Inverse Knowledge Search over Verifiable Reasoning: Synthesizing a Scientific Encyclopedia from a Long Chains-of-Thought Knowledge Base
Abstract: Most scientific materials compress reasoning, presenting conclusions while omitting the derivational chains that justify them. This compression hinders verification by lacking explicit, step-wise justifications and inhibits cross-domain links by collapsing the very pathways that establish the logical and causal connections between concepts. We introduce a scalable framework that decompresses scientific reasoning, constructing a verifiable Long Chain-of-Thought (LCoT) knowledge base and projecting it into an emergent encyclopedia, SciencePedia. Our pipeline operationalizes an endpoint-driven, reductionist strategy: a Socratic agent, guided by a curriculum of around 200 courses, generates approximately 3 million first-principles questions. To ensure high fidelity, multiple independent solver models generate LCoTs, which are then rigorously filtered by prompt sanitization and cross-model answer consensus, retaining only those with verifiable endpoints. This verified corpus powers the Brainstorm Search Engine, which performs inverse knowledge search -- retrieving diverse, first-principles derivations that culminate in a target concept. This engine, in turn, feeds the Plato synthesizer, which narrates these verified chains into coherent articles. The initial SciencePedia comprises approximately 200,000 fine-grained entries spanning mathematics, physics, chemistry, biology, engineering, and computation. In evaluations across six disciplines, Plato-synthesized articles (conditioned on retrieved LCoTs) exhibit substantially higher knowledge-point density and significantly lower factual error rates than an equally-prompted baseline without retrieval (as judged by an external LLM). Built on this verifiable LCoT knowledge base, this reasoning-centric approach enables trustworthy, cross-domain scientific synthesis at scale and establishes the foundation for an ever-expanding encyclopedia.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
Think about most school textbooks or Wikipedia pages: they tell you the final answers, but they rarely show every step that got there. This paper tries to fix that. The authors build a huge collection of step‑by‑step explanations (like showing your work in math) and use it to create a new kind of science encyclopedia that focuses on how and why ideas work, not just what they are.
They call the hidden web of missing steps the “dark matter” of knowledge—like the invisible stuff in space that holds galaxies together, these missing steps hold scientific ideas together. Their goal is to make this “dark matter” visible, checkable, and searchable.
What questions the paper tries to answer
- Can we build a giant, trustworthy library of step‑by‑step reasoning that ends with answers we can actually check?
- Can we search this library “backwards”—start with a concept (like gravity or enzymes) and find different paths that logically lead to it?
- If we write encyclopedia articles using these verified steps, will they be clearer, contain more real knowledge, and have fewer mistakes than articles written by an AI without this support?
How they did it (explained with everyday ideas)
The project has three big parts. You can think of them like a careful group project with planners, problem creators, solvers, and writers:
- Building the “show your work” library (the LCoT knowledge base)
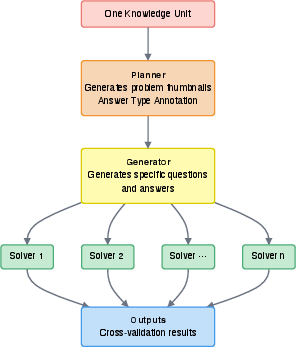
- Step 1: Pick goals. They collected about 200 real university courses and listed the important topics in each. These are the “endpoints,” like recipe names (e.g., “What is an electric field?” or “How does natural selection work?”).
- Step 2: Ask first‑principles questions. A “Socratic” agent (think: a super-curious tutor) generated about 3 million questions that force step‑by‑step reasoning from basics. Example: instead of “What is the answer?” it asks “Using Newton’s laws, show how we get the formula for orbit speed.”
- Step 3: Get multiple solutions. Several different AI models solved each question, writing out long chains of thought (LCoTs = Long Chains of Thought), like detailed math worked out line by line.
- Step 4: Keep only what’s checkable and agreed on. They:
- Clean bad questions (prompt sanitization) so the starting point isn’t flawed.
- Prefer questions with answers you can verify (like a number, a formula, a unit test in code, or a correct choice).
