- The paper presents a novel framework, 3DThinker, that integrates 3D mental representations into VLMs using a two-stage training process.
- It employs supervised learning to align VLM-generated 3D latents with a 3D foundation model and reinforcement learning to refine the reasoning trajectory.
- Experimental results demonstrate improved spatial reasoning and generalization across benchmarks, enhancing applications in autonomous driving and embodied AI.
Think with 3D: Geometric Imagination Grounded Spatial Reasoning from Limited Views
Introduction
The paper "Think with 3D: Geometric Imagination Grounded Spatial Reasoning from Limited Views" (2510.18632) addresses a significant challenge in the field of Vision-LLMs (VLMs): the ability to understand and reason about 3D spatial relationships from limited visual inputs. Despite the remarkable advancements in VLMs, their capacity to perform spatial reasoning based on 3D geometry remains limited, often relying on textual or 2D visual inputs. The authors propose a novel framework, 3DThinker, designed to enable VLMs to form 3D mental representations during the reasoning process, thereby enhancing their spatial understanding capabilities.
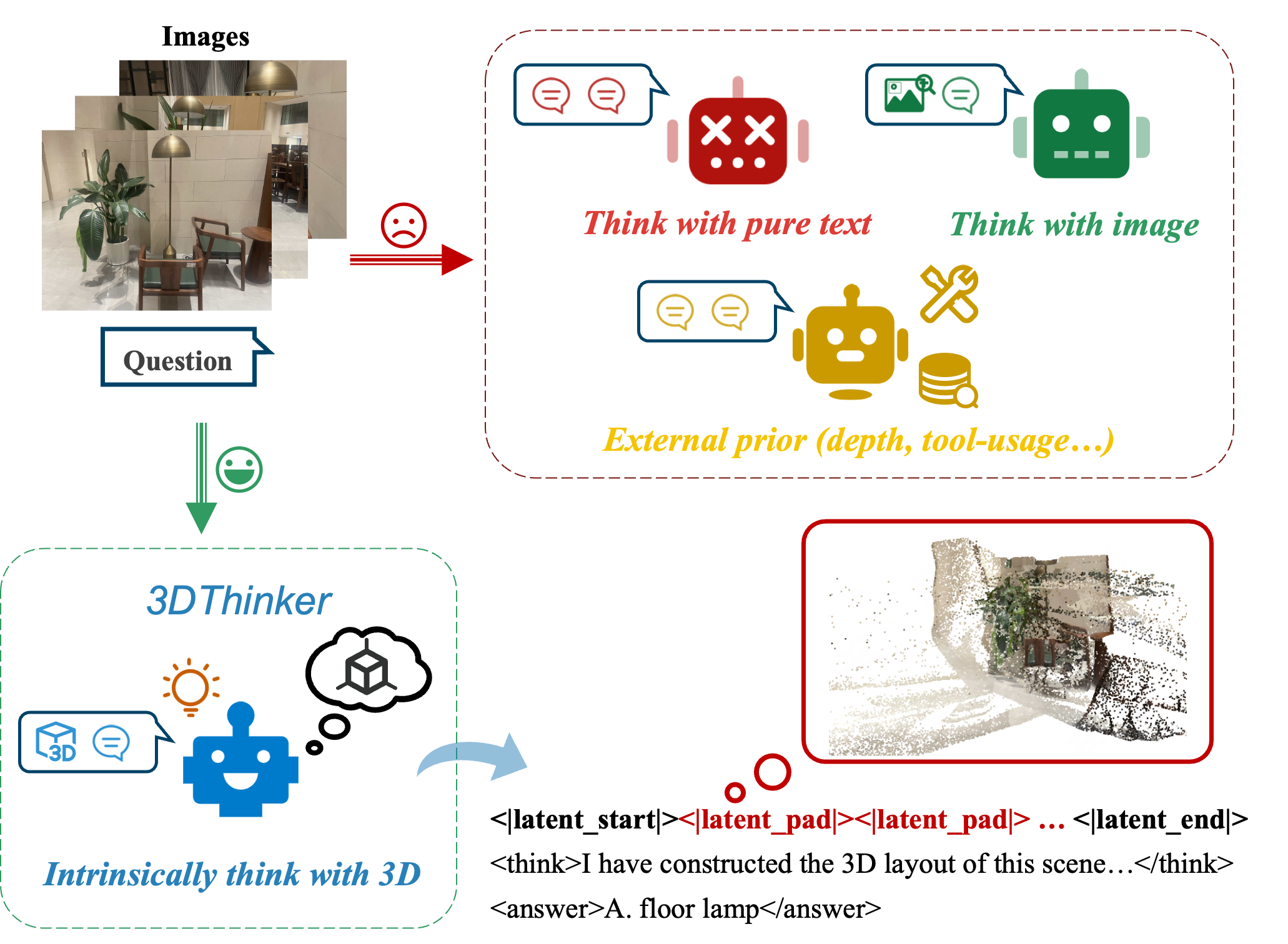
Figure 1: Illustration of our 3DThinker. Existing methods typically perform reasoning based solely on pure text or 2D visual cues, without fully exploiting the rich spatial and geometric information inherent in images.
