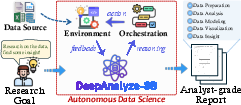
DeepAnalyze: Agentic Large Language Models for Autonomous Data Science
Abstract: Autonomous data science, from raw data sources to analyst-grade deep research reports, has been a long-standing challenge, and is now becoming feasible with the emergence of powerful LLMs. Recent workflow-based data agents have shown promising results on specific data tasks but remain fundamentally limited in achieving fully autonomous data science due to their reliance on predefined workflows. In this paper, we introduce DeepAnalyze-8B, the first agentic LLM designed for autonomous data science, capable of automatically completing the end-toend pipeline from data sources to analyst-grade deep research reports. To tackle high-complexity data science tasks, we propose a curriculum-based agentic training paradigm that emulates the learning trajectory of human data scientists, enabling LLMs to progressively acquire and integrate multiple capabilities in real-world environments. We also introduce a data-grounded trajectory synthesis framework that constructs high-quality training data. Through agentic training, DeepAnalyze learns to perform a broad spectrum of data tasks, ranging from data question answering and specialized analytical tasks to open-ended data research. Experiments demonstrate that, with only 8B parameters, DeepAnalyze outperforms previous workflow-based agents built on most advanced proprietary LLMs. The model, code, and training data of DeepAnalyze are open-sourced, paving the way toward autonomous data science.

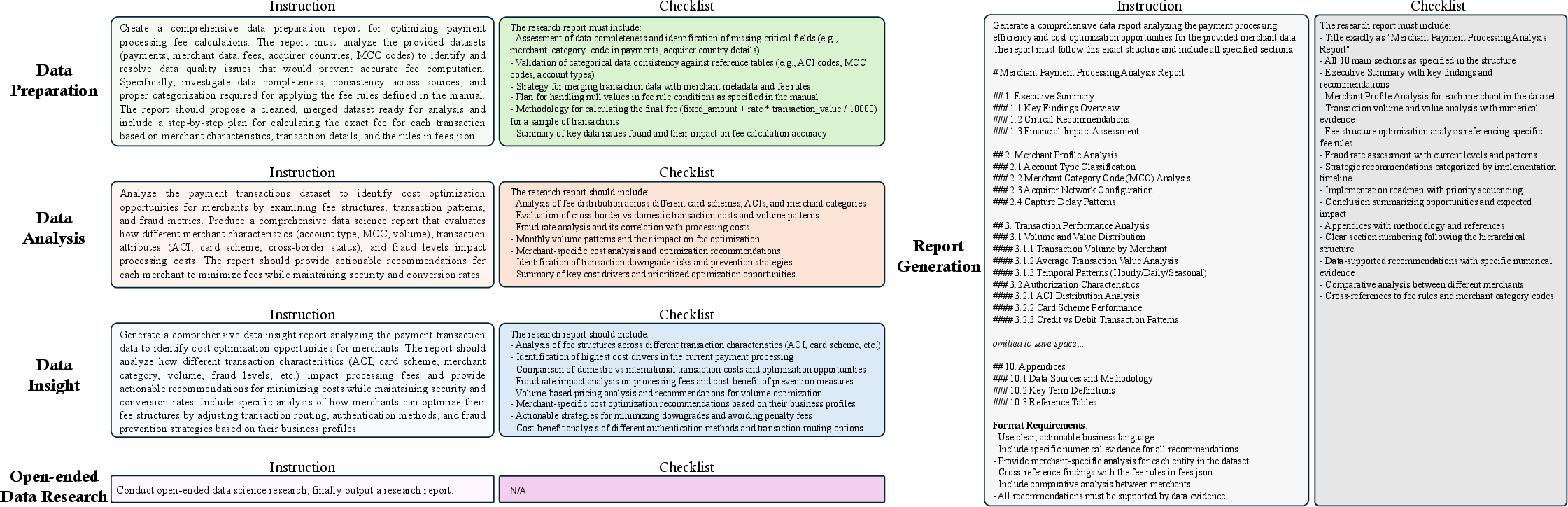






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces DeepAnalyze-8B, a new kind of AI model designed to act like an independent data scientist. Instead of following a fixed recipe, it plans and carries out the entire data science process on its own—from reading data, analyzing it, writing and running code, making charts or models, and finally producing a clear report.
What questions did the researchers ask?