- Compare answers across different AIs and keep the ones where the models independently agree. This is like asking several teachers and trusting the answer only if they all match.
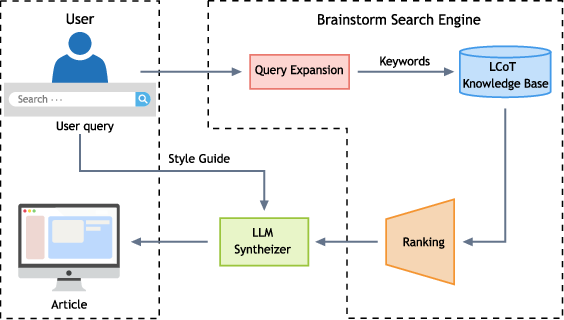
- Searching “backwards” (the Brainstorm Search Engine)
- Usual search engines find facts; this one finds the paths. You type a concept (say “instantons” or “ecosystem stability”), and it retrieves many verified step‑by‑step chains that end at that concept. It’s like starting with a finished cake and finding all the reliable recipes that could have made it.
- Writing clear articles (the Plato agent) and the new encyclopedia (SciencePedia)
- The Plato agent is a careful writer. It doesn’t make things up freely; it uses the verified chains as a scaffold (like building on sturdy beams) to write easy‑to‑read, low‑error articles.
- SciencePedia is the result: about 200,000 focused entries across math, physics, chemistry, biology, engineering, and computing, created from these verified reasoning chains.
Helpful analogies for the technical parts:
- Long Chain‑of‑Thought (LCoT): showing every step in your homework so anyone can follow and check it.
- Verifiable endpoint: an answer you can prove is right (the number matches, the code passes a test, the formula is correct).
- Cross‑model validation: multiple independent AIs agree on the same final answer—less chance it’s a lucky guess.
- Inverse search: start with the idea you care about and trace backward to find different solid ways to reach it.
What they found and why it matters
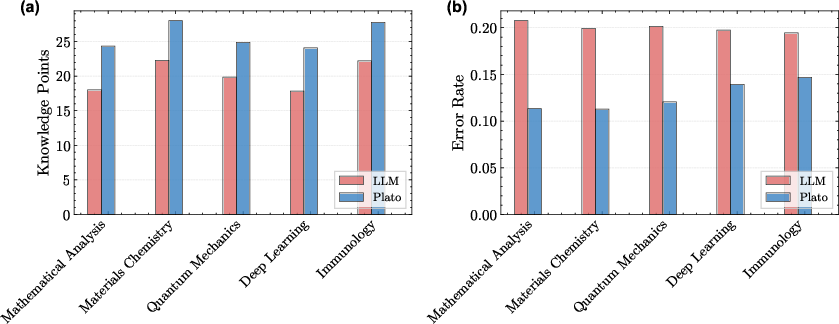
- More real knowledge, fewer mistakes: When the Plato writer used the verified reasoning chains, the articles:
- Contained more actual “learnable facts and insights” per page (higher knowledge density).
- Had far fewer factual errors (about 50% fewer hallucinations) compared to a strong AI that wrote without using the verified chains.
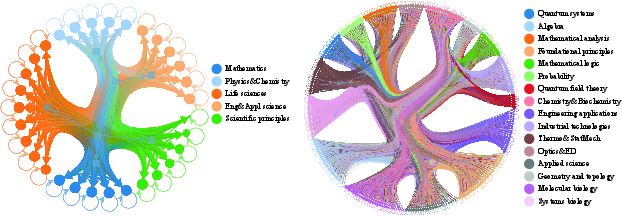
- Strong cross‑discipline links: By analyzing the connections between topics, they found lots of meaningful links across fields (for example, a physics idea turning up in math and even in computer science). This supports their claim that the missing “dark matter” steps help reveal how fields connect.
- Scale and coverage: They built around 3 million first‑principles questions and about 200,000 encyclopedia entries—big enough to be useful across many science areas.
Why this could be a big deal
- Trustworthy learning: Students, teachers, and researchers can see not just what is true, but why—step by step. That builds trust and makes checking easier.
