hard-to-collect labels.
- Expert architecture and routing are not explored: the Mixture-of-Transformer-Experts uses two fixed experts with shared self-attention; there is no learned routing/gating, more experts, or task-aware token assignment. Study sparse MoE routing, dynamic expert selection, or hierarchical experts for geometry and semantics.
- Permutation equivariance claim is not validated: while the design claims permutation equivariance (as in ), there is no formal proof or empirical test (e.g., shuffled frame orders, variable cardinalities) showing invariance/equivariance. Add controlled tests and proofs to substantiate the property.
- Token/interface design choices lack ablation: register tokens are removed and global attention is used, but the impact on semantic comprehension (e.g., object grounding, fine-grained attributes) is not quantified. Compare configurations with/without register tokens, cross-attention, and hierarchical attention.
- Data transparency and potential bias/leakage: internal synthetic datasets are used for pretraining but not described (composition, licenses, overlap with test sets). Release dataset specs, audit for overlap, and assess domain biases in benchmarks.
- Domain coverage is narrow in quantitative geometry evaluation: core results focus on indoor (NYU, 7Scenes) and synthetic (Sintel) or small-scale outdoor (ETH3D). Add autonomous driving (KITTI, Waymo), aerial (UAV), and large outdoor photogrammetry datasets to measure generalization.
- Inference efficiency and deployment details are absent: the paper reports heavy training compute (32–64 A800 GPUs) but does not provide inference speed, memory footprint, or maximum supported frames under realistic constraints. Benchmark latency/throughput on commodity GPUs/edge devices and analyze memory scaling.
- Normal loss supervision is under-specified: it requires ground-truth normals, but the derivation (from depth/mesh) and datasets providing reliable normals are not described. Clarify normal ground truth sources and evaluate sensitivity to normal quality/noise.
- Robustness to adverse conditions is not evaluated: lighting changes, weather, occlusions, sensor noise, and camera artifacts are not tested. Include stress tests and report degradation patterns; explore robustness training (augmentation, adversarial examples).
- Calibration and safety for spatial reasoning are not measured: the model may hallucinate geometry or misinterpret spatial relations; there is no calibration (e.g., expected accuracy vs. confidence) or safety assessment. Add reliability metrics, abstention mechanisms, and error-aware reasoning strategies.
- Integration pathways for 3D scene editing and robotics are unspecified: future applications are suggested without concrete APIs or task pipelines (selection/edit operations, world-coordinate constraints, semantic-geometry alignment). Prototype interfaces and evaluate on controlled editing/manipulation tasks.
- Effect of training data quality and instruction style in spatial reasoning remains unclear: spatial datasets (SPAR-7M, OmniSpatial, MindCube, OST) vary in annotation quality and prompt formats; there is no study of data curation, filtering, or instruction tuning strategies on performance. Conduct controlled data-quality ablations and prompt-style experiments.
- Cross-modal extensions are unexplored: audio, depth sensors, IMU, or LiDAR could strengthen spatial reasoning, but the model is purely RGB. Investigate multi-sensor fusion and its impact on geometry and reasoning.
- Causality of geometry–reasoning interplay is not established: while correlation is shown (better geometry yields better reasoning), confounders (e.g., shared data/domain) are not ruled out. Use controlled experiments (swap encoders, synthetic counterfactuals) to isolate causal contributions.
- Fairness of comparisons to feed-forward geometry baselines is unclear: SpaceLM differs in token designs (no camera tokens), training schedules, and pretraining; apples-to-apples comparisons (same data, resolution, schedules) are not demonstrated. Provide matched training protocols and report relative gains.
- Maximum input cardinality and degradation curves are not reported: training samples 2–24 frames, but inference limits and performance scaling with more/fewer views are not quantified. Measure accuracy vs. number of frames and computational cost curves.
- Formalization of interleaved reasoning steps is lacking: the paper does not describe a standardized sequence (e.g., predict geometry → reason over schema → revise answer), nor whether iterative refinement (self-consistency) is used. Define and test structured reasoning loops and their benefits.
