- The paper demonstrates a novel RLVR framework that synthesizes long chain-of-thoughts using code-based verification across 12 domains.
- It introduces LoongBench and LoongEnv to generate and verify synthetic question-answer-code pairs with high pass rates in reasoning tasks.
- Empirical results highlight trade-offs in diversity, correctness, and difficulty, informing future improvements in model alignment and reasoning.
Loong: Synthesize Long Chain-of-Thoughts at Scale through Verifiers
Introduction and Motivation
The Loong framework addresses a central bottleneck in scaling LLM reasoning: the lack of high-quality, verifiable datasets in domains beyond mathematics and programming. While RL with verifiable reward (RLVR) has yielded substantial improvements in domains where correctness can be programmatically checked, extending this paradigm to other reasoning-intensive fields (e.g., logic, physics, finance) is hampered by data scarcity and annotation cost. Loong introduces a modular, open-source system for synthetic data generation and verification, enabling scalable RLVR across 12 diverse domains.
System Architecture
Loong comprises two principal components:
- LoongBench: A curated seed dataset of 8,729 human-vetted examples spanning 12 domains, each paired with executable code and rich metadata.
- LoongEnv: A modular synthetic data generation environment supporting multiple prompting strategies to produce new question-answer-code triples.
The agent-environment loop (Figure 1) operationalizes RLVR: synthetic questions are generated, code is executed to produce answers, an LLM agent generates chain-of-thought (CoT) solutions, and a verifier checks semantic agreement between the agent's answer and the code-executed result.
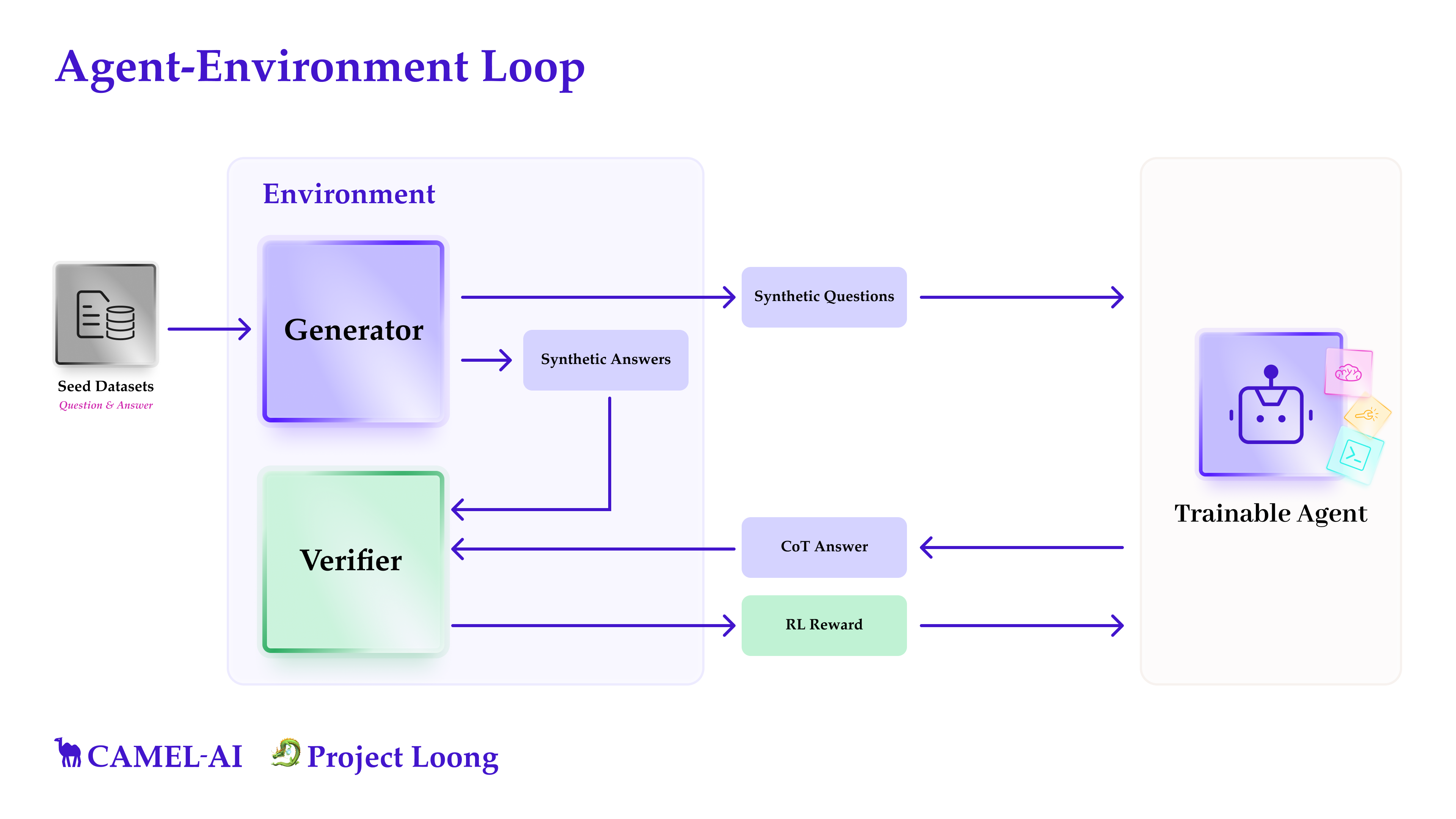
Figure 1: Agent-environment loop enabling scalable RLVR via synthetic question generation, code execution, agent reasoning, and automated verification.
LoongBench: Seed Dataset Construction
LoongBench is constructed by aggregating and curating domain-specific datasets, ensuring each question is solvable via code and paired with a verified answer. Domains include advanced mathematics, physics, chemistry, computational biology, finance, board games, graph theory, logic, mathematical programming, medicine, security/safety, and programming. For each domain, rigorous filtering and code-based verification are applied to ensure correctness and reproducibility. Notably, the dataset is not intended for direct training but as a bootstrap for synthetic data generation.