- Discovery through connections: Because the system shows the paths between ideas, it helps people spot surprising links between fields—useful for creativity and new research.
- A foundation to grow: This AI‑built base solves the “cold start” problem of creating a huge encyclopedia. Next, human experts can refine it, add history and new research, and fix any errors.
- Future directions:
- Add textbooks and peer‑reviewed papers to keep the knowledge up to date.
- Work toward a more formal, machine‑readable map of knowledge so computers can help prove things and discover new results.
In short, this paper shows a new way to build science knowledge: collect verified, step‑by‑step reasoning at scale, search it in reverse to find how ideas are built, and write clearer, more accurate articles from those steps. It’s like turning the world’s science notes from “final answers only” into “answers plus the full, checkable path,” and that can change how we learn and discover.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of concrete gaps and unresolved issues that future research could address.
Verification and reliability
- Step-level validity is not checked: the pipeline verifies only final endpoints; intermediate LCoT steps can be logically flawed yet yield correct answers. Develop automated step-by-step checkers (e.g., CAS-assisted algebra, unit checks, formal proof checkers, code execution harnesses).
- Cross-model consensus may be correlated: “independent” LLMs likely share pretraining data and inductive biases. Quantify effective independence, measure error correlation, and explore orthogonalization strategies (e.g., different architectures, training data partitions, reasoning styles).
- Verifiability bias: the system prefers questions with checkable endpoints, potentially excluding qualitative, conceptual, or open-ended scientific knowledge. Design verification proxies for non-numeric, non-symbolic content (e.g., entailment chains, citation-backed claims, fact graphs).
- Adversarial robustness is untested: no analysis of failure modes for adversarial prompts or perturbations that preserve endpoints but corrupt reasoning. Create adversarial test suites targeting spurious shortcuts and reasoning shortcuts.
- Provenance and justification are opaque: LCoTs lack explicit source citations to primary literature. Add citation grounding (retrieval + citation alignment) and confidence scores per step.
Coverage, scope, and representativeness
- Curriculum bias and completeness are unclear: selection of ~200 courses and ~200 topics per course may systematically omit subfields or non-Western/Eastern curricula. Audit coverage diversity, add curriculum expansion protocols, and introduce community-driven gap-filling workflows.
- Domain limitations: current focus on STEM; limited or absent handling of domains where first principles are less formalized (e.g., social sciences, medicine). Devise domain-specific verification and reasoning templates for non-STEM areas.
- Qualitative scientific history and context are underrepresented by design. Integrate history-of-science corpora with tailored verification (e.g., citation triangulation, temporal consistency).
Evaluation methodology
- Reliance on an external LLM (“GPT-5”) for judging error rates and knowledge-point density risks circularity and bias. Replace or complement with expert human evaluations, blinded protocols, inter-rater agreement, and standardized rubrics.
- Metrics are under-specified: definitions of “knowledge-point density” and “factual error rate” are not operationalized for reproducibility. Publish formal metric definitions, annotation schemas, and evaluation datasets.
- Limited benchmarking scope: evaluations across six disciplines lack comparisons to established benchmarks and human-curated references. Expand to standardized reasoning/data synthesis benchmarks and conduct head-to-head comparisons with Wikipedia/encyclopedias.
Methodology and pipeline details
- RLVR assumptions are asserted, not empirically dissected: the paper posits a new distribution p_LLM for LCoTs without ablation studies, calibration curves, or distributional analyses. Provide quantitative evidence (length/depth distributions, novelty metrics, causality proxies).
- Solver diversity and configuration are unspecified: number, types, and versions of models, temperature settings, and sampling schemes are not disclosed. Release ablations on solver ensembles and sampling strategies vs. accuracy/coverage.
- Prompt sanitization efficacy is anecdotal (~5% filtered) with no error taxonomy. Publish a taxonomy of prompt errors, sanitization precision/recall, and failure cases.
- Reproducibility and versioning are unclear: LLM non-determinism, seed control, and model version drift can change outputs. Provide deterministic pipelines, metadata, hashes, and dataset snapshots.