- Licensing, reproducibility, and ablation completeness: while GitHub is linked, training relies on internal data and extensive compute; reproducing results may be impractical. Release trained weights, data recipes, and minimal compute baselines; expand ablations (e.g., encoder swaps, attention mask variants, tokenization).
Practical Applications
Immediate Applications
The following items outline specific, deployable use cases that can leverage SpaceLM’s unified 3D reconstruction and spatial reasoning today. Each item names the sector, a potential tool/product/workflow, and assumptions/dependencies affecting feasibility.
- Phone-based rapid 3D capture and measurement (Construction, Real Estate, DIY)
- Tool/product/workflow: Mobile app that converts short multi-view videos into point clouds, depth maps, and camera poses; exports to CAD/BIM. Supports spatial QA (“Will the sofa fit between the two walls?”) via SpaceLM-SR.
- Assumptions/dependencies: Requires multi-view footage with sufficient parallax; metric scale calibration via known dimensions, IMU/ARKit/ArCore, or fiducials; good lighting; edge or cloud GPU for geometry inference.
- Visual inspection and spatial QA in warehouses/manufacturing (Logistics, Manufacturing)
- Tool/product/workflow: Camera-driven compliance checks for aisle widths, pallet placement, safety zones; shelf slotting verification; spatial exception alerts with natural-language explanations.
- Assumptions/dependencies: Stable camera placement; controlled lighting; policy acceptance for automated audits; integration with WMS/MES; thresholds for acceptable error in AbsRel depth and pose accuracy.
- Robotics pick-and-place and navigation (Robotics)
- Tool/product/workflow: ROS node that fuses SpaceLM’s point maps and relative poses with spatial reasoning (“Which object is left of the blue bin?”; “Is there clearance for grasp?”) to improve manipulation and local navigation.
- Assumptions/dependencies: Real-time constraints (latency and throughput); handling dynamic scenes and occlusions; metric scaling via robot sensors (IMU/LiDAR) or known-object priors; safety certification.
- E-commerce AR fit checking and staging (Retail)
- Tool/product/workflow: Browser/phone plugin reconstructing room geometry from a video; spatial reasoning verifies clearances and recommended placements; “Will the 2.2 m table block the door swing?”
- Assumptions/dependencies: Accurate scale recovery; robust generalization to clutter; consumer privacy and consent; cloud inference cost control.
- Digital twin refresh from ad-hoc captures (Software/IoT)
- Tool/product/workflow: Pipeline that ingests multi-view imagery to update indoor digital twins; compares current geometry against baseline, flags changes via spatial reasoning.
- Assumptions/dependencies: Consistent coordinate alignment across captures (Sim(3)/ICP); drift mitigation; change detection thresholds; storage and version control.
- Workplace safety compliance audits (Policy, Occupational Safety)
- Tool/product/workflow: Smartphone-based audits that reconstruct spaces and answer spatial compliance questions (walkway width, clearance to sprinklers) with explainable reasoning traces.
- Assumptions/dependencies: Legal acceptance of automated measurements; calibration for metric scale; audit chain-of-custody; standardized checklists.
- Insurance claims documentation (Finance)
- Tool/product/workflow: Accident scene reconstruction from video; spatial reasoning to compute positions, distances, and object relationships; export annotated 3D evidence packages.
- Assumptions/dependencies: Forensic-grade chain-of-custody; documented calibration steps; error bounds; privacy and redaction policies.
- Spatial reasoning tutor for STEM and design (Education)
- Tool/product/workflow: Interactive exercises that ask and verify spatial relations across multi-view images/videos; explain steps using interleaved geometric-semantic reasoning.
- Assumptions/dependencies: Curated pedagogical content; age-appropriate UX; robust moderation; cost-effective inference at classroom scale.
- Cultural heritage and site documentation (Academia, Public Sector)
- Tool/product/workflow: Quick scanning of artifacts or rooms to produce point maps and camera poses; spatial reasoning assists with cataloging relations (e.g., “Which carvings are on the north wall?”).
- Assumptions/dependencies: Lighting and texture quality; occlusion management; export formats compatible with archives; non-destructive workflows.