The paper focuses on a few simple but big questions:
- Can we train an AI to handle the whole data science pipeline by itself, not just one small task like answering a question or making a chart?
- How can an AI learn to plan multi-step work, adapt to feedback, and improve its approach like a human data scientist?
- What training methods and practice data are needed to help the AI learn complex, real-world data work?
How did they do it?
The team built both a special “action-based” model design and a training program that teaches the AI step by step, like school.
The model’s actions
To behave like a data scientist, the model uses five clear actions. Think of these actions like tools in a toolbox. When solving a problem, it picks the right tool at the right time:
- Analyze: It plans and reasons in plain language. This is like sketching out a plan on paper.
- Understand: It inspects the data sources (tables, databases, files) to figure out what’s inside.
- Code: It writes Python code to clean, analyze, and visualize data.
- Execute: It runs the code and reads the results or error messages.
- Answer: It produces the final result or research report.
The model switches between these actions on its own, based on what it needs next. When it writes code, the system actually runs it and gives the model feedback—just like a student testing their solution.
The training approach
Training the model to be “agentic” (able to act and decide steps on its own) is hard. The team used a curriculum-based approach—teaching from easy to hard—plus a lot of practice data.
- Stage 1: Single skills
- The model first learns individual abilities: reasoning carefully in steps, understanding structured data like tables, and writing working code.
- This is like learning basic math, reading charts, and programming before tackling a full science project.
- Stage 2: Multiple skills together
- Next, the model practices combining those abilities in real, multi-step tasks.
- It uses reinforcement learning—like a video game where it gets points for good results. The points (rewards) come from things like correct answers, good code that runs successfully, clear charts, and high-quality final reports.
- Because many data tasks don’t have a single “right answer” (especially open-ended research), the rewards are “hybrid”: some are rule-based (did it follow the right format, did the code run?), and some are judged by another AI (is the report useful, clear, and accurate?).
Creating the practice data
Real multi-step data science practice data is rare, so the team generated their own high-quality training examples:
- Reasoning trajectory synthesis:
- They took existing datasets (like table question answering and data code tasks) and asked strong AI models to show detailed step-by-step reasoning.
- They refined the reasoning to focus more on structured data and inserted key “thinking words” (like “wait” or “but”) to improve careful decision-making.
- Interaction trajectory synthesis:
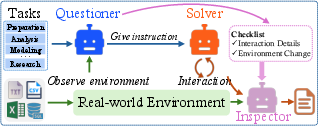
- They built a multi-agent system with three roles:
- A questioner: creates realistic data tasks based on the data sources.
- A solver: uses the five actions to complete the task.
- An inspector: checks whether the steps and environment changes (like files created or code used) match the rules and goals.
- This produced clean, multi-turn scripts showing how a data scientist would actually work.
They released this training set as DataScience-Instruct-500K, so others can use it too.
What did they find?
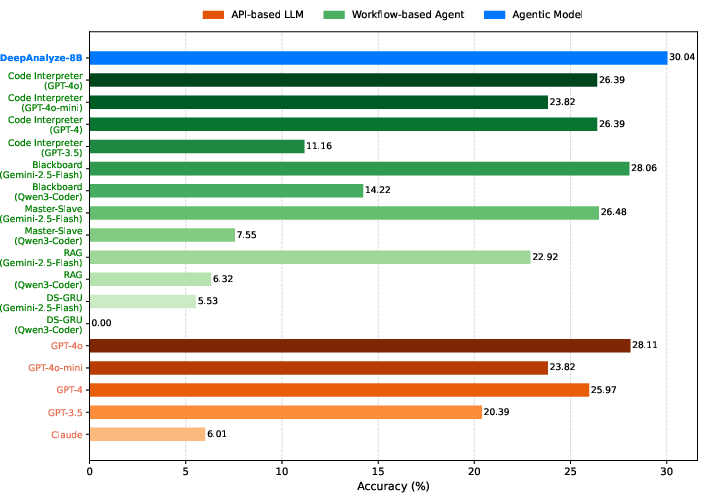
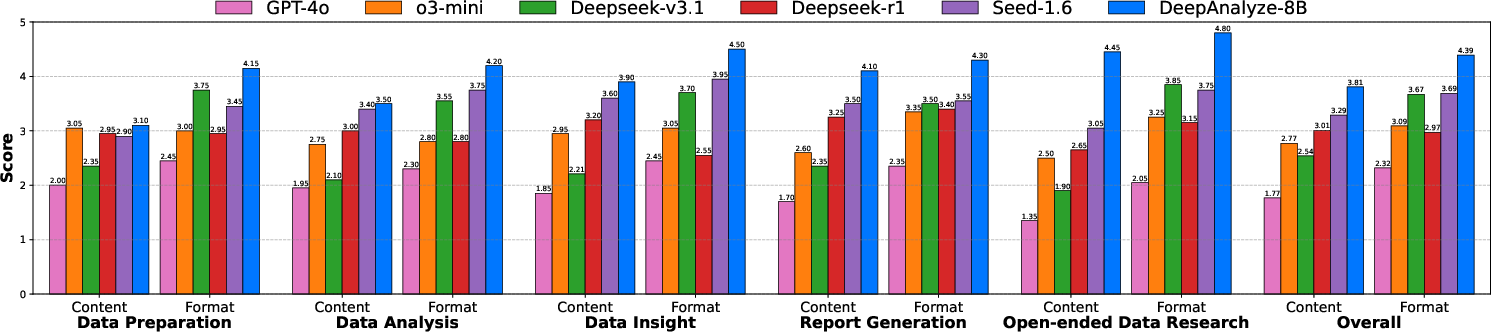
- DeepAnalyze-8B, even though it’s a relatively small model (8 billion parameters), beat many agents built on powerful proprietary AI models across 12 benchmarks.