Methodology
The methodological foundation of 3DThinker lies in its two-stage training process. The first stage involves supervised learning that aligns 3D latent features generated by VLMs with those of a 3D foundation model, such as VGGT, using constructed Chain-of-Thought (CoT) data. This alignment facilitates the integration of 3D spatial reasoning into the model's native processing capabilities without requiring explicitly labeled 3D data. The second training stage employs outcome-driven reinforcement learning (RL) to fine-tune the entire reasoning trajectory, further refining the model's 3D mental representations based on feedback from the output.
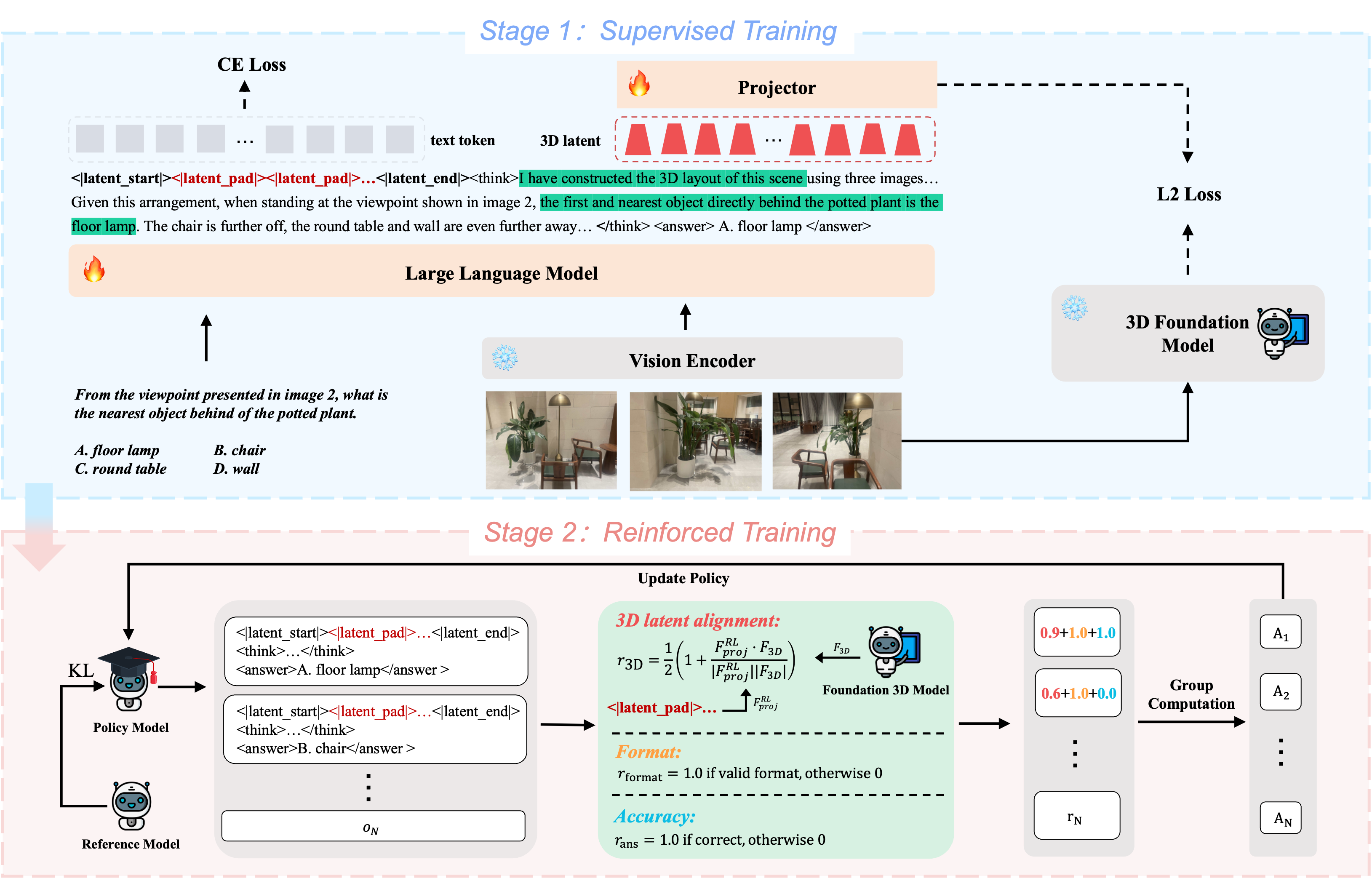
Figure 2: The schematic illustration of our 3DThinker, a framework that enables thinking with 3D mentaling.
