VideoNSA: Native Sparse Attention Scales Video Understanding
Abstract: Video understanding in multimodal LLMs remains limited by context length: models often miss key transition frames and struggle to maintain coherence across long time scales. To address this, we adapt Native Sparse Attention (NSA) to video-LLMs. Our method, VideoNSA, adapts Qwen2.5-VL through end-to-end training on a 216K video instruction dataset. We employ a hardware-aware hybrid approach to attention, preserving dense attention for text, while employing NSA for video. Compared to token-compression and training-free sparse baselines, VideoNSA achieves improved performance on long-video understanding, temporal reasoning, and spatial benchmarks. Further ablation analysis reveals four key findings: (1) reliable scaling to 128K tokens; (2) an optimal global-local attention allocation at a fixed budget; (3) task-dependent branch usage patterns; and (4) the learnable combined sparse attention help induce dynamic attention sinks.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces VideoNSA, a new way for AI models to understand long videos better and faster. The big idea is to help the model pay attention only to the most useful parts of a video, without throwing away information. This makes the model more accurate on long videos (like sports games, lectures, or movies) and more efficient on computers.
What questions did the researchers ask?
Here are the main questions, in simple terms:
- How can a model watch long videos without getting confused or running out of memory?
- Can we keep all the video information but make the model focus on what really matters?
- What is the best way to divide the model’s attention between close-by moments and far-apart moments in a video?
- Does this smarter attention work better than current shortcuts like compressing or skipping frames?
- How does this attention behave layer by layer inside the model (for example, does it over-focus on unhelpful tokens)?
How does the method work?
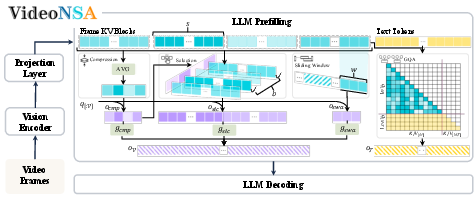
Think of a long video like a giant book full of tiny notes (called “tokens”). Regular models try to read everything and match every note with every other note—that’s slow and overwhelming. VideoNSA uses “sparse attention,” which means it cleverly chooses which notes to compare, saving time and memory while keeping the full content.
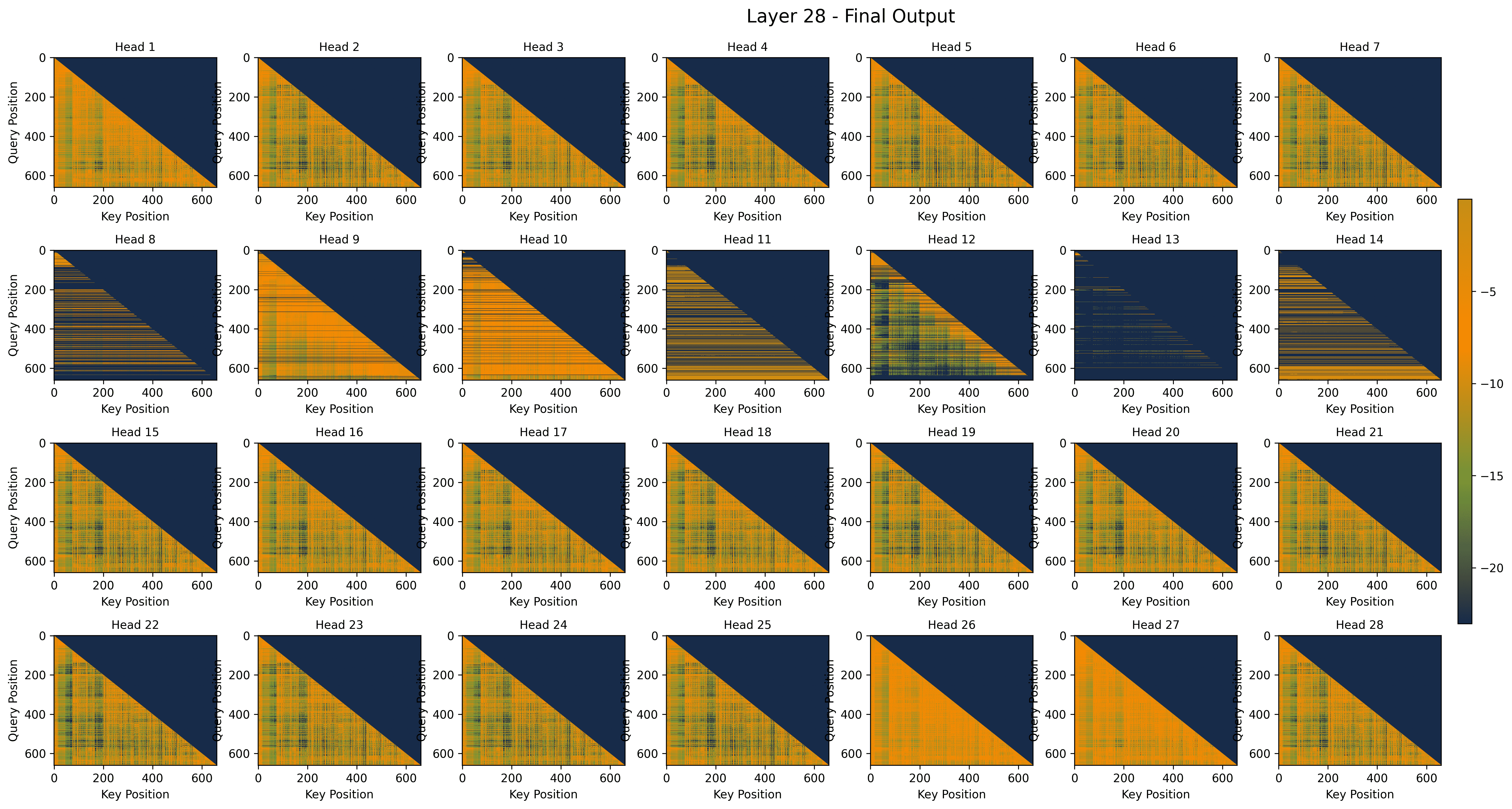
VideoNSA mixes three simple “watching strategies” for video tokens, then blends them together using a learnable controller (a “gate”) that decides how much to trust each strategy at each layer:
The three strategies (branches)
- Compression (CMP): Summarize nearby frames into a short highlight. Like making a quick summary of a paragraph so the model still knows what happened without reading every word.
- Selection (SLC): Pick the most important moments. Like bookmarking the key scenes or “top plays.”