- It can handle the full data science pipeline: data preparation, analysis, modeling, visualization, and insight generation.
- It’s the first open agentic model that can perform open-ended data research and write analyst-level reports—going beyond simple Q&A.
- The model, code, and training data are open-source, so researchers and developers can build on it.
Why does it matter?
This research shows that AI can move from being a helpful tool to a true “data science teammate” that plans and executes complex work on its own. That could:
- Speed up data projects in business, science, and education.
- Help non-experts get high-quality insights from their data.
- Reduce the need for complicated, hand-designed workflows and prompts.
At the same time, it’s important to use such systems responsibly. They should be checked for correctness, fairness, and transparency—especially when their reports influence decisions. Still, by open-sourcing the model and data, the authors make it easier for others to improve and safely adapt the technology, pushing toward more reliable, autonomous data science in the future.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of gaps and open questions that remain unresolved and that future work could address:
- Lack of rigorous, reproducible training details: the paper does not specify complete GRPO hyperparameters, reference model choice, learning rates, batch sizes, total compute, random seeds, and stability interventions, making the agentic training pipeline hard to replicate and compare.
- Ambiguity in environment configuration: there is no precise description of the execution sandbox (OS, Python versions, library versions, resource limits, timeouts, I/O permissions), making safety, determinism, and portability of code execution unclear.
- Security and safety of code execution: the risks of executing model-generated code (e.g., arbitrary file writes, network calls, system resource exhaustion, harmful payloads) and the guardrails/sandboxing strategy are not detailed; no penetration testing or red-team assessment is reported.
- Incomplete definition and implementation of the Understand action: it is unclear how “Understand” interacts with large external data sources without full ingestion (e.g., what metadata is accessible, APIs to preview schemas, sampling methods, and guarantees about scalability to large tables).
- Reward function design risks (especially for open-ended research): the hybrid reward encourages more interaction turns (min(|T|/NT, 1)), potentially incentivizing unnecessary or “reward-hacking” behaviors; no checks for efficiency, redundancy, or harmful actions are included.
- Reliability of LLM-as-a-judge evaluations: the judge model(s), calibration procedures, inter-rater reliability, sensitivity to prompt variations, and bias mitigation are not described; no human evaluation or triangulation against expert ratings for “analyst-grade” reports is provided.
- Missing ablations: there is no ablation study isolating the effects of curriculum-based training, cold-start interaction fine-tuning, GRPO, data-grounded trajectory synthesis, or keyword-guided reasoning refinement on final performance.
- Weakness in data modeling capabilities: the reported F5 (Data Modeling) metric is substantially lower than other sub-tasks; the paper lacks error analysis and a plan to strengthen statistical modeling, ML workflow orchestration, hyperparameter tuning, and evaluation rigor.
- Baseline fairness and comparability: it is unclear whether all baseline agents had equal tool access, identical execution environments, and consistent interaction budgets; differences in workflow scaffolding, toolchains, and context lengths could confound results.