Search and synthesis (Brainstorm + Plato)
- Ranking criteria are underspecified: “relevance and cross-disciplinary significance” lack measurable definitions. Develop transparent ranking features, training data, and evaluation against user relevance judgments.
- Entity linking and disambiguation are not formalized for “inverse search”: ambiguity in keywords (e.g., homonyms) may retrieve irrelevant LCoTs. Add canonical identifiers, entity linking, and disambiguation pipelines.
- Hallucination during narrative bridging remains possible: Plato may introduce unsupported claims between verified steps. Implement citation-aware generation, inline evidence pointers, and factuality critics.
- User-centered evaluation is missing: no studies on user comprehension, learning gains, or trust calibration when browsing LCoTs vs. compressed summaries. Run controlled user studies and A/B tests.
Encyclopedia construction and graph analysis
- Keyword extraction and link creation rely on LLM parsing without precision/recall validation. Benchmark extraction against expert annotations and introduce hybrid NLP + rule-based validators.
- Community detection validation is limited: MODBP outputs are not cross-validated with alternative methods or expert-curated taxonomies. Perform stability analyses, resolution limit checks, and expert audits of clusters.
- Conflict resolution is unspecified: handling contradictory LCoTs (same endpoint, divergent assumptions) is unclear. Introduce contradiction detection, assumption tracking, and versioned, side-by-side presentations.
Formalization and machine-readability
- Knowledge remains in natural language; formal graph/logic representation is future work. Develop parsers that lift LCoTs into formal languages (e.g., Lean/Isabelle, symbolic math, typed graphs), with soundness checks and traceable links back to text.
- Lack of compositional verification: no mechanism to compose verified sub-derivations into larger proofs. Explore modular proof composition and incremental verification caches.
Maintenance, scalability, and engineering
- Incremental updating is unspecified: integrating new LCoTs, model upgrades, and retracting errors requires version control and rollback mechanisms. Design continuous integration pipelines, semantic diffing for LCoTs, and deprecation policies.
- Compute, storage, and carbon costs are not reported. Provide cost analyses, efficiency ablations, and green AI strategies (e.g., distillation of solvers, caching, retrieval optimization).
- Deduplication and redundancy handling are unclear: near-duplicate LCoTs can inflate storage and bias ranking. Add semantic deduplication and canonicalization.
Ethics, safety, and legal considerations
- Safety in sensitive domains (e.g., bio, chemical engineering) is not addressed. Add content filters, dual-use risk assessments, and expert review gates.
- Licensing and IP: unclear rights to redistribute LLM-generated LCoTs and synthesized articles, and potential inadvertent reproduction of copyrighted text. Provide licensing policies, plagiarism detection, and provenance logs.
- Bias and fairness: no audit of sociotechnical biases (e.g., cultural/linguistic skew) in generated content and curricula. Conduct bias audits and mitigation strategies across languages and regions.
- Community governance is aspirational: concrete mechanisms for expert contributions, incentives, moderation, and dispute resolution are missing. Specify roles, workflows, and accountability frameworks.
Extension to non-verifiable or frontier knowledge
- Incorporating cutting-edge research with uncertain or non-replicated results is unresolved. Devise uncertainty labeling, claim stability tracking over time, and layered evidence grading.
- Handling inherently ambiguous or interpretive domains lacks methodology. Explore multi-perspective synthesis with explicit assumption framing and claim-attribution.
Practical Applications
Practical Applications Derived from the Paper’s Findings
Below, we translate the paper’s contributions—verifiable LCoT knowledge base, inverse knowledge search (Brainstorm), synthesis (Plato), and the emergent SciencePedia—into actionable applications across industry, academia, policy, and daily life. Each item notes sectors, possible tools/workflows, and assumptions or dependencies that affect feasibility.
Immediate Applications
These can be deployed now using the current framework (SciencePedia, Brainstorm Search Engine, Plato agent) and standard enterprise/educational tooling.
