- The paper reveals that LoRA introduces intruder dimensions in weight matrices, fundamentally differing from the structural changes seen in full fine-tuning.
- It demonstrates that although LoRA reduces forgetting in isolated tasks, cumulative intruder effects impair continual learning performance.
- The study highlights that parameter settings such as rank and scaling factors are critical for balancing generalization and stability in model adaptation.
LoRA vs Full Fine-tuning: An Illusion of Equivalence
Introduction and Overview
The paper "LoRA vs Full Fine-tuning: An Illusion of Equivalence" explores the practical implications of Low-Rank Adaptation (LoRA) compared to full fine-tuning on LLMs. It argues that despite LoRA's efficiency in reducing trainable parameters, its solutions are structurally different from those derived through full fine-tuning. Specifically, LoRA introduces "intruder dimensions" in the weight matrices which do not appear in full fine-tuning. The study provides insights into how these differences impact model forgetting and performance within continual learning frameworks.
Structural Differences Between LoRA and Full Fine-tuning
LoRA and full fine-tuning produce distinct alterations to the pre-trained weights, as evidenced by the singular value decomposition (SVD) of their weight matrices. LoRA introduces intruder dimensions, which are high-ranking singular vectors that do not align with pre-trained vectors, while full fine-tuning maintains spectral properties closer to the original pre-trained model.
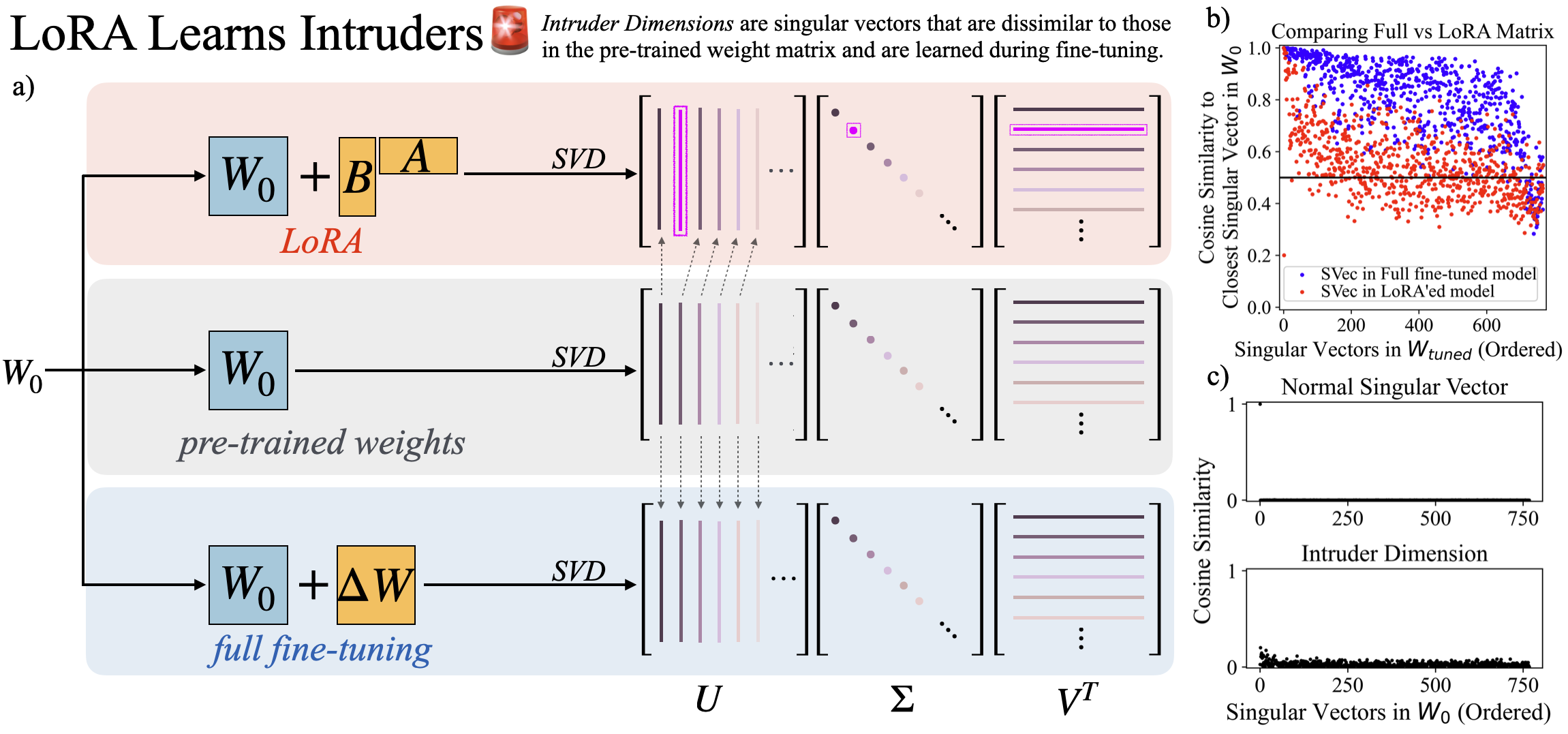
Figure 1: Characterizing structural differences between solutions learnt by LoRA versus Full Fine-tuning.
