- The paper demonstrates that minimal rank-1 LoRAs can recover 73-90% of reasoning performance compared to full fine-tuning on the Qwen-2.5-32B-Instruct model.
- It employs a novel methodology that uses sparse autoencoders to compare interpretable LoRA activations with traditional MLP neuron activations.
- Ablation studies highlight that later MLP layers, especially those involving gate_proj matrices, are critical for preserving reasoning capabilities.
Rank-1 LoRAs Encode Interpretable Reasoning Signals
Introduction
The study "Rank-1 LoRAs Encode Interpretable Reasoning Signals" examines the capability of minimal parameter modifications, specifically rank-1 Low-Rank Adaptations (LoRAs), to embody reasoning capabilities in LLMs. Recent advancements in LLMs have pivoted towards reasoning models that utilize inference-time compute to enhance performance on logic-intensive tasks. Despite their efficacy, a comprehensive understanding of the mechanisms behind these improvements remains elusive. This paper posits that minimal changes via rank-1 LoRAs can recover substantial reasoning performance while maintaining interpretability of those changes.
Methodology
The research employs a rank-1 LoRA on the Qwen-2.5-32B-Instruct model, showing that this can restore 73-90% of the reasoning benchmark performance relative to a complete parameter fine-tune. These LoRAs modify the model minimally, each consisting of a rank-1 adaptation of certain matrices in the model's architecture. The paper outlines the parameter-efficient training methodology and its application, highlighting that the LoRA components are as interpretable as MLP neurons, specifically firing for reasoning-specific behaviors.
Analysis of Interpretability
A major contribution of this work is the analysis of the interpretability of the activations induced by the LoRA. The study uses LoRA activations as probes, comparing them to MLP neuron activations. It finds that LoRA activations tend to match or exceed the monosemantic qualities of MLP neurons. These findings are reinforced by the training of a sparse autoencoder on the LoRA activation states, which allows for a fine-grained identification of monosemantic features.

Figure 1: Comparison of interpretability scores of individual LoRA adapter activations to arbitrarily sampled MLP neurons, highlighting LoRAs' monosemantic activation propensity.
Additionally, the study categorizes these features, observing that the LoRA activations often correspond to reasoning-specific functions, such as procedural and mathematical reasoning markers.
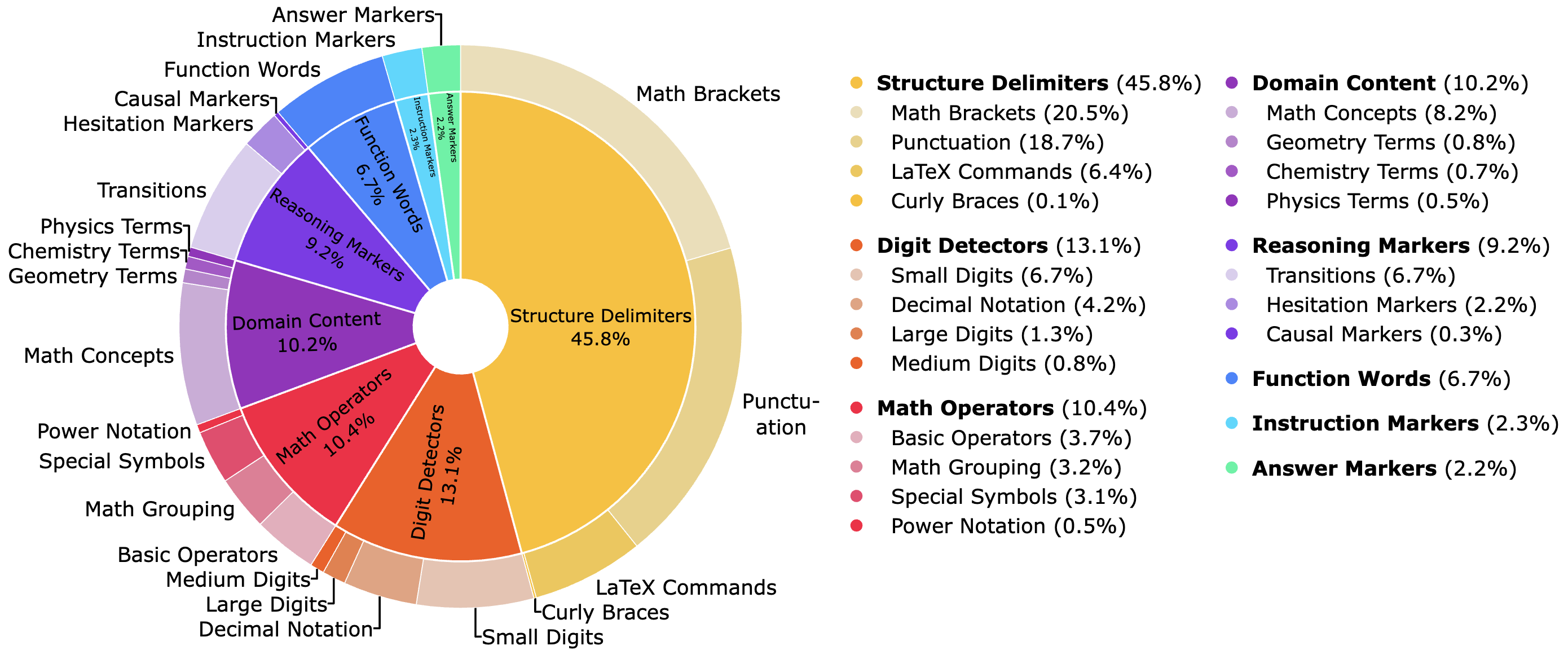
Figure 2: Overview of feature categories learned by an SAE trained on LoRA activation states, indicating relative feature activation densities.
Ablation Studies
The paper conducts ablation studies to pinpoint which components of the LoRA most significantly affect performance. By systematically deactivating individual components, the research highlights the critical role of mid-to-late MLP layers, specifically those trained on gate_proj matrices, in driving performance.
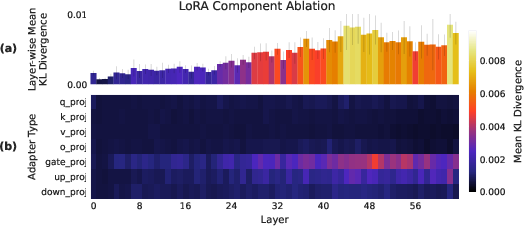
Figure 3: Effect of ablating individual LoRA components from the full adapter, illustrating the importance of certain layers and components.
The results indicate that MLP adapters, especially those in later layers, have the most profound impact on maintaining the model's output distribution and reasoning capabilities.
Conclusion
This study demonstrates that rank-1 LoRAs can effectively embed reasoning capabilities within LLMs, making these changes interpretable and specific. The implications are profound, suggesting that minimal, interpretable parameter alterations can significantly enhance model functions without the need for extensive fine-tuning. This approach not only provides insights into the internal mechanisms of reasoning models but also paves the way for utilizing parameter-efficient methods in understanding and optimizing LLMs.
Future work may explore expanding these methods to other types of models and applications, potentially unraveling new dynamics and capabilities that are currently obscured by extensive model complexity.