- SciencePedia as a high-reliability STEM reference
- Sector: Education, Academia
- Tools/workflows: Public SciencePedia pages, curriculum-linked portals, course dashboards pulling “What & Why” plus “Applications” sections
- Assumptions/dependencies: Coverage aligns with local curriculum; gaps in scientific history and frontier research due to LLM training cutoffs
- LCoT-grounded writing assistants for technical content
- Sector: Software, Engineering, Energy, Academia
- Tools/workflows: “Plato Writer” plugin for documentation platforms (Confluence, Notion), CMS-integrated synthesis fed by Brainstorm search; templated articles with explicit derivations
- Assumptions/dependencies: Availability of relevant LCoTs in the corpus; editorial review for domain-specific correctness
- Retrieval-augmented generation (RAG) with verifiable LCoTs to reduce hallucinations
- Sector: Software, AI products
- Tools/workflows: Brainstorm Search API integrated into AI assistants; RAG middleware that requires verifiable endpoints and cross-model consensus
- Assumptions/dependencies: Task designs include checkable endpoints; robust indexing and retrieval of LCoT QA pairs
- Technical onboarding and training with inverse knowledge search
- Sector: Industry (manufacturing, energy, robotics), Academia
- Tools/workflows: Role-specific “Reasoning Scaffold” packs (e.g., controls engineering, materials physics); LMS plugins exposing derivational pathways rather than just summaries
- Assumptions/dependencies: Mapping LCoTs to job competencies; localization for different standards and languages
- QA and design review checklists grounded in first-principles derivations
- Sector: Engineering, Energy, Aerospace
- Tools/workflows: “Reasoning Auditor” workflow where design decisions must reference LCoT chains with verifiable calculations/endpoints
- Assumptions/dependencies: Project artifacts must be linkable to verifiable endpoints (numerical/symbolic); human sign-off remains critical
- Cross-disciplinary research discovery and literature support
- Sector: Academia, R&D
- Tools/workflows: Brainstorm-driven “Discovery Map” that surfaces non-trivial links between topics (e.g., instantons across physics/maths); grant ideation using verified chains
- Assumptions/dependencies: Keyword graph quality; coverage of advanced topics varies by corpus
- Enterprise knowledge bases with internal SciencePedia clones
- Sector: Enterprise Knowledge Management
- Tools/workflows: Socrates pipeline applied to proprietary documents; Brainstorm-augmented internal search; Plato for synthesizing policy/process documentation with auditable reasoning
- Assumptions/dependencies: Data privacy and access controls; IP/licensing; domain adaptation for non-STEM content
- Patient and student education with verifiable reasoning narratives
- Sector: Healthcare, Education
- Tools/workflows: Patient-friendly pages explaining mechanisms (e.g., imaging modalities) and applications; student modules showing derivations step-by-step
- Assumptions/dependencies: Medical LCoTs vetted by clinicians; not a clinical decision system; plain-language framing to avoid misinterpretation
- Regulated content drafting with explicit chains-of-reasoning
- Sector: Finance, Energy, Public Policy
- Tools/workflows: Internal memos/reports that embed LCoTs; compliance documentation referencing verifiable endpoints (models, calculations, code snippets)
- Assumptions/dependencies: Regulatory acceptance varies; needs human compliance officers; domain-specific verifiable tests
- Curriculum-aligned problem generation and Socratic tutors
- Sector: Education
- Tools/workflows: Course-level problem banks generated via Socrates; tutors that walk students through derivations at multiple abstraction levels
- Assumptions/dependencies: Prompt sanitization pipeline active; teacher review; alignment with assessment standards
Long-Term Applications
These require further research, scaling, formalization, licensing, or standards adoption.