The paper introduces an algorithm to quantify these intruder dimensions, illustrating that their presence is significant in LoRA models especially as the rank increases, yet decreases when the rank surpasses a certain threshold. The introduction and accumulation of intruder dimensions are directly linked to the model's learning rate and dimension rank settings.
Forgetting and Out-of-Distribution (OOD) Generalization
LoRA models typically experience less forgetting than full fine-tuning models when evaluating performance across unrelated tasks or on samples from the pre-training distribution. However, the presence of intruder dimensions adversely affects out-of-distribution generalization. It is demonstrated that these dimensions are responsible for not just increased forgetting but also for modulating model performance when scaled.
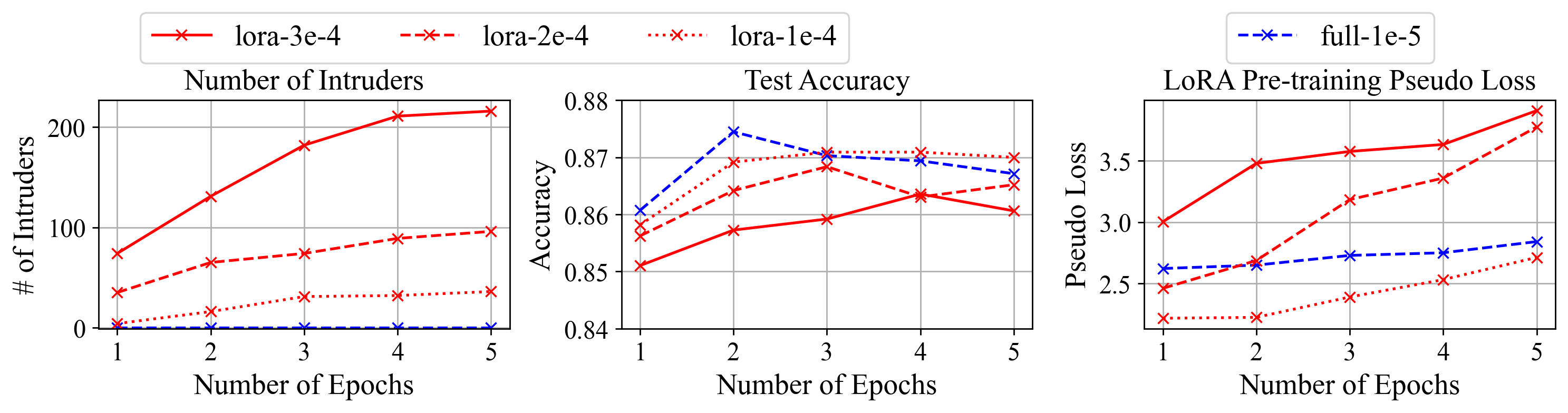
Figure 2: As training progresses, models with intruder dimensions demonstrate more forgetting despite non-increasing test performance.
The study further examines the effect of the scaling factor α on LoRA's generalization capabilities, highlighting the critical nature of this parameter in maintaining balanced intruder dimensions and mitigating forgetting effects.
Continual Learning and Practical Implications
Intruder dimensions' impact is particularly pronounced in continual learning scenarios. LoRA models, despite showing less forgetting in isolated tasks, degrade quickly in a continual learning setup due to cumulative intruder dimensions across tasks, as demonstrated in the sequential task experiments.