- Dataset bootstrapping via pseudo-labels (Academia, ML R&D)
- Tool/product/workflow: Use SpaceLM to generate depth, point maps, and relative poses as pseudo-labels for multi-view datasets; train downstream models without expensive 3D annotation.
- Assumptions/dependencies: Careful QA on pseudo-label quality; domain shift management; bias auditing; storage and compute pipelines.
- AR navigation stability indoors (Software, Robotics)
- Tool/product/workflow: Camera-pose estimation stabilizes AR overlays; spatial reasoning avoids occlusions (“Place the label where it’s not blocked by the chair”).
- Assumptions/dependencies: Sufficient features for robust pose; dynamic crowd handling; sync with ARKit/ARCore; latency constraints.
- Video-to-3D for creators (Media/Entertainment)
- Tool/product/workflow: Blender/Unity plugin to convert short clips into point clouds and meshes; natural-language spatial queries (“Select all lights above the stage”) to accelerate scene setup.
- Assumptions/dependencies: Denoising and mesh post-processing; texture capture; scene scale alignment; creator workflow integration.
Long-Term Applications
These opportunities likely require additional research, scaling, or systems integration beyond current capabilities (e.g., robust metric-scale recovery, real-time constraints, broader generalization), but are strongly suggested by SpaceLM’s architecture and results.
- Natural-language 3D scene editing (Software, Media)
- Tool/product/workflow: Edit 3D scenes via language (“Move the chair 0.5 m closer to the window,” “Replace the table with a round one”) using unified geometry + reasoning and future generative backends.
- Assumptions/dependencies: Coupling with mesh-aware generative models; precise constraint handling; reversible edits; UI/UX for change auditing.
- General-purpose household robots with spatial common sense (Robotics)
- Tool/product/workflow: Embodied agents that reconstruct scenes, reason about spatial relations, and plan manipulations and navigation from raw cameras.
- Assumptions/dependencies: Real-time, low-latency inference; safety certification; long-horizon planning; robust handling of dynamic/novel objects; hardware acceleration.
- City-scale mapping and planning analytics (Urban Planning, Policy, Energy)
- Tool/product/workflow: Distributed capture (dashcams, drones) to reconstruct and reason over public spaces (curb ramps, sidewalk widths, street furniture spacing).
- Assumptions/dependencies: Large-scale data orchestration; regulatory approvals; privacy-preserving analytics; precise global scale via GPS/IMU/LiDAR fusion.
- Autonomous drone inspection with language-guided tasks (Energy, Infrastructure)
- Tool/product/workflow: Lightweight onboard reconstruction and spatial QA for power lines, solar farms, bridges; language tasks (“Check spacing between insulators on tower 12”).
- Assumptions/dependencies: Onboard compute and power budgets; IMU/camera fusion for metric scale; adverse weather/lighting robustness; collision avoidance.
- Clinical workflow optimization and safety checks (Healthcare)
- Tool/product/workflow: OR/clinic layout reconstruction; spatial reasoning confirms sterile zones, equipment placement, egress paths; explainable reports for accreditation.
- Assumptions/dependencies: Strict privacy compliance (HIPAA/GDPR); high accuracy and traceability; hospital IT integration; validated error bounds.
- Smart-home fall-risk and hazard assessment (Healthcare, Policy)
- Tool/product/workflow: Periodic scans to identify trip hazards and insufficient clearances; personalized recommendations via spatial reasoning.
- Assumptions/dependencies: Resident consent and privacy; reliable scale recovery; continuous monitoring policies; false-positive management.
- Interactive CAD co-pilot (Software, Engineering)
- Tool/product/workflow: Language-driven constraints and spatial edits inside CAD; “Align these brackets 20 mm from the edge and maintain 90-degree relation.”
- Assumptions/dependencies: Parametric constraint satisfaction; version control and design provenance; precise unit handling; integration with major CAD APIs.
- Emergency response situational awareness (Public Safety)
- Tool/product/workflow: Rapid interior reconstructions during/after incidents; spatial queries (“Which corridors provide egress without obstruction?”).