- Formalized, machine-readable knowledge graph for automated verification
- Sector: Software (formal methods), Academia (logic, theorem proving)
- Tools/workflows: Parsing LCoTs into formal logic; integration with proof assistants (e.g., Lean/Isabelle); “Verifier Engine” that checks derivational chains mechanically
- Assumptions/dependencies: Advances in NLP-to-logic translation; consensus on scientific ontologies; computational cost
- Continuous digestion of textbooks and peer-reviewed literature (“SciencePedia Live”)
- Sector: Academia, Publishing, Education
- Tools/workflows: Pipeline to ingest and verify new content; periodic updates to pages; frontier tracking and versioning
- Assumptions/dependencies: Publisher licensing; reliable extraction of verifiable endpoints from complex papers; robust evaluation and editorial oversight
- Standards for verifiable reasoning in regulated industries
- Sector: Healthcare (FDA submissions), Finance (model risk), Energy (safety), Aerospace
- Tools/workflows: Industry-wide schemas for reasoning chains; audit trails showing derivations; certification processes for AI-generated technical content
- Assumptions/dependencies: Regulators must endorse methods; legal frameworks for AI-generated documentation; professional liability norms
- Cross-domain innovation platforms
- Sector: R&D (materials, biotech, energy, robotics)
- Tools/workflows: “Cross-link Explorer” that mines LCoTs to propose hypotheses or technology transfers; lab notebooks linked to derivations; hypothesis ranking by verifiable connections
- Assumptions/dependencies: Experimental validation pipelines; data integration with LIMS/ELNs; IP management
- Explainable search engines that prioritize derivational provenance
- Sector: Software, Information Retrieval
- Tools/workflows: Consumer search experiences showing “how/why” via verified chains; provenance-first ranking; educational browsing modes
- Assumptions/dependencies: Scalability to web-scale indices; UX acceptance; moderation and anti-abuse mechanisms
- AI planning systems with verifiable steps (robots, autonomous systems)
- Sector: Robotics, Autonomous Vehicles, Industrial Automation
- Tools/workflows: Planning stacks that produce auditable LCoTs (constraints, safety checks) with verifiable endpoints (simulated outcomes); formal safety layers
- Assumptions/dependencies: Domain-specific simulators/verifiers; safety standards; real-time performance constraints
- National education infrastructure and multilingual parity
- Sector: Public Policy, Education
- Tools/workflows: Government-backed SciencePedia instances; curriculum mapping across regions; language parity via verified synthesis
- Assumptions/dependencies: Funding and governance; open standards; community moderation and teacher adoption
- Risk analysis and scenario modeling with auditable reasoning
- Sector: Finance, Insurance, Climate/Energy
- Tools/workflows: Scenario planning tools that output explicit chains and checkable endpoints; audit trails for stress tests and climate models
- Assumptions/dependencies: Model calibration and data quality; acceptance by risk committees; alignment with reporting standards (e.g., TCFD)
- Human-in-the-loop community curation interfaces
- Sector: Open Knowledge, Academia
- Tools/workflows: Contributor workflows to refine LCoTs, flag errors, add citations and frontier updates; reputation systems tied to verifiable improvements
- Assumptions/dependencies: Moderation protocols; alignment with academic incentives; transparent version control
- Domain-specific “Compliance Reasoning Auditor” products
- Sector: Pharma, Medical Devices, Finance, Energy
- Tools/workflows: Productized pipelines that ensure every claim is backed by a verifiable endpoint and cross-model consensus; exportable compliance bundles
- Assumptions/dependencies: Vendor ecosystem; integration with existing GxP or model risk management processes; certification pathways
Cross-cutting assumptions and dependencies
- Verifiable endpoints: Feasibility depends on tasks having checkable outcomes (numerical/symbolic answers, unit tests, code outputs). Open-ended analysis requires adapted verification strategies.
- Cross-model consensus: Reliability gains assume independent models converge. Domain drift or shared training flaws can reduce effectiveness.
- Coverage and bias: The LCoT corpus reflects LLM training data; frontier topics, historical context, and underrepresented areas need targeted ingestion and human review.
- Compute and cost: Large-scale generation, verification, and retrieval require significant compute and engineering resources.
- Security and privacy: Enterprise deployments must support data governance, access control, and secure indexing of proprietary documents.
- Licensing and IP: Digestion of textbooks and papers requires publisher agreements; enterprise content needs contractual safeguards.
- Regulatory acceptance: For high-stakes use, standards bodies must recognize verifiable LCoTs as acceptable evidence; human oversight is essential.