LoongEnv: Synthetic Data Generation and Verification
LoongEnv supports three principal question synthesis strategies:
- Few-shot prompting: Models are prompted with a handful of seed QA pairs to generate new problems in similar style.
- Self-Instruct: Instruction-tuned models recursively generate diverse and structured prompts.
- Evol-Instruct: Seed questions are evolved via mutation operations (generalization, specification, complexity scaling).
For each generated question, a coder agent produces executable code, which is run to obtain grounded answers. Verification is performed by comparing the code-executed answer with the agent's CoT-derived answer, using both LLM-as-judge and domain-specific verifiers. This dual-verification approach minimizes false positives and negatives, ensuring high-quality synthetic supervision.
Benchmarking and Empirical Analysis
Model Performance Across Domains
Benchmarking results reveal a well-calibrated spectrum of difficulty across domains. Mathematical programming remains challenging (∼10% accuracy), while programming is nearly saturated (up to 100% accuracy). Reasoning-optimized models (o3-mini, DeepSeek-r1) consistently outperform general-purpose models, especially in logic, graph theory, and game domains. Open-source models lag in reasoning-heavy tasks, highlighting the need for improved alignment and training data in the open community.
Synthetic Data Quality: Correctness, Diversity, and Difficulty
Execution and verification outcomes show that Few-shot prompting yields the highest pass rates, while Evol-Instruct produces more non-executable code but greater diversity and complexity. In the Logic domain, Few-shot achieves a 92.6% pass rate, whereas Evol-Instruct has a 55% non-executable rate. In Physics, Evol-Instruct maintains higher diversity but lower pass rates.
Cosine similarity and t-SNE analyses (Figures 4, 5) demonstrate that Few-shot generates lexically distinct but structurally similar questions, Self-Instruct increases semantic diversity, and Evol-Instruct produces semantically aligned but more complex examples. Evol-Instruct's higher similarity to seeds, coupled with lower model accuracy, indicates increased reasoning difficulty.