- Generalization beyond tabular/database data: the system’s applicability to other structured modalities (e.g., time series, graphs), semi-structured/unstructured data (e.g., logs, JSON, PDFs, images), and multi-modal pipelines is not evaluated.
- Scalability to very large data: mechanisms for interacting efficiently with datasets far larger than memory/context (e.g., progressive sampling, indexing, pushdown computation, streaming) are not specified or empirically validated.
- Limited tool ecosystem support: the agent appears centered on Python with a few DS libraries; integration with SQL engines, R, Julia, large-scale compute frameworks (Spark/Dask), AutoML toolchains, or specialized domain libraries (finance/biomed) is not demonstrated.
- Action space extensibility: the process for adding new actions/tools (e.g., web search, API calling, dashboards, report templating systems) and safely teaching the model to use them is not described.
- Data-grounded trajectory synthesis risks: synthetic problems derived from NL2SQL datasets may not represent real-world DS workflows; the multi-agent questioner/solver/inspector pipeline lacks quantitative quality assurance metrics, coverage analysis, and failure-mode characterization.
- Potential data contamination and leakage: teacher LLMs used for distillation and trajectory synthesis may have been trained on benchmark content; safeguards against contamination and measures of out-of-distribution robustness are not reported.
- Keyword-guided reasoning refinement validation: the impact of injecting specific “key reasoning” tokens (e.g., “but”, “wait”) on downstream task performance, robustness, and unintended biases is not empirically validated.
- Transparency of the “analyst-grade” claim: the criteria, rubrics, and external expert assessments for report quality (usefulness, richness, soundness, interpretability, readability) are not documented; reproducible report-scoring pipelines are absent.
- Latency and cost efficiency: runtime metrics (per task/turn latency, total interaction cost, compute footprint) and efficiency-vs-quality trade-offs are not reported, which limits practical deployment guidance.
- Robustness to noisy, adversarial, or evolving environments: the agent’s behavior under malformed schemas, missing values, drift, API failures, library updates, or conflicting instructions is not analyzed.
- Privacy and compliance: handling of potentially sensitive data sources, auditability of actions, and compliance features (e.g., PII redaction, governance logs) are not discussed.
- Training data composition and licensing: the DataScience-Instruct-500K dataset’s domain coverage, duplication rates, license compatibility (especially with teacher-generated content), and potential biases are not characterized.
- Long-context and memory limitations: while sequence lengths of 8k/32k are mentioned, no experiments analyze context overflow, retrieval strategies, or memory-aware planning for multi-session DS projects.
- Interpretability of agent decisions: the system does not provide mechanisms to explain action choices, planning updates, or code changes in a way that supports human oversight and error recovery.
- Real-world deployment evidence: beyond benchmarks, there is no evaluation on live, end-to-end business analytics/reporting tasks with stakeholder feedback, measurable business impact, or longitudinal studies.
- Cross-lingual and localization support: the agent’s performance across languages (instructions, schemas, documentation) and cultural/locale-specific data handling (date formats, currency) is not assessed.
- Formalization of success criteria for open-ended research: the paper lacks clear, task-specific definitions of “success” beyond judge scores, including coverage of confounding variables, sensitivity analyses, and reproducible evaluation protocols.
Practical Applications
Immediate Applications
The following applications can be deployed now using the open-sourced DeepAnalyze-8B model, code, and DataScience-Instruct-500K dataset.
- Autonomous EDA copilot for notebooks and IDEs (sector: software/data tools)
- Description: A Jupyter/VS Code extension that uses DeepAnalyze’s actions to plan analyses, inspect external CSV/SQL/XLSX files, generate Pandas/NumPy/Matplotlib code, execute it, iterate on feedback, and produce analyst-grade summaries.
- Potential product/workflow: “EDA Copilot” that inserts runnable code cells, plots, and a final narrative into notebooks; logs interaction trajectories for reproducibility.
- Assumptions/dependencies: Secure, sandboxed Python runtime with common DS libraries; connectors to local/DB data sources; runtime that recognizes the model’s special action tokens and executes code blocks.
- Natural-language BI assistant embedded in dashboards (sector: business intelligence/analytics)
- Description: Let business users ask questions (“Why did Q3 revenue dip in APAC?”), auto-generate SQL/Python, produce plots, and add narrative insights into Tableau/Power BI/Looker.