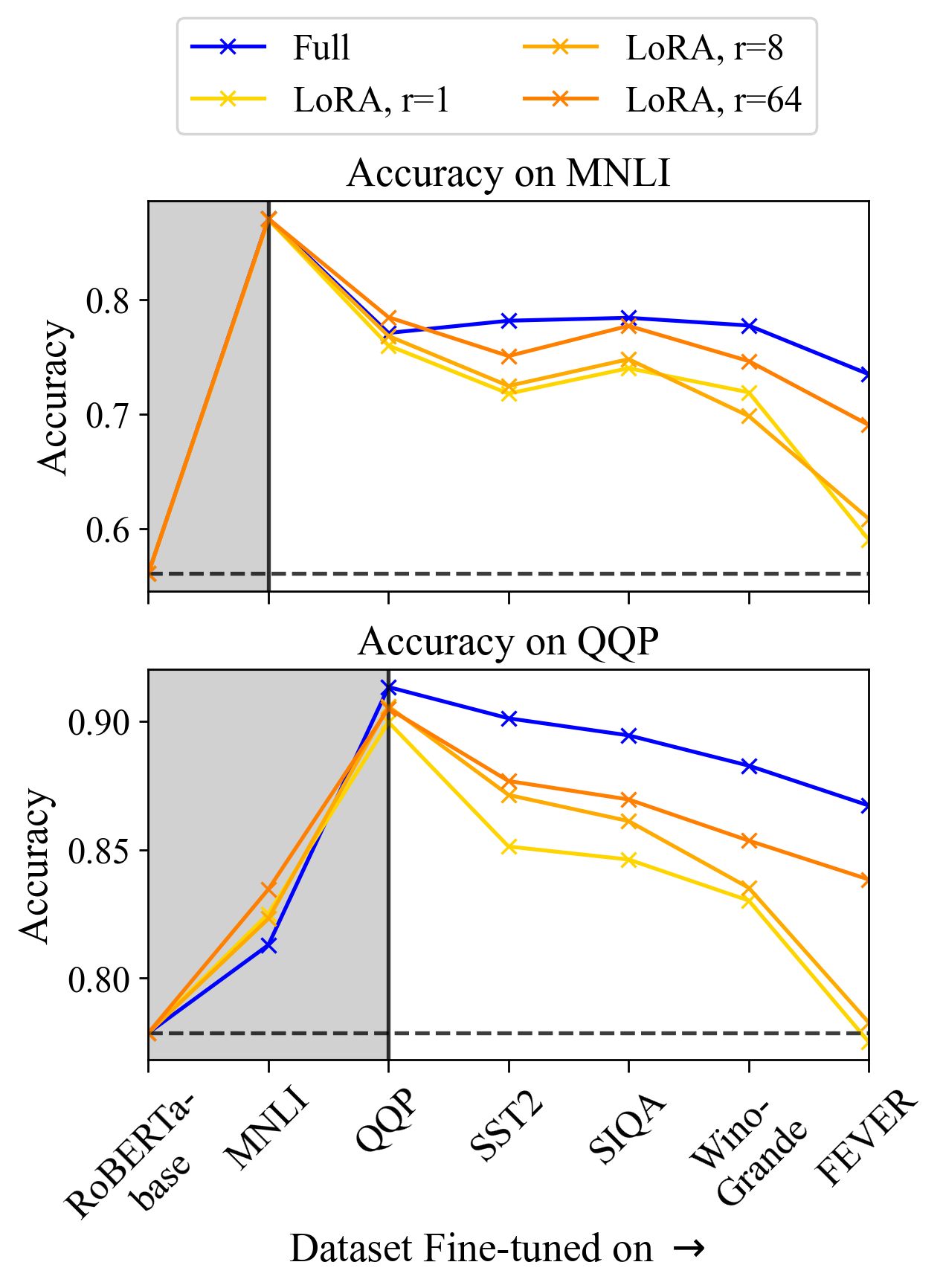
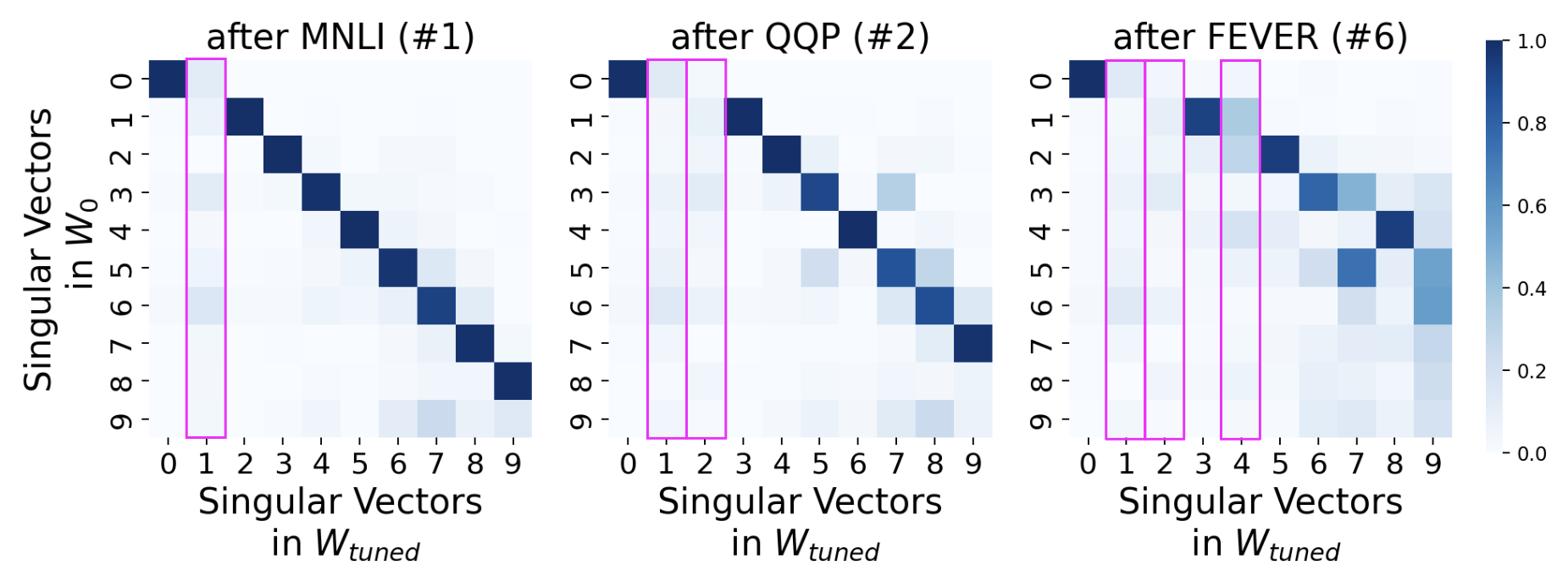
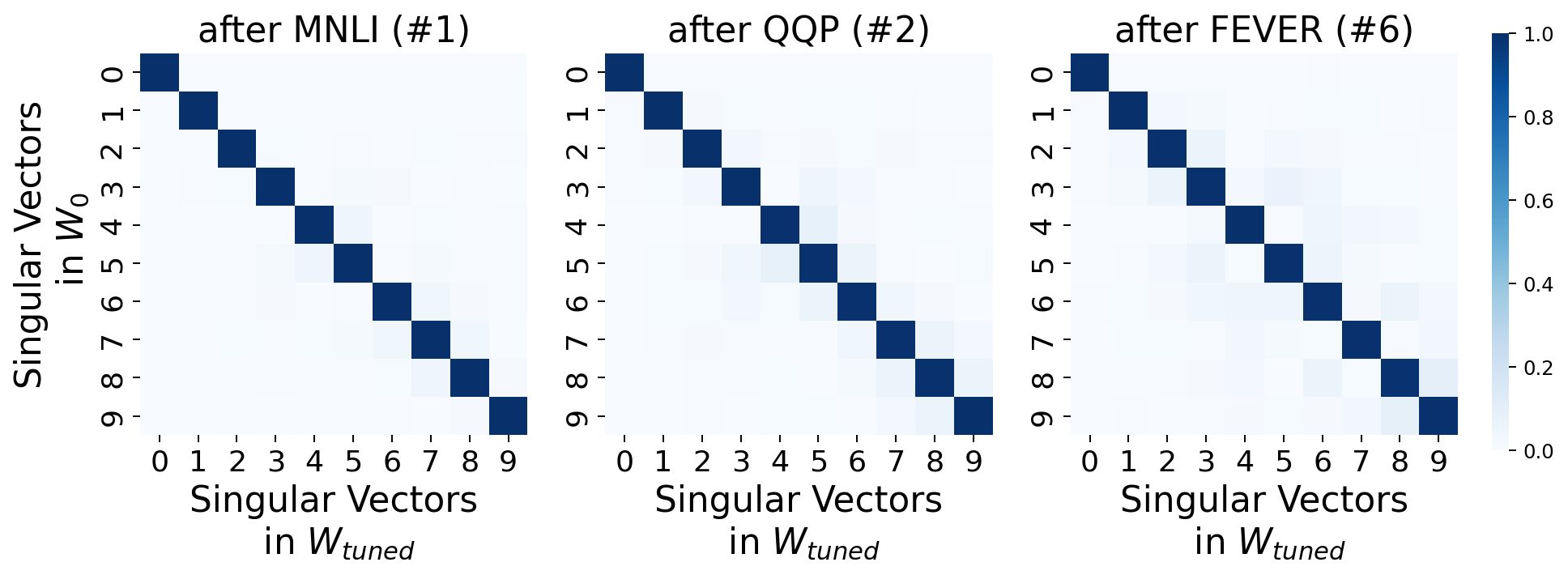
Figure 3: Continual learning results indicate the cumulative impact of intruder dimensions on model performance.
The accumulation of intruder dimensions leads to noticeable performance drops in previously learned tasks, underlining the importance of addressing this aspect in setups requiring prolonged learning and adaptation.
Conclusion
The paper concludes that LoRA's solution spaces differ structurally from full fine-tuning, primarily due to the introduction of intruder dimensions which can detrimentally impact the model's out-of-distribution generalization and forgetting characteristics. These findings suggest that while LoRA provides computational advantages, careful consideration must be given to its parameter settings to optimize model stability and performance in diverse deployment scenarios.
This study's insights into the behavior of LoRA and full fine-tuning contribute significantly to the understanding of parameter-efficient learning methodologies, emphasizing the need for optimized adaptation strategies in applied AI settings.