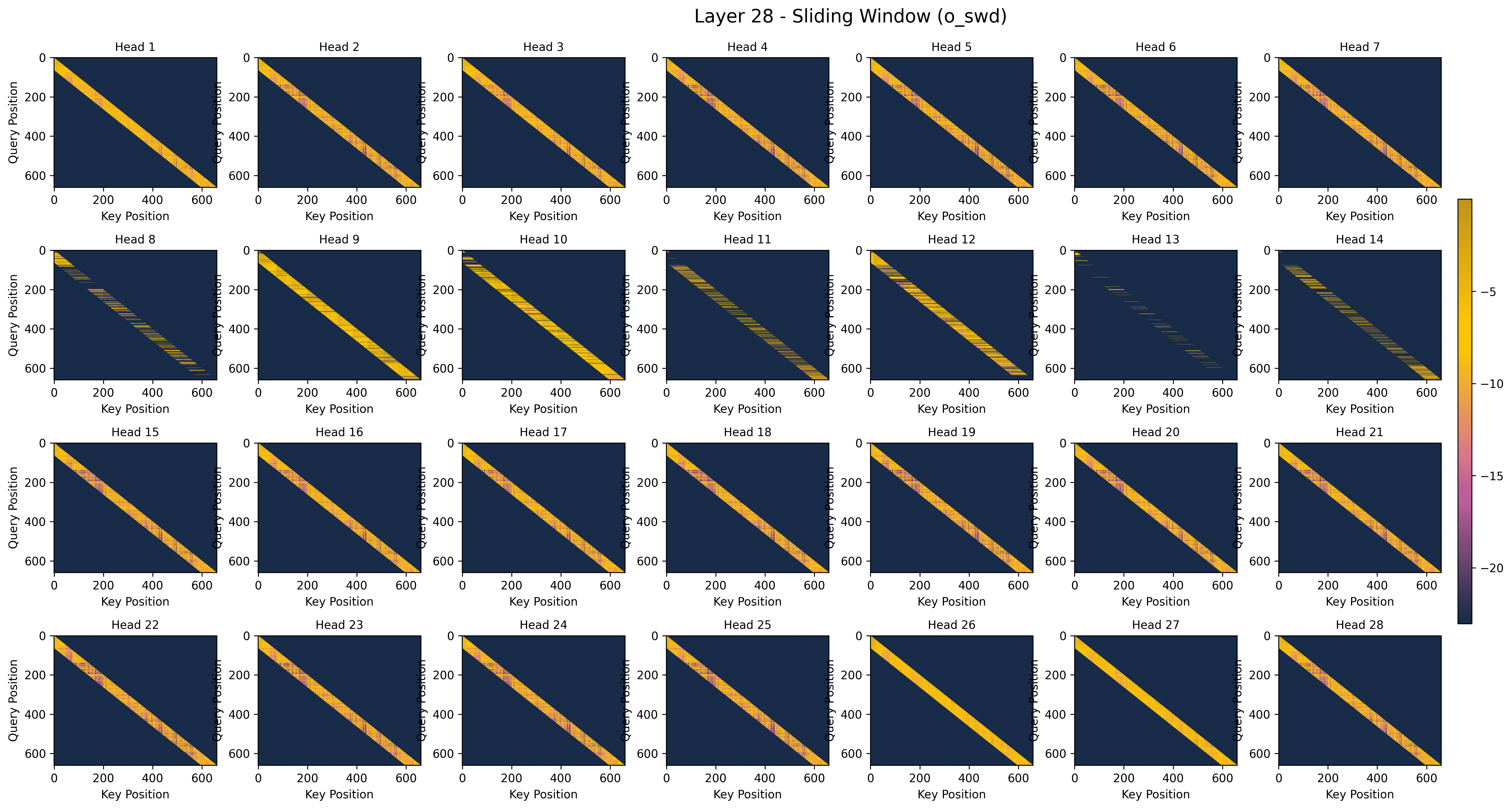
- Sliding window (SW): Look closely at the most recent frames. Like focusing on what just happened to understand what happens next.
The model learns when to use each strategy—early on it may look more locally (sliding window or selection), and later it may lean more on compressed summaries.
Hybrid attention by modality:
- For video: it uses the three sparse strategies above (to scale to long clips).
- For text (the user’s question/instructions): it keeps normal dense attention, so it follows instructions well.
Under the hood:
- The model is based on Qwen2.5-VL-7B (a vision-LLM).
- It groups some attention heads (Grouped-Query Attention) to save memory for text.
- It trains end-to-end on a large set of video question-answer pairs so the attention patterns are learned from data, not hand-coded.
Training setup (in brief and friendly terms):
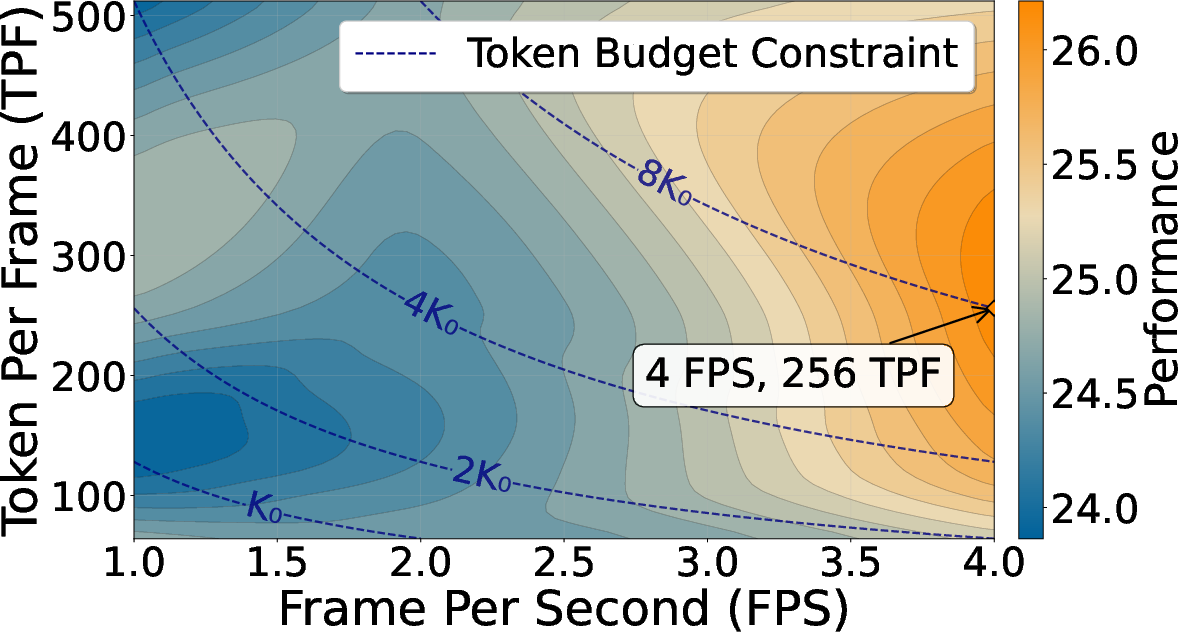
- About 216,000 video instruction pairs, sampled at 4 frames per second, with medium-length clips.
- Trained to handle up to about 36,000 tokens during training, but tested up to 128,000 tokens later (much longer).
- Designed to run efficiently on modern GPUs (“hardware-aware”).
What did they test and what did they find?
They tested the model on three types of skills:
- Long video understanding (watching long videos and answering questions about them)
- Temporal reasoning (understanding order and timing—who did what first, what caused what)
- Spatial understanding (where things are and how they relate in space)
Key results:
- Better than token-compression methods: VideoNSA beats approaches that throw away tokens. Keeping tokens but focusing attention works better for tricky reasoning.
- Strong against other sparse-attention baselines: It matches or improves on other efficient methods, especially on very long videos and order-sensitive questions.
- Scales to long context: It reliably works up to 128K tokens while using only about 3.6% of the “full” attention connections—so it’s efficient and scalable.
Six important findings from their analyses:
- Learned sparse weights help even in dense mode: If you take the model trained with sparse attention and then switch to full attention at test time, some tasks still improve. This suggests the training teaches better attention habits.