- Potential product/workflow: “Ask Your Data” panel with transparent code and execution logs, plus exportable reports.
- Assumptions/dependencies: Governed data access (row-/column-level security), database connectors, audit logging, human review for sensitive decisions.
- Data preparation and quality assistant (sector: DataOps/ETL)
- Description: Automates profiling, cleaning (missing values, type normalization), schema alignment, and suggests transformation pipelines with unit tests.
- Potential product/workflow: A “Data Prep Agent” that proposes and executes ETL steps, with checks for data drift and validation summaries.
- Assumptions/dependencies: Access to staging data, execution sandbox, integration with pipeline orchestrators (Airflow/Prefect), defined data contracts.
- Automated monthly KPI and narrative reporting (sector: finance/operations)
- Description: Generates analyst-grade reports from ERP/CRM/finance tables, including time-series analysis, comparisons, and annotated charts.
- Potential product/workflow: “Auto-Report Generator” for CFO/COO packs with reproducible code and embedded figures.
- Assumptions/dependencies: Organization-specific metric definitions and governance, domain fine-tuning for finance terminology, human approval workflows.
- Marketing cohort/A/B analysis assistant (sector: marketing/analytics)
- Description: Runs segmentation, calculates lift, visualizes funnel metrics, and explains findings in plain language.
- Potential product/workflow: “Experiment Summary Bot” integrated with analytics warehouses (e.g., BigQuery, Snowflake).
- Assumptions/dependencies: Clean event schemas, experiment metadata, and reliable identifiers; permissioned data access.
- Database analytics and NL2SQL agent (sector: data platforms)
- Description: Constructs complex SQL (joins, aggregations) against multi-table schemas (Spider/BIRD-style), executes queries, and summarizes results.
- Potential product/workflow: “SQL Copilot” for analysts and DB explorers with schema understanding and query optimization hints.
- Assumptions/dependencies: SQL connectivity, read-only roles in production, query cost controls, and result caching.
- Data science coding assistant (sector: software engineering/data engineering)
- Description: Generates tested Pandas/NumPy/Matplotlib code snippets, creates unit tests for data transformations, and performs PR reviews focused on data logic.
- Potential product/workflow: CI-integrated “Data Code Reviewer” that flags risky transformations and suggests fixes.
- Assumptions/dependencies: Access to representative sample data, CI hooks, code execution sandbox, and test frameworks.
- Education: Interactive data science tutor (sector: education)
- Description: Uses synthesized reasoning trajectories to teach EDA/modeling; creates assignments, auto-grades code and reports, and provides step-by-step feedback.
- Potential product/workflow: “Data Science Lab Coach” for university courses and bootcamps.
- Assumptions/dependencies: Institution-specific curricula, restricted execution environments for students, plagiarism detection.
- Government/open-data portal assistant (sector: public policy)
- Description: Answers citizen queries on open datasets (e.g., air quality trends), produces transparent, auditable reports with full interaction logs.
- Potential product/workflow: “Open Data Analyst” widget on city data portals.
- Assumptions/dependencies: Public datasets with clear schemas, accessibility and governance policies, human validation for public communications.
- Personal analytics coach (sector: daily life)
- Description: Analyzes personal spreadsheets (budget, workouts, wearables), creates charts and weekly insights, and suggests actionable changes.
- Potential product/workflow: Local desktop app for privacy-preserving personal analytics.
- Assumptions/dependencies: On-device execution (8B model is feasible on modern hardware), sandboxed file access, simple UI.
- Research reproducibility assistant (sector: academia)
- Description: Converts raw datasets into reproducible pipelines, documents analyses, and generates structured research reports with embedded code and results.
- Potential product/workflow: “Literate Analysis Builder” for labs to ensure transparent methods and logs.
- Assumptions/dependencies: Domain-specific statistical libraries, lab data connectors, PI/human oversight.
- Model training and benchmarking platform (sector: ML/LLM research)
- Description: Use DataScience-Instruct-500K to train or evaluate new data-centric LLMs; study curriculum-based agentic training and trajectory synthesis.
- Potential product/workflow: Open benchmarking harness with DataSciBench/DABStep tooling.
- Assumptions/dependencies: Compute resources, licensing compliance, consistent evaluation protocols.
Long-Term Applications
The following opportunities require further research, scaling, reliability work, governance, or integration beyond the current release.
- Autonomous enterprise-