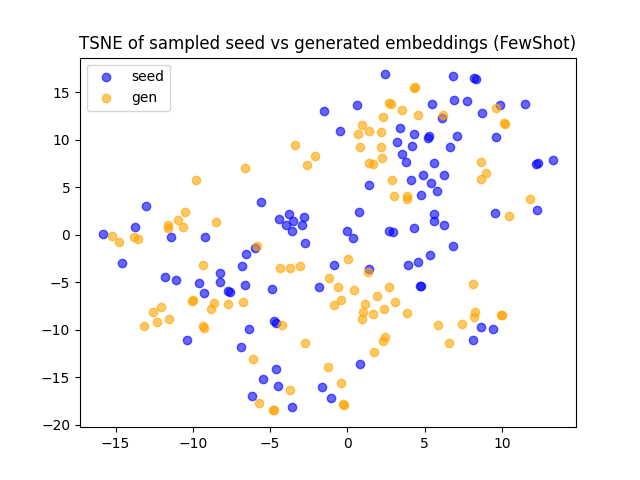
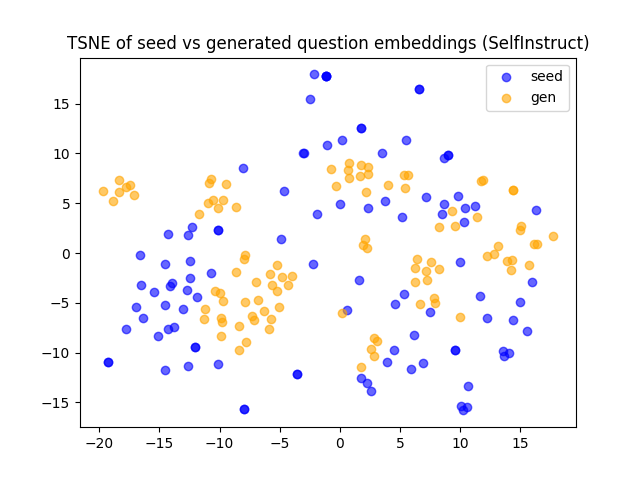
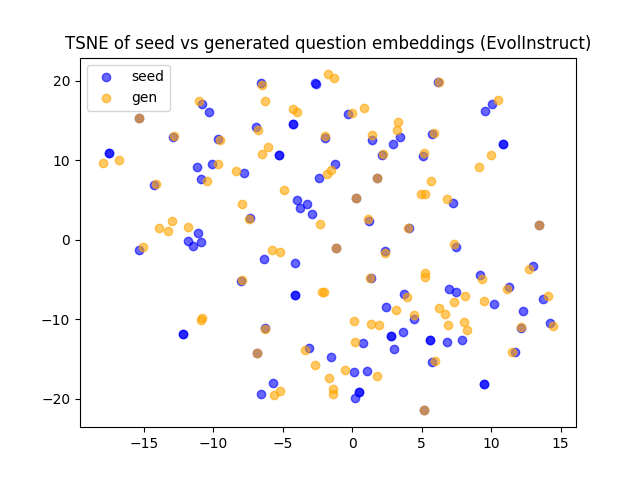
Figure 2: t-SNE projection of seed and generated problem embeddings in Advanced Physics, showing overlap and diversity across generation strategies.