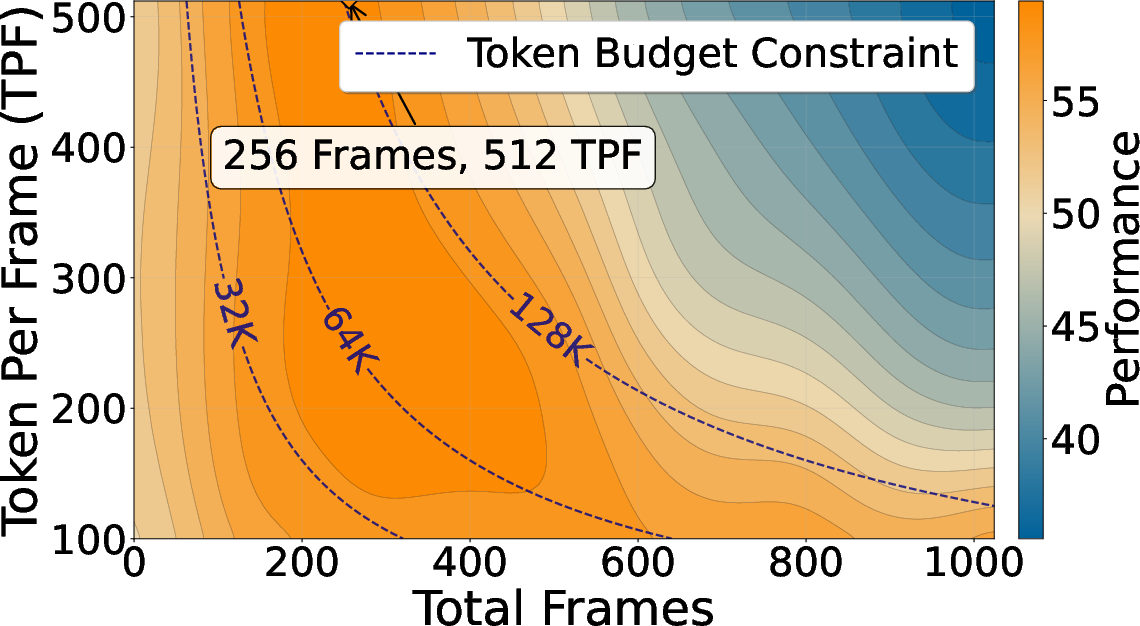
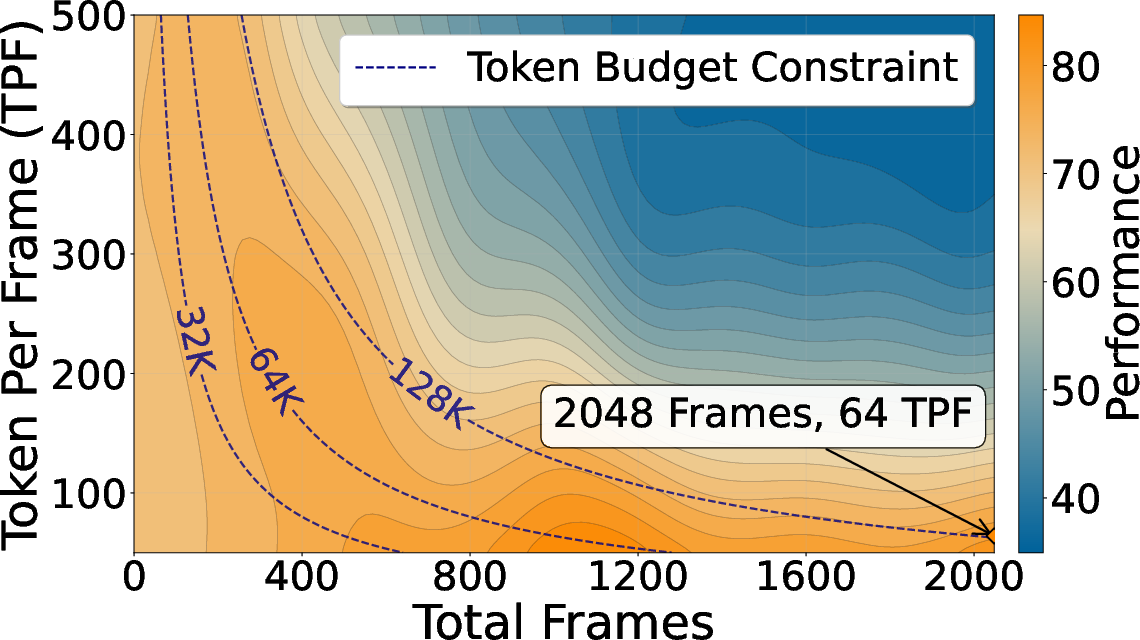
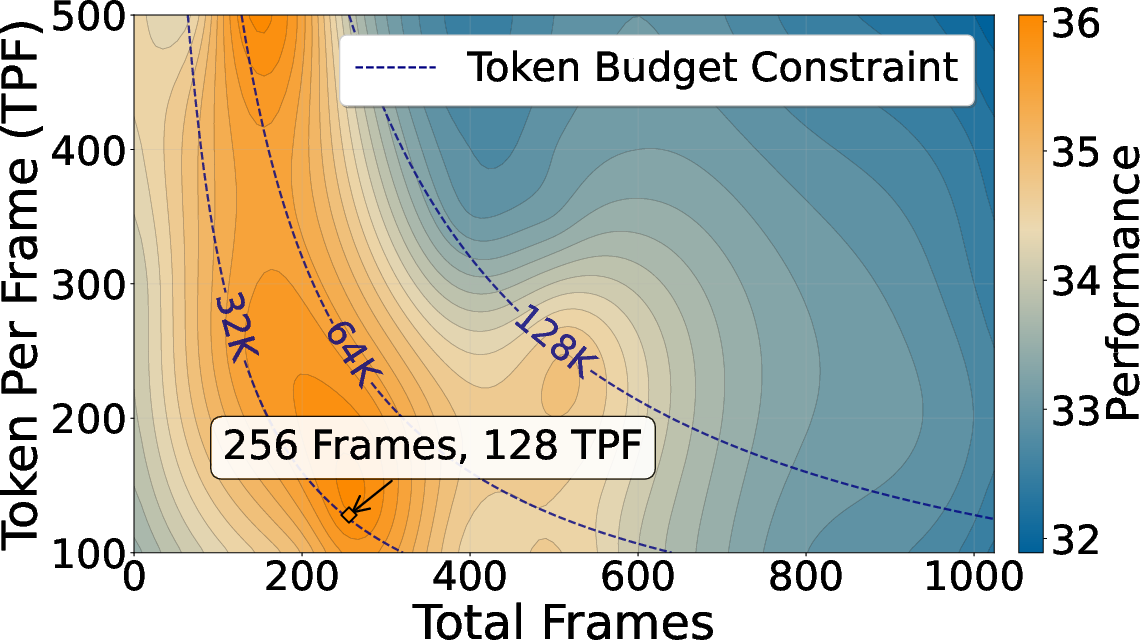
- Scales beyond training: The model trained at 36K tokens still works well at 128K tokens. But the best way to spend tokens depends on the task:
- If you need fine details per frame (spatial), use more tokens per frame.
- If you need long-term story understanding (temporal), show more frames (even if each frame has fewer tokens).