Glossary
- Baryon number violation: Non-conservation of the baryon number quantum number in certain non-perturbative processes. "explaining the structure of the QCD vacuum and the violation of baryon number"
- Berry connection: A gauge potential in parameter space associated with adiabatic quantum evolution, whose curl gives the Berry curvature. "starting from a Lagrangian with Berry connection"
- Bloch wavepacket: A localized superposition of Bloch states used to describe semiclassical electron dynamics in crystals. "Derive the semiclassical equations of motion for a Bloch wavepacket in an external electric field, and , starting from a Lagrangian with Berry connection"
- Brainstorm Search Engine: A retrieval system that operates on LCoT derivations to surface diverse, first-principles pathways leading to a concept. "The Brainstorm Search Engine directly addresses these challenges by operating on the LCoT Knowledge Base, a dataset where the reasoning process is the primary content."
- Cherenkov detector: An instrument that uses Cherenkov radiation to identify particle properties like velocity or mass. "Explain how a Cherenkov detector can be used to distinguish between two particles of different mass but the same high momentum."
- Cross-Model Answer Validation: A verification method that filters errors by requiring agreement on final answers across multiple independent models. "Finally, the agent performs Cross-Model Answer Validation."
- Directed keyword graph: A network where nodes are keywords and directed edges indicate references between encyclopedia entries to encode knowledge flow. "First, we constructed a directed keyword graph."
- Double-well potential: A potential energy landscape with two minima, often used as a prototype for tunneling and symmetry breaking. "first conceptualized in simple systems like the double-well potential"
- Gravitational instanton: A Euclidean-signature solution in gravity used to model tunneling-like processes in cosmology. "its application in cosmology, where gravitational instantons describe processes like Hawking radiation"
- Instanton: A non-perturbative field configuration in Euclidean spacetime representing tunneling between distinct vacua. "For example, a conventional search for “Instanton” would likely return its technical definition."
- Inverse knowledge search: A retrieval paradigm that starts from a target concept and returns diverse derivational chains culminating in it. "which performs inverse knowledge search---retrieving diverse, first-principles derivations that culminate in a target concept."
- Knowledge-point density: A metric indicating how many distinct learnable concepts or facts an article contains. "Plato-synthesized articles (conditioned on retrieved LCoTs) exhibit substantially higher knowledge-point density"
- Long Chain-of-Thought (LCoT): Extended, explicit multi-step reasoning trajectories that include detailed derivations and justifications. "constructing a verifiable Long Chain-of-Thought (LCoT) knowledge base"
- Modularity belief propagation (MODBP): A community detection algorithm that uses belief propagation to optimize modularity and uncover hierarchical network structure. "We therefore adopt a statistical approach based on modularity belief propagation (MODBP)~\cite{zhang2014scalable,shi2018weighted}."
- Plato agent: The LLM-based synthesizer that narrates verified LCoT derivations into coherent encyclopedia articles. "The Plato agent is a creative synthesizer built upon the Brainstorm Search Engine."
- Prompt Sanitization: A pre-reasoning check that removes flawed or ill-posed questions to prevent downstream errors. "It begins with Prompt Sanitization."
- QCD vacuum: The nontrivial ground state of quantum chromodynamics with rich topological structure. "explaining the structure of the QCD vacuum and the violation of baryon number"
- Reductionism: An approach that explains complex phenomena by deriving them from more fundamental principles. "inspired by the scientific principle of reductionism."
- Reinforcement Learning from Verifiable Rewards (RLVR): A post-training method that rewards models for producing reasoning whose endpoints can be mechanically verified. "Reinforcement Learning from Verifiable Rewards (RLVR) is a key post-training paradigm that optimizes a LLM not to mimic surface text, but to produce reasoning trajectories whose endpoints can be mechanically checked"
- Socratic method: A guided questioning strategy used to elicit knowledge and derive concepts from first principles. "a Socratic method ~\cite{socratic1,socratic2,socratic3} is employed to automatically generate a corpus of around three million first-principles-based questions."
- Verifiable Endpoint Design: A design choice to prefer questions with objectively checkable answers, enabling reliable validation of reasoning chains. "The process is further strengthened by a Verifiable Endpoint Design."
Collections
Sign up for free to add this paper to one or more collections.