- Assumptions/dependencies: Highly robust inference under smoke/dust/low light; certified operational procedures; operator training; evidence preservation.
- Autonomous retail stores (Retail, Operations)
- Tool/product/workflow: Continuous shelf reconstruction and reasoning for restocking, planogram compliance, and shrink detection via spatial relations.
- Assumptions/dependencies: Store-wide camera networks; multi-agent coordination; domain-specific thresholds; privacy policies.
- Scientific fieldwork automation (Academia, Environmental Science)
- Tool/product/workflow: Robots that reconstruct and reason about complex terrains (cave mapping, archeology digs) with natural-language guidance.
- Assumptions/dependencies: Extreme-condition resilience; metric scale under sparse features; specialized hardware; permit and safety compliance.
- Multi-agent spatial collaboration (Software, Robotics)
- Tool/product/workflow: Shared 3D representations and spatial reasoning across agent teams (drones + ground robots) with language coordination.
- Assumptions/dependencies: Consistent global frames; bandwidth and synchronization; conflict resolution; security.
- Edge deployment of geometry-grounded VLMs (Software, Hardware)
- Tool/product/workflow: Quantized SpaceLM variants on embedded GPUs/NPUs enabling on-device reconstruction + spatial QA.
- Assumptions/dependencies: Model compression and acceleration; thermal/power constraints; acceptable accuracy trade-offs; real-time optimizations.
Notes on feasibility, dependencies, and assumptions across applications
- Data requirements: Multi-view images or short videos with sufficient parallax perform best; dynamic scenes and heavy occlusions can degrade accuracy.
- Metric scale: Absolute measurements require calibration (IMU, known object sizes, ARKit/ARCore, markers) or sensor fusion; otherwise outputs are up-to-scale.
- Compute and latency: Geometry inference benefits from GPU acceleration; real-time robotics/drones need optimized, possibly quantized models and efficient attention mechanisms.
- Generalization and bias: Performance depends on domain similarity to training data; out-of-distribution scenes require validation and possibly fine-tuning.
- Safety, privacy, and regulation: Many deployments (healthcare, public spaces) require strict compliance, explainability, and evidence management.
- Model variants: SpaceLM-SR improves spatial reasoning but joint training depends on large-scale 3D-annotated datasets; the CE-only variant scales more easily on video data while preserving geometry expert performance.
- Interoperability: Downstream pipelines may need mesh post-processing, Sim(3)/ICP alignment, and integration with ROS, BIM/CAD, Unity/Unreal, or enterprise systems.
Glossary
- Absolute Relative Error: A scale-invariant error metric commonly used to evaluate depth estimation accuracy by comparing predicted and ground-truth depths. "it reduces the monocular depth estimation Absolute Relative Error from VGGT's 0.335 to 0.297 on the Sintel benchmark."
- Ablation study: A systematic evaluation approach where components or design choices are varied or removed to assess their impact on performance. "We also discuss our design choices and validate them through a detailed ablation study in ~\ref{sec: discussion}."
- AdamW optimizer: An optimization algorithm that decouples weight decay from the gradient update to improve training stability and generalization. "For joint-training, we use AdamW optimizer for $16$K iterations with a lr of 2e-5 on 64 A800 GPUs over 3 days."
- alternating-attention layers: Transformer layers that alternate between attention restricted within frames and attention across all frames to capture local and global context. "adopt transformers with alternating-attention layers, which switch between frame-wise and global attention."
- angular accuracy: A metric for pose estimation that measures how accurately predicted rotation and/or translation directions align with ground truth in terms of angles. "we evaluate predicted camera poses on the Co3Dv2~\cite{reizenstein2021common} dataset, which features over 1000 test sequences, using angular accuracy."
- Any-to-Any input and output paradigm: A unified model capability to flexibly handle multiple modalities and tasks with variable input and output types. "in an Any-to-Any input and output paradigm spanning audio, image, and video"
- Area Under the Curve (AUC): An aggregate metric summarizing performance across thresholds, here used for pose accuracy curves. "The Area Under the Curve (AUC) of the min(RRA,RTA)-threshold curve serves as a unified metric."