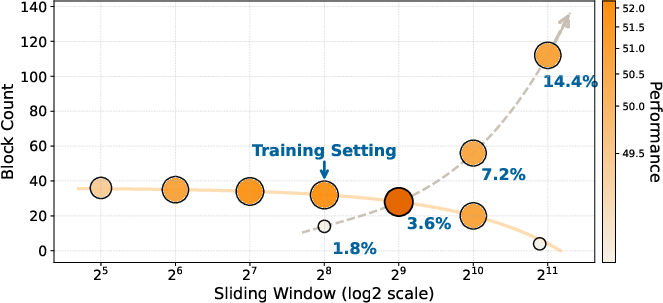
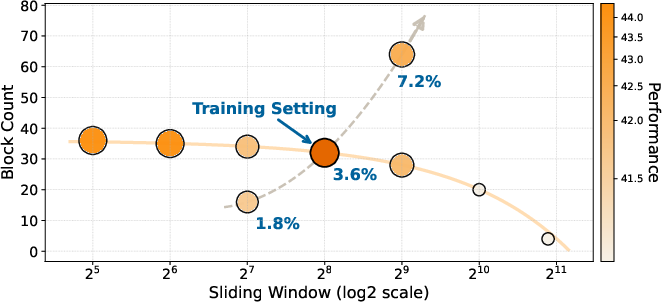
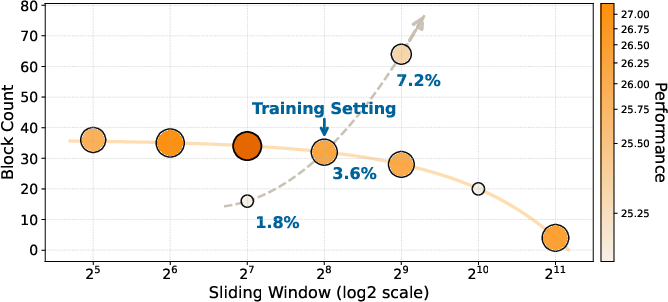
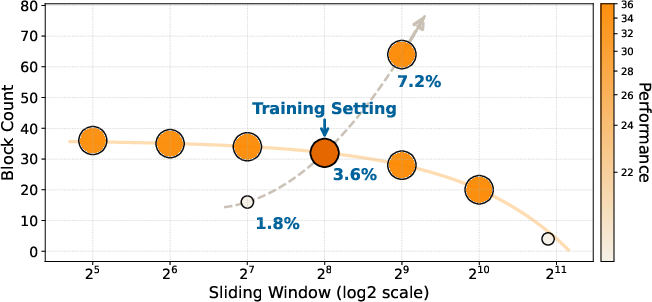
- Attention budget matters: There’s a “budget” for how many past tokens a query can see. How you split it between global connections (far-away frames) and a local window (recent frames) is crucial. Often, having more global reach helps more than just enlarging the local window. Also, staying close to the training setup tends to be safest.
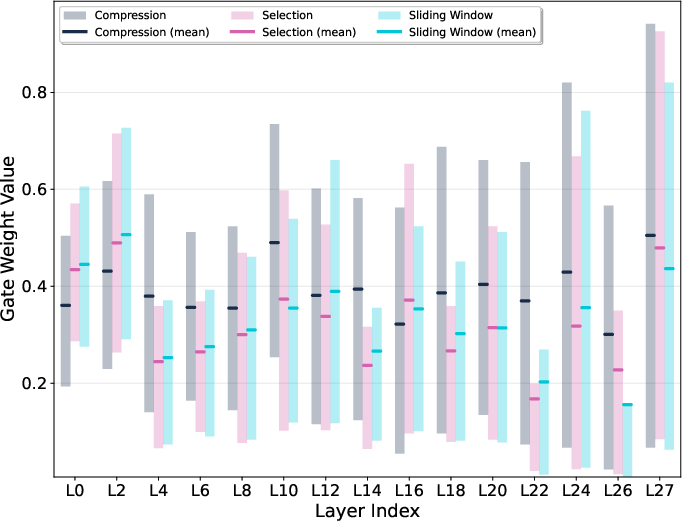
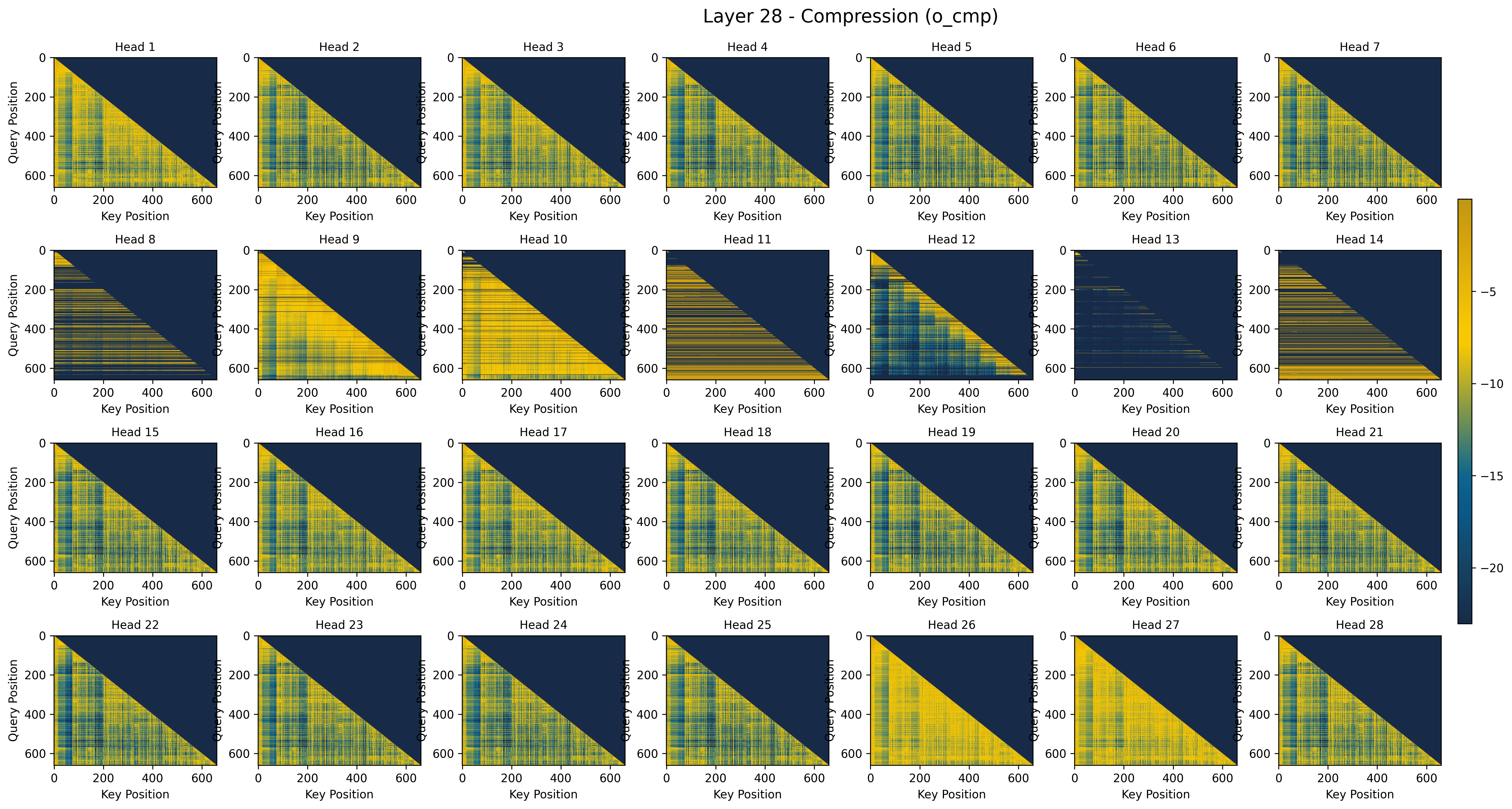
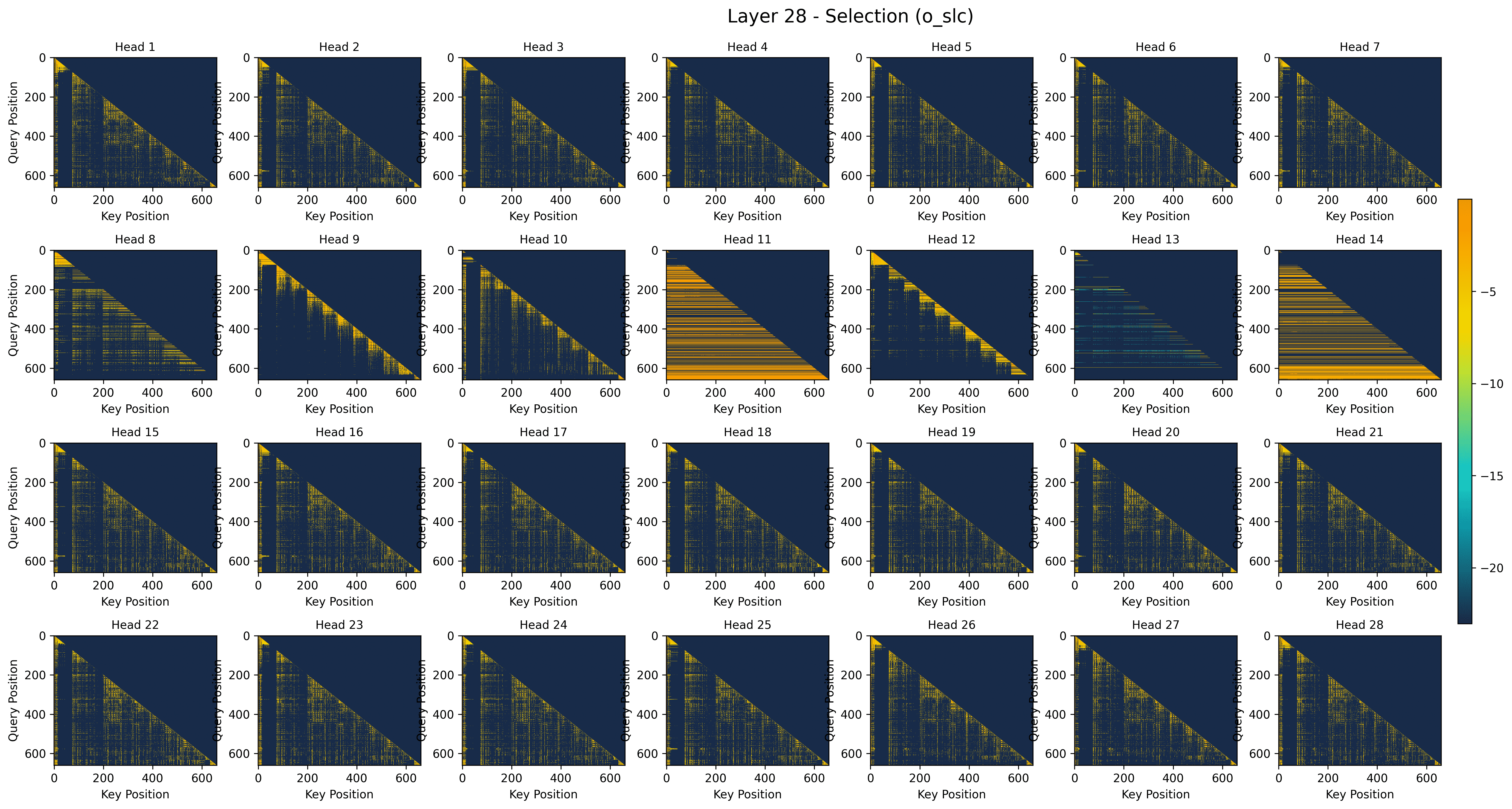