The integration of a projector is crucial in this process, as it transforms the VLM-generated 3D latent into the feature space compatible with VGGT, maintaining dimensional consistency throughout the transformation.
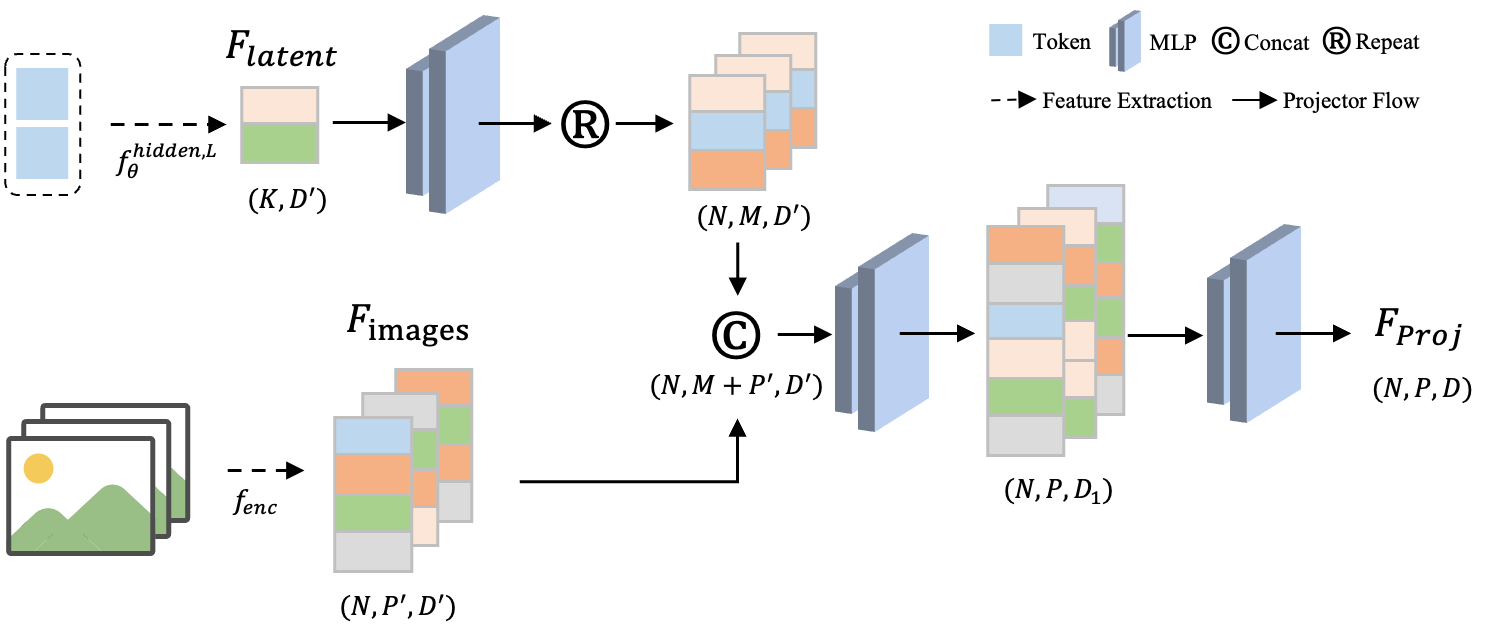
Figure 3: Illustration of our projector, which transforms VLM-generated 3D latent into the feature space of VGGT.
Experimental Results
The paper presents extensive experimental results across various benchmarks, demonstrating that 3DThinker consistently outperforms existing methods in spatial reasoning tasks. The framework shows impressive improvements across multiple benchmarks, achieving significant gains over the baseline models. The integration of 3D mental representations allows for enhanced interpretability and visualization, as the resulting 3D latents can be projected back into 3D space, providing a clear depiction of the model's reasoning process.

Figure 4: The reasoning process for different cases is presented, along with the visualization of the 3D latent representations.
The authors highlight the generalization capability of 3DThinker, as it performs well across different VLM architectures and parameter scales, further validating the robustness of the proposed framework.
Implications and Future Work
The introduction of 3DThinker carries significant implications for the development of VLMs capable of advanced spatial reasoning without reliance on external annotations or priors. This research opens up possibilities for the application of such models in fields requiring spatial intelligence, such as autonomous driving and embodied AI. Future work could explore the integration of autoregressive 3D latent tokens into the framework, enabling more seamless reasoning across multidimensional contexts. Additionally, iterative 3D mentaling could further enhance the model's ability to refine its understanding of complex spatial scenarios dynamically.
Conclusion
In conclusion, 3DThinker represents a significant step forward in the integration of 3D mental representations into vision-language reasoning. By enabling VLMs to imagine and reason with 3D scenarios using limited views, this framework not only enhances the current capabilities of multimodal models but also sets a foundation for future innovations in spatial intelligence. Its ability to operate without annotated 3D input and external tools underscores its potential for widespread applicability across diverse domains.