- auto-regressive next-token prediction: A training objective where the model predicts the next token given previous tokens, commonly used in language modeling. "and are trained with auto-regressive next-token prediction, which treat inputs like multiple images or video frames as a ``flat'' sequence of 2D data."
- bfloat16 precision: A reduced-precision floating-point format (brain floating point) that saves memory while maintaining numerical robustness in deep learning training. "and leverage bfloat16 precision and gradient checkpointing to improve GPU memory and computational efficiency."
- camera pose: The position and orientation of a camera in 3D space, typically represented as a transformation. "across depth estimation, point estimation, and camera pose estimation tasks."
- camera token: A special token used in some architectures to encode camera parameters or pose as part of the transformer input. "we also remove the camera token designs as in VGGT, and use permutation equivariant design as in "
- cosine scheduler: A learning-rate schedule that follows a cosine decay pattern to stabilize and improve training. "with a learning rate (lr) of 2e-4 using cosine scheduler."
- cross-entropy (CE) loss: A standard classification and language modeling loss that measures the difference between predicted and target probability distributions. "where the semantic perception expert is, by default, optimized using a cross-entropy (CE) loss:"
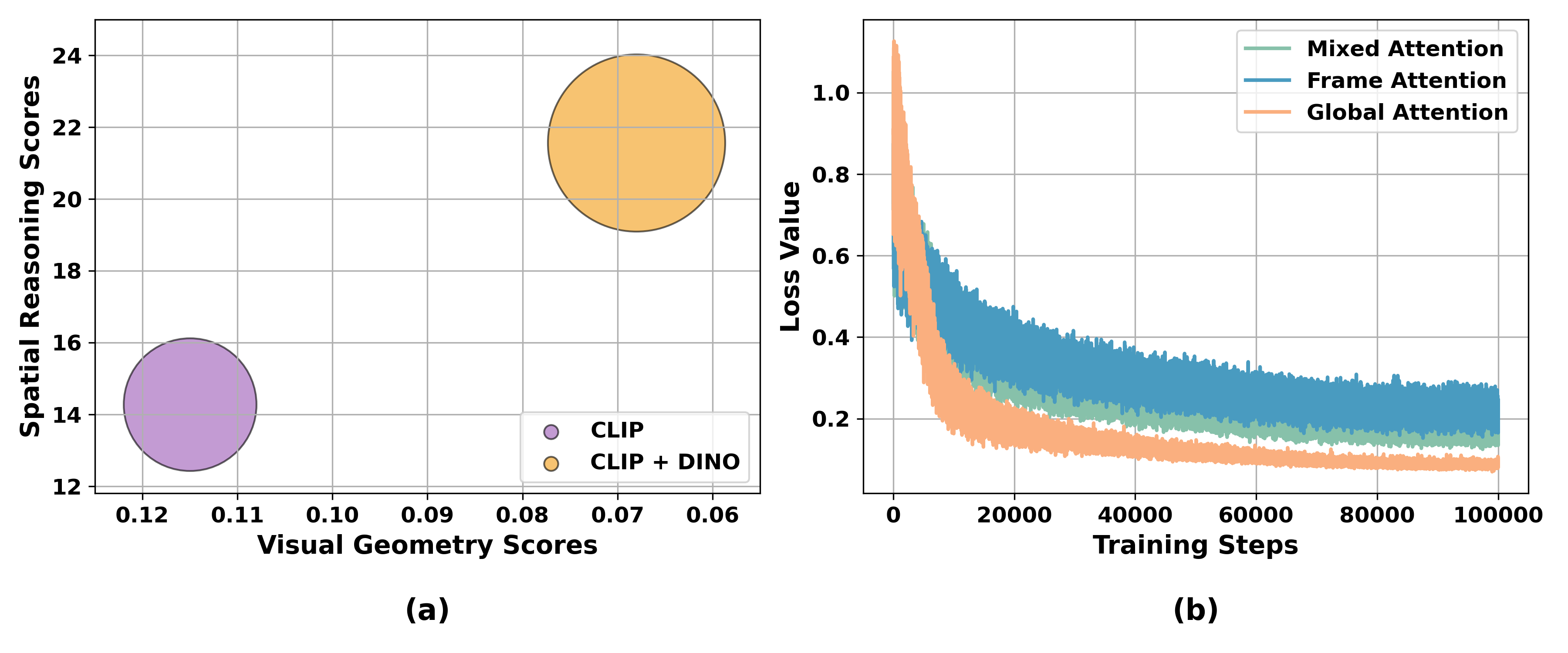
- DINOV2: A self-supervised vision encoder that provides strong low-level visual features useful for geometry and dense prediction tasks. "we incorporate a DINOV2 vision encoder to inject low-level visual information to LLM"
- end-to-end inference: A direct prediction pipeline without iterative optimization, producing outputs in a single forward pass. "These methods adopt a simple and efficient end-to-end inference to predict accurate 3D geometries, surpassing optimization-based pipelines."