- Gating behavior across layers: The model’s gate prefers the Compression branch in deeper layers (for high-level summaries). Selection and sliding-window are more useful in early/middle layers. Different heads specialize in different roles.
- Speed bottleneck: The Compression branch dominates the runtime for very long videos. It’s the main target for future speedups.
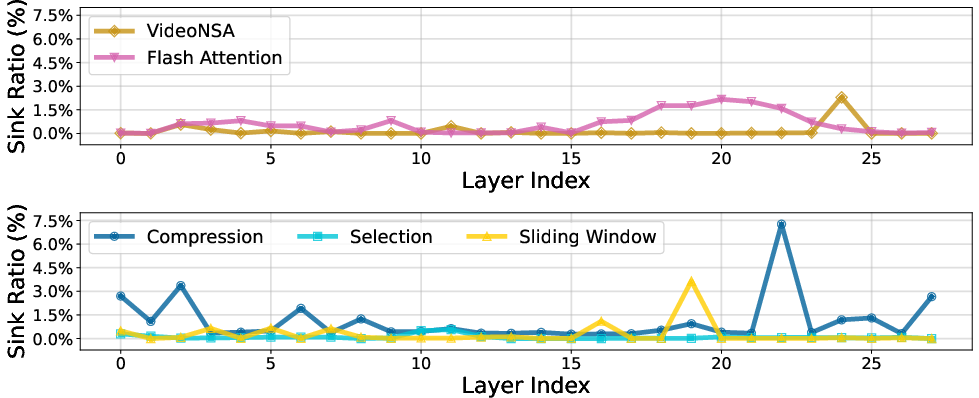
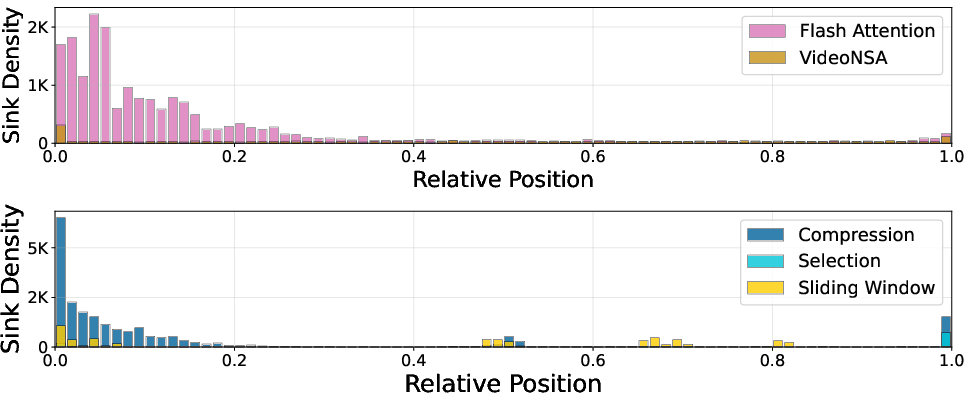
- Fewer “attention sinks”: Some models over-focus on tokens that don’t help much (called “attention sinks”). VideoNSA’s learned sparsity and gating keep the overall sink rate low (~0.3%). The Selection branch almost never creates sinks; Compression can, but the gate balances it out.