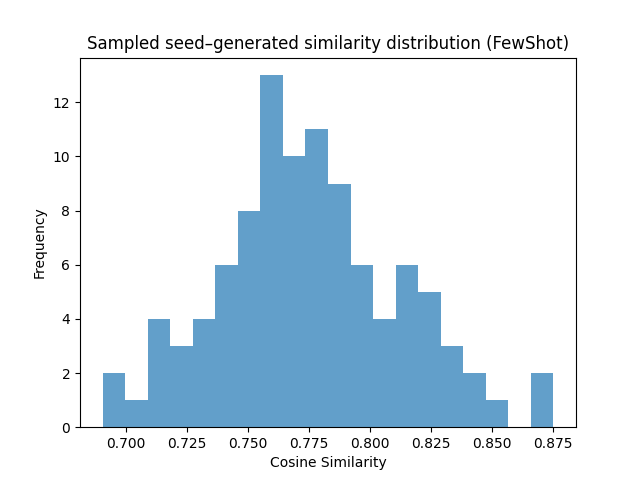
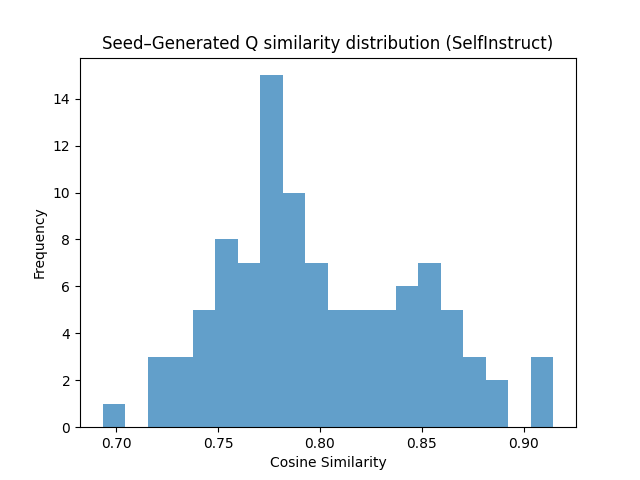
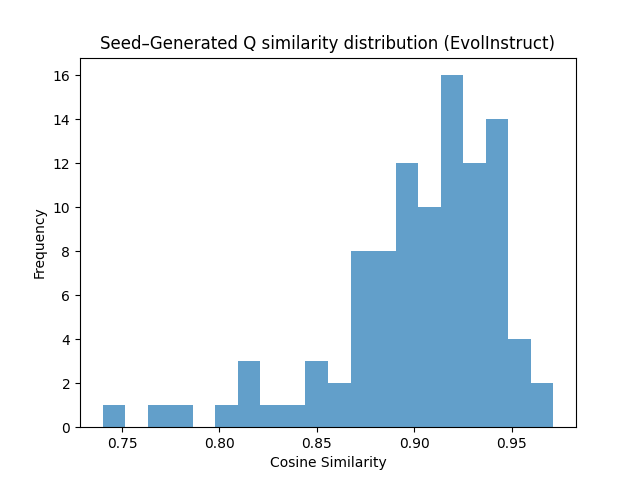
Figure 3: Cosine similarity distribution between seed and generated questions in Advanced Physics for different generation strategies.
Difficulty analysis confirms that Evol-Instruct-generated questions are harder for models to solve, despite their semantic proximity to seeds. For Advanced Physics, GPT4.1-mini and DeepSeek-r1 achieve 92–93% accuracy on Few-shot data, dropping to 62–70% on Evol-Instruct data.
Implementation Considerations
Loong is implemented atop the CAMEL framework, with all models evaluated via standardized prompts and consistent inference settings. Synthetic data generation is parallelized and sandboxed for code execution. Verification leverages both LLM-as-judge and rule-based domain verifiers. Resource requirements are moderate: a single NVIDIA H100 80GB GPU suffices for open-source model inference and synthetic data generation at scale.
Implications and Future Directions
Loong demonstrates that structured synthetic data generation and automated verification can scale RLVR to domains lacking curated datasets. The framework enables fine-grained benchmarking, ablation studies, and targeted model improvement. Key future directions include:
- Integrating tool-augmented generation and formal abstraction for richer supervision.
- Scaling LoongBench to multilingual and multimodal tasks.
- Leveraging LoongEnv for RLVR, where agents are rewarded only for semantically verified answers, enabling annotation-free alignment.
The approach is extensible to any domain where code-based or programmatic verification is feasible, and can be adapted for tool-augmented or multimodal reasoning.
Conclusion
Loong provides a modular, extensible framework for synthesizing long chain-of-thoughts at scale via verifiers, addressing the data bottleneck in reasoning-intensive domains. By combining curated seed datasets, flexible synthetic generation, and robust verification, Loong enables scalable RLVR and fine-grained benchmarking. The empirical results highlight the trade-offs between diversity, correctness, and difficulty in synthetic data generation, and establish concrete targets for future model development. Loong sets the stage for annotation-free, domain-general alignment of LLMs, with broad implications for the future of AI reasoning.