- feed-forward 3D reconstruction: A class of methods that reconstruct 3D geometry from images in one forward pass, without optimization loops. "achieving comparable results to state-of-the-art feed-forward 3D reconstruction models"
- frame attention: An attention mask configuration where tokens attend only within their own frame, emphasizing local relationships. "1) frame attention, where the mask is applied to each frame individually;"
- geodesic distance: The shortest path or angular distance on a manifold; in rotations, it measures angular difference between two rotations. "The rotation loss minimizes the geodesic distance (angle) between the predicted relative rotation and its ground-truth target :"
- geometric perception expert: The dedicated component in a multi-expert architecture focused on learning and predicting 3D geometry. "one geometric perception expert (our ``where pathway'') for visual geometry learning"
- global attention: An attention mechanism where tokens can attend across all frames/tokens, enabling global correspondence reasoning. "and use only global attention layers."
- gradient checkpointing: A memory-saving technique that recomputes activations during backpropagation to reduce peak GPU memory usage. "and leverage bfloat16 precision and gradient checkpointing to improve GPU memory and computational efficiency."
- gradient norm clipping: A stabilization technique that caps the gradient norm to prevent exploding gradients during training. "we employ gradient norm clipping with a threshold of $1.0$ to ensure training stability"
- Huber loss: A robust loss function less sensitive to outliers than L2, commonly used for regression tasks like translation estimation. "The translation loss is calculated using the Huber loss, , by comparing scaled prediction against the ground-truth relative translation, :"
- in-context learning: The ability of a model to use information presented in the prompt or input sequence to perform new tasks without parameter updates. "enhance spatial reasoning tasks via in-context learning and interleaved reasoning."
- interleaved reasoning: A reasoning process that alternates between different modalities or intermediate predictions (e.g., geometry and language) within a single chain of thought. "For spatial reasoning questions, SpaceLM can directly predict 3D geometry and employ interleaved reasoning for an answer."
- Iterative Closest Point (ICP) algorithm: An algorithm to refine alignment between point clouds by iteratively minimizing distances between corresponding points. "followed by refinement with the Iterative Closest Point (ICP) algorithm."
- LLM hidden states: The internal vector representations produced by a LLM for tokens or inputs, used for downstream predictions. "This process maps each image to LLM hidden states ."
- mask-based attention: Attention configurations implemented via masks that constrain which tokens can attend to which others (e.g., frame vs. global). "Therefore, we explore three mask-based attention variants: 1) frame attention, where the mask is applied to each frame individually; 2) global attention, where the mask is applied to the entire sequence of all frames; and 3) mixed attention, which randomly alternates between masks to encourage the model to learn both local geometry and global correspondence."
- Mixture-of-Transformer-Experts (MoT): An architecture that combines multiple specialized transformer experts within one model, often routed or jointly attended. "SpaceLM adopts a Mixture-of-Transformer-Experts (MoT) architecture that consists of two transformer experts"
- mixed attention: A strategy that alternates or mixes attention masks to encourage both local and global correspondence learning. "and 3) mixed attention, which randomly alternates between masks to encourage the model to learn both local geometry and global correspondence."