Why is this important?
- Handles real-world long videos: Sports highlights, lectures, security footage, documentaries—VideoNSA helps models keep track of important moments over long time spans.
- Keeps information instead of deleting it: Instead of compressing away the content, it preserves tokens and focuses attention, which helps with tricky reasoning tasks.
- Efficient on hardware: It’s built to run well on GPUs, saving memory and time while scaling to very long contexts.
- Practical uses: Better video question answering, summarization, video editing assistance, safety monitoring, education, and scientific analysis.
- Future improvements: Speeding up the compression branch, gathering higher-quality training data, and continuing to test for fairness and bias.
In short, VideoNSA shows a smart way to “watch more while thinking harder,” helping AI models understand long videos with both accuracy and efficiency.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Data coverage and generalization
- Reliance on a filtered subset of LLaVA-Video-178K (4 fps, 350–550 frames) limits diversity; no evaluation on higher-fps, very short clips, or drastically longer sequences beyond the tested 10-hour cases across domains (egocentric, sports, driving, surveillance, medical).
- No analysis of robustness to real-world video artifacts (compression noise, motion blur, dropped frames, variable frame rates) or to domain shift across datasets.
- Training data quality is acknowledged as a limiter (Dense-SFT underperforms), but there is no ablation on data curation quality, synthetic vs. real video proportion, or scaling of training data size.
- Modalities and input signals
- Audio is not modeled; open question: how NSA should allocate sparse budgets across audio-visual tokens and whether cross-modal gating is beneficial.
- Text-in-video (OCR-heavy) scenarios are not separately evaluated; impact of sparse attention on reading small/high-frequency features is unknown.
- Task coverage and evaluation breadth
- Benchmarks are mostly QA/MCQ; no evaluation on long-form generation, dense captioning, temporal grounding with timestamped localization, or action segmentation where precise frame alignment is critical.
- No human evaluation or qualitative error analysis to identify systematic failure modes (e.g., temporal order inversion, miss of rare events).
- Instruction-following capabilities and general multimodal benchmarks (e.g., OCR, chart/diagram understanding, MMMU-style tasks) are not reported post-adaptation.
- Attention design and alternatives
- The token selection (SLC) scoring function is not fully specified; unclear which saliency signals are used and whether alternatives (learned kNN, differentiable retrieval, approximate top-k, RL-based selectors) yield better accuracy/latency trade-offs.
- Compression (CMP) uses averaging at block level; the paper does not test stronger compressive mappings (attention pooling, learned projection, low-rank/PCA, residual compressive transformers) that may reduce information loss and attention sinks.
- Fixed block size s=64, block count b, and window w are tuned but static; no investigation of content-adaptive block sizes, per-layer/per-head block sizing, or dynamic stride scheduling.
- Gating mechanism
- Gating MLP architecture, parameter overhead, and regularization are not ablated; stability and training dynamics (e.g., collapse to one branch, temperature/entropy control) remain unexplored.
- Gates are learned per head, but no study of multi-task or query-conditioned meta-gating that adapts to task/video type at inference time under a fixed compute budget.
- The final-layer anomaly (all branches active after inactivity) is observed but not explained; unclear if this is beneficial or a train-time artifact worth constraining.
- Scaling and allocation policies
- Attention budget sensitivity is high and best performance occurs near training-time allocation; no method is proposed to automatically select or adapt the global–local split per video/query under a fixed latency budget.
- Extrapolation from 36K to 128K tokens is promising but lacks a systematic study of breakdown points, stability under even longer contexts, or numerical precision effects (bf16/fp8) on ultra-long sequences.
- No formal scaling laws that link performance to tokens-per-frame vs. frames-per-video trade-offs across tasks.
- Efficiency, kernels, and hardware assumptions
- Prefill remains the bottleneck; compression branch dominates latency. There is no optimized kernel design for CMP or empirical memory-bandwidth profiling to guide kernel fusion/layout changes.
- Selection branch has worse theoretical complexity (O(L2/b)) but low wall-clock impact; the discrepancy is not dissected (e.g., roofline analysis, caching effects), leaving optimization opportunities unclear.
- Results are reported on H100; portability and performance on A100/consumer GPUs/AMD/TPUs are untested, as are low-VRAM settings and batch-size–latency trade-offs.
- End-to-end throughput vs. dense/sparse baselines (tokens/sec, memory footprint) is not reported across sequence lengths, limiting practical deployment guidance.
- Comparison scope and fairness
- Several baselines are training-free while VideoNSA is fine-tuned; there is no apples-to-apples comparison where competing sparse/compression methods are similarly fine-tuned on the same data/budget.
- Retrieval-augmented or memory-augmented video systems are not compared; unclear whether NSA is complementary or competitive with external memory/retrieval.
- Streaming and real-time operation
- Causal streaming and online inference (chunked video arrival) are not evaluated; it is unclear how NSA’s branches and gating adapt to streaming constraints and whether attention budget can remain bounded online.
- Latency under interactive, multi-turn dialogues with interleaved video-text inputs is not analyzed; text remains dense GQA, raising questions for long conversational contexts.
- Attention sinks and interpretability
- While sink analysis shows CMP-induced sinks and low overall sink ratio, there is no intervention method (regularizers, gate penalties, norm stabilization) or ablation demonstrating that reducing sinks improves accuracy.
- Thresholds for sink detection are fixed; sensitivity of conclusions to the sink criterion and its correlation with task metrics is untested.
- Query-conditioned interpretability: how question wording modulates gating/branch usage and whether misrouting explains certain failure modes is not explored.
- Vision encoder and tokenization
- The choice and training policy of the vision encoder are not deeply ablated (frozen vs. fine-tuned stages, tokenization granularity, patch size); the impact on spatial fidelity and long-range reasoning remains uncertain.
- The per-frame pixel cap (50,176) and 64 tokens-per-frame may constrain high-frequency details; no study on multi-resolution or foveated tokenization integrated with NSA.
- Robustness, safety, and bias
- No robustness tests against adversarial frame insertions, time-warping, or targeted occlusions to probe NSA’s sparsity patterns.
- Bias, fairness, and safety are acknowledged but not measured quantitatively for video-specific harms (e.g., demographic bias in human-centric videos, surveillance misuse risks).
- Training strategy and objectives
- The training objective and schedule (e.g., curriculum on context length, auxiliary gating losses, latency-aware training) are not described; it is unclear if explicit compute-aware objectives could improve budget adherence and stability.
- Sample efficiency and compute–performance trade-offs are not studied (4600 H100 hours reported, but no scaling curve vs. compute).
- Quantization and deployment
- VideoNSA is not evaluated under quantization (e.g., AWQ, GPTQ); effects of quantization on gates, branch selection, and sinks are unknown.
- Compatibility with KV cache offloading/paging and CPU–GPU heterogeneous inference is not addressed.
- Downstream integration
- No exploration of combining NSA with retrieval, external memory, or hierarchical summarization for even longer videos.
- Interaction with LoRA/adapters or parameter-efficient tuning (e.g., adapting gates only) is not evaluated, which could be crucial for resource-constrained training.
- Reproducibility details still needed
- Some critical hyperparameters (e.g., saliency scoring details, gating initialization, optimizer schedules per module) are deferred to appendices; a minimal recipe for practitioners to re-train on new domains is not distilled.
- Variance across random seeds and statistical significance for benchmark gains are not reported.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can leverage the released model, code, and training recipe to deliver value now. Each item includes the primary sector, suggested tools/products/workflows, and feasibility notes.
- Media and entertainment: long-form video Q&A, chapterization, and highlight extraction for broadcasts and streaming platforms
- Tools/products/workflows: “Jump-to-moment” API backed by VideoNSA; automatic chapter generation and time-stamped summaries for sports, news, and documentaries; editorial copilot for post-production
- Assumptions/dependencies: GPU-backed inference (e.g., A100/H100-class), integration with content management systems, domain prompts; optimal token budget allocation depends on content type (e.g., more tokens-per-frame for visual detail vs. more frames for timeline coverage)
- Sports analytics: automated identification of decisive plays and sequences with temporal reasoning across full matches
- Tools/products/workflows: analyst dashboard with timeline Q&A; training/coaching assistant that surfaces missed tackles, assists, defensive transitions; ingest-and-index pipeline using VideoNSA’s dynamic gating
- Assumptions/dependencies: domain fine-tuning for sport-specific cues; broadcast-grade video feeds; adherence to privacy/league policies
- Security and surveillance operations: triage of hours-long CCTV footage with low compute cost
- Tools/products/workflows: SOC triage assistant; “incident-to-timeline” report generator; event search with time-stamped snippets; local window attention for rolling coverage plus selection/compression to keep global context salient
- Assumptions/dependencies: privacy and regulatory controls; integration with existing detection models; optimal attention budget ratios tuned to facility operations
- Retail operations: compliance and store performance auditing from long in-store camera streams
- Tools/products/workflows: shelf-stocking and queue monitoring summaries; “store shift recap” generation; anomaly detection with temporal rationale
- Assumptions/dependencies: domain prompts for retail tasks; video retention policies; edge/cloud deployment trade-offs
- Education: lecture capture summarization and interactive Q&A that spans full courses or multi-hour sessions
- Tools/products/workflows: LMS plugin for chapterization, “Ask my lecture” assistant with timestamped answers; search and retrieval across multi-session videos
- Assumptions/dependencies: institutional data governance; domain-specific tuning for lecture formats; attention allocation tuned for high temporal coverage
- Corporate compliance and meeting intelligence: minutes generation and decision tracing from long meetings
- Tools/products/workflows: “Executive recap” generator with time-stamped decisions; compliance checks across multi-hour sessions; keyword-to-moment finder
- Assumptions/dependencies: sensitive data handling; hybrid text-dense + video-sparse attention is already supported by the architecture
- Industrial inspection (manufacturing, infrastructure): UAV/robot inspection video summarization over long missions
- Tools/products/workflows: inspection timeline builder for pipelines, wind turbines, power lines; anomaly roll-up with spatial fidelity metrics (VSIBench-like)
- Assumptions/dependencies: domain fine-tuning on inspection videos; integration with existing NDE/NDT workflows; GPU availability at ingestion nodes
- Healthcare (non-diagnostic): surgical video review and skill assessment summaries, procedure step extraction
- Tools/products/workflows: “Procedure timeline” with key moments; resident training analytics; timestamped event catalogs
- Assumptions/dependencies: clinical data access and IRB/ethics approvals; domain fine-tuning; not intended for diagnostic use without extensive validation
- Legal and eDiscovery: time-stamped reasoning over deposition or incident videos
- Tools/products/workflows: “Moment-of-interest” extractor; long-form Q&A across multi-hour footage; evidentiary timeline generation with citations
- Assumptions/dependencies: strict chain-of-custody; audit logs; conservative attention budget to balance accuracy and cost
- Content moderation: scalable long-video policy violation detection with explainable temporal rationale
- Tools/products/workflows: moderator console that surfaces suspicious segments and provides time-linked justifications; hybrid local-global coverage
- Assumptions/dependencies: policy-specific finetuning; fairness/bias checks; operational review of false positives
- Daily life and prosumer: personal media and home security video summarization
- Tools/products/workflows: “Day-in-video” recap app; dashcam multi-hour trip summarizer; home camera event indexing and Q&A
- Assumptions/dependencies: cloud GPU or high-end local hardware; privacy preferences; budget-sensitive attention allocation
- Software and developer tooling: long-video RAG indexing and APIs for apps
- Tools/products/workflows: SDK to index time-stamped embeddings; VideoNSA-backed Q&A endpoints; plug-ins for video CMS and knowledge bases
- Assumptions/dependencies: adopt the released GitHub/Hugging Face model; Triton/FLA kernels for NSA; token-per-frame and fps trade-offs chosen per use case
Long-Term Applications
Below are forward-looking applications that become practical with further research, optimization, domain-specific tuning, or scaling.
- Real-time streaming NSA at the edge: live long-horizon video understanding on constrained hardware
- Tools/products/workflows: embedded inference with Flash Sparse/FLA kernels; kernel-level optimization of the compression branch (current bottleneck); adaptive gating for streaming inputs
- Assumptions/dependencies: improved kernels and memory locality; hardware accelerators or ASICs; attention budget auto-tuning
- Autonomous driving and ADAS: long-horizon temporal reasoning across multi-camera feeds
- Tools/products/workflows: “long-memory planner assistant” that recalls events minutes/hours back; safety event chain extraction; integration with perception stacks
- Assumptions/dependencies: real-time guarantees; rigorous safety validation; domain training on driving datasets; multi-sensor fusion
- Robotics (field, household, industrial): persistent video memory for decision-making
- Tools/products/workflows: robot “situational diary” indexed by tasks; recovery of rare events; global-local attention tuned per robot mission
- Assumptions/dependencies: tight integration with control loops; latency bounds; gating policies adapted to robotic tasks
- Smart grid and energy operations: facility and equipment monitoring across long windows
- Tools/products/workflows: plant operations recap; incident correlation across video and logs; turbine/pipeline long-term trend reasoning
- Assumptions/dependencies: coupling with SCADA data; domain-specific finetuning; governance for critical infrastructure
- Finance and trading floor compliance: surveillance analytics with cross-hour reasoning and transparent audit trails
- Tools/products/workflows: regulator-ready reports; time-stamped event linkage; explanation of decisions via learned sparse gates
- Assumptions/dependencies: strict privacy and compliance regimes; curated datasets; bias and fairness audits
- Healthcare (clinical decision support): real-time OR assistance and safety alerts based on procedure context
- Tools/products/workflows: in-the-loop alerts (e.g., instrument count anomalies, step deviations); long-form procedural memory for post-op reviews
- Assumptions/dependencies: medical-grade reliability; FDA/CE approvals; multimodal fusion with sensor data; extensive clinical validation
- Large-scale content moderation at platform level: continuous long-stream monitoring with explainability
- Tools/products/workflows: platform-wide “temporal policy engine” that uses optimal global-local attention allocation; auditability via gate distributions and sink diagnostics
- Assumptions/dependencies: scalable infrastructure; policy calibration; sink behavior monitoring to avoid systematic bias
- Generative video systems: long-context conditioning for coherent multi-hour generation
- Tools/products/workflows: combine VideoNSA-style sparse attention with “mixture of contexts” for generation control; editor co-pilots for story continuity
- Assumptions/dependencies: integration with long-video generation models; compute budgets; training datasets for narrative continuity
- Academic research infrastructure: foundation for studying attention sinks, dynamic gating, and long-context scaling in multimodal models
- Tools/products/workflows: open benchmarks with ultra-long sequences; visualizations of gate distributions and sink positions; reproducible training/inference pipelines
- Assumptions/dependencies: community adoption; standardized evaluation protocols; cross-model comparisons
- Policy and governance: standards for long-video analytics, transparency, and privacy
- Tools/products/workflows: attention-budget reporting standards; explainability via gate weights; audit logs for sparse routing decisions
- Assumptions/dependencies: collaboration with regulators; sector-specific policies; impact assessments
- Enterprise knowledge management: multi-quarter video knowledge bases built from trainings, town halls, and operations footage
- Tools/products/workflows: enterprise video RAG with time-linked citations; role-based search and Q&A; auto-chaptering and highlights across series
- Assumptions/dependencies: access control and governance; multi-lingual support; domain-specific prompts and finetuning
- Hardware/software co-design: specialized kernels and accelerators for sparse branches, especially compression
- Tools/products/workflows: kernel fusion for block compression; memory-aware cache layouts; programmable sparsity controllers
- Assumptions/dependencies: vendor collaboration (CUDA/Triton/Flash Sparse); benchmarking at 128K+ contexts; proof of throughput gains
Cross-cutting implementation guidance and feasibility notes
- Attention allocation matters: the optimal global-local ratio is task-dependent (e.g., temporal coverage for TimeScope/Tomato vs. higher tokens-per-frame for LongVideoBench). Expect to tune block count, block size, and sliding window width for each domain.