- monocular depth estimation: Estimating scene depth from a single RGB image, up to an unknown scale. "we evaluate our method on monocular depth estimation task using the Sintel~\cite{bozic2021transformerfusion} and NYU-V2~\cite{silberman2012indoor} datasets."
- Multimodal Rotary Position Embedding (M-RoPE): A positional embedding method adapted to multimodal inputs to encode positions/ordering. "along with the design of Multimodal Rotary Position Embedding (M-RoPE)."
- normal loss: A loss encouraging surface smoothness or correct local geometry by aligning predicted and ground-truth surface normals. "Finally, the normal loss $\mathcal{L}_{\text{normal}$ encourages the reconstruction of locally smooth surfaces by minimizing the angle between the predicated normal vector and their ground-truth counterparts :"
- permutation equivariant design: A property ensuring model outputs are consistent under permutations of input order, important for unordered sets or multi-view inputs. "and use permutation equivariant design as in "
- pixel-aligned 3D point maps: Dense 3D point representations where each image pixel is associated with a 3D point in space. "to directly predict pixel-aligned 3D point maps."
- point cloud reconstruction loss: A loss that measures discrepancy between predicted and ground-truth 3D points, often scale-aware or weighted by depth. "The point cloud reconstruction loss, $\mathcal{L}_{\text{points}$, is defined using the optimal scale factor :"
- register tokens: Special tokens added to transformer inputs to improve representation capacity or routing, often used in vision transformers. "we simplify some designs such as not incorporating register tokens"
- Relative Rotation Accuracy (RRA): The percentage of pose pairs whose rotation error is below a given angular threshold. "This process yields the Relative Rotation Accuracy (RRA) and Relative Translation Accuracy (RTA) at a given threshold (e.g., RRA@30 for 30 degrees)."
- Relative Translation Accuracy (RTA): The percentage of pose pairs whose translation direction error is below a given angular threshold. "This process yields the Relative Rotation Accuracy (RRA) and Relative Translation Accuracy (RTA) at a given threshold (e.g., RRA@30 for 30 degrees)."
- ROE solver: A specific solver (from prior work) used to obtain reliable depth or scale-related quantities for supervision. "and is solved using the ROE solver proposed by~\cite{wang2025moge}."
- SE(3): The Lie group of 3D rigid-body transformations combining rotation and translation. "where is the camera pose"
- semantic perception expert: The component specialized for multimodal understanding and language reasoning within the unified model. "one semantic perception expert (our ``what pathway'') for multimodal understanding."
- shared self-attention: A mechanism where tokens from different experts attend jointly, facilitating information exchange. "These experts interact via shared self-attention, enabling the interplay between these two fundamental aspects to mutually improve one another."
- Sim(3) alignment: A similarity transformation (rotation, translation, uniform scale) used to coarsely align point clouds before refinement. "Predicted point maps are aligned to the ground truth using the Umeyama algorithm for a coarse Sim(3) alignment, followed by refinement with the Iterative Closest Point (ICP) algorithm."
- transformer decoders: Transformer blocks that decode task-specific outputs from hidden states, often via cross-attention to encoded features. "All heads are designed as light-weight transformer decoders."
- two-streams hypothesis: A neuroscience theory proposing separate pathways for object identity (what) and spatial processing (where), inspiring model design. "Our approach is inspired by the two-streams hypothesis in human cognition"
- Umeyama algorithm: A method for estimating a similarity transformation (Sim(3)) between two point sets in a least-squares sense. "using the Umeyama algorithm for a coarse Sim(3) alignment"
- Vision-LLMs (VLMs): Models jointly processing visual and textual inputs to perform multimodal understanding and generation tasks. "Vision-LLMs (VLMs) still lack robustness in spatial intelligence"
- visual geometry (VG) loss: A composite loss combining multiple geometry-related terms (e.g., points, camera, normals) to train the geometry expert. "our visual geometry (VG) loss function is formulated as a weighted sum"
- visual geometry learning: The process of learning to infer 3D structure (e.g., depth, pose, points) from 2D visual inputs. "We propose to integrate visual geometry learning into the VLM."
Collections
Sign up for free to add this paper to one or more collections.