- Cost-efficiency: VideoNSA achieves leading performance with about 3.6% of full attention, enabling long-context applications at lower cost. However, the compression branch is the runtime bottleneck; kernel optimization improves latency.
- Robustness/transfer: sparse-trained weights can benefit dense attention, but runtime sparsity and dynamic gating provide most gains. Domain finetuning is recommended for specialized tasks (surgery, driving, finance).
- Infrastructure dependencies: GPU-class hardware, NSA kernels (FLA/Triton/Flash Sparse), and long-context KV management are needed. Integration with existing video ingestion and CMS pipelines is straightforward via the released GitHub/Hugging Face artifacts.
- Ethics and governance: long-video understanding amplifies privacy and fairness considerations. Incorporate audit logs, bias testing, and policy-aligned prompts before deployment in regulated settings.
Glossary
- Attention Budget: The total number of key-value pairs visible to each query, used to quantify available attention computation. "We define the Attention Budget as the total number of key-value pairs visible to each query, denoted by ."
- Attention Sink: Tokens that absorb disproportionately high attention mass but contribute little due to small value norms. "In decoder-only transformers, a disproportionate amount of attention is often allocated to the first few tokens, which act as attention sinks and absorb excessive attention mass as a byproduct of softmax normalization."
- Block-level representation: A summarized token representation for a block (e.g., a frame), often obtained by averaging tokens within the block. "We set the block size equal to the token number per frame, and obtain the block-level representation by averaging all tokens within the block."
- Causal dense attention: Full attention over all preceding tokens in a sequence, yielding quadratic edge count. "With context length , compared to causal dense attention with edges, the fraction of attention used is"
- Data-dependent sparse connectivity: Sparsity patterns in attention that adapt based on input content rather than being fixed. "We conduct end-to-end training to adapt vision features for data-dependent sparse connectivity in the LLM."
- Dynamic gating: Learnable routing that weights multiple attention branches per query to combine their outputs. "The outputs are combined through dynamic gating before integration with text tokens for LLM decoding."
- FlashAttention: A hardware-optimized dense attention kernel that accelerates computation and memory usage. "Our primary baseline is Qwen2.5-VL-7B~{qwen2025qwen25technicalreport} with dense FlashAttention~{dao2023flashattention}."
- Gating distribution: The pattern of learned gate weights across layers or heads that controls branch usage. "The gating distribution evolves dynamically across layers, and the selection and sliding-window branches gradually lose importance in deeper layers."
- Grouped-Query Attention (GQA): An attention variant where multiple query heads share fewer key/value heads to reduce KV cache size. "Grouped-Query Attention (GQA)~{ainslie2023gqa} mitigates this by letting multiple query heads share fewer KV heads."
- Hardware-aware sparse attention: Sparse attention designs aligned with hardware characteristics to improve efficiency and scalability. "We propose~VideoNSA, a hardware-aware native sparse attention mechanism, and systematically investigate its effectiveness for video understanding, scaling up to a 128K vision context length."
- Inductive bias: Built-in preferences in learned parameters that guide models toward more effective behaviors. "sparse-trained weights provides inductive bias towards more effective attention distributions."
- Inter-head similarity: A measure of how similar gate or attention patterns are across different heads within a layer. "Inter-head similarities of gates in~VideoNSA. Selection and sliding-window gates show high similarity in middle layers."
- Key–Value (KV) cache: Stored keys and values from previous timesteps used to compute attention efficiently during inference. "NSA dynamically constructs an information-dense KV cache subset."
- Native Sparse Attention (NSA): A learnable, hardware-aligned sparse attention mechanism that builds task-relevant KV subsets per query. "Native Sparse Attention~{yuan2025native} (NSA) avoids computing attention between all key-value pairs , instead, for each query , NSA dynamically constructs an information-dense KV cache subset."
- Prefilling stage: The initial inference phase where long input sequences are processed to populate the KV cache. "VideoNSA utilizes three sparse attention branches during prefilling stage: compression branch reduces redundancy via token averaging, selection branch identifies top-k important tokens, and sliding window branch enforces local temporal coverage."
- Sliding window attention: Local attention that keeps a fixed window of the most recent tokens for each query. "Sliding Window (SWA) branch simply applies the standard sliding window attention, which retains the fixed most recent key-value pairs:"
- Sliding-window width: The number of recent tokens retained in local attention for each query. "and is the sliding-window width."
- Token Compression (CMP): A branch that merges sequential token blocks into coarser representations to reduce redundancy. "Token Compression (CMP) branch aggregates sequential blocks of keys into more coarse-grained, single block-level representations"
- Token Selection (SLC): A branch that selects the most salient token blocks via importance scoring to retain only top-ranked information. "Token Selection (SLC) branch preserves the most salient key-value blocks by computing importance scores"
- Top-k block filtering mechanism: A selection strategy that keeps only the k most important blocks according to learned scores. "the selection branch yields almost no sinks, as its top- block filtering mechanism enforces a smoother value norm distribution."
- Value norm: The magnitude of a value vector associated with a token, often used to diagnose attention sink behavior. "where is the average attention score received by the key, and is the value norm of the token."
- Wall-clock time: Real elapsed time measured during runtime to assess latency and performance. "We measure the inference latency of each branch in~VideoNSA using wall-clock time across varying context lengths from $1K$ to $128K$."
Collections
Sign up for free to add this paper to one or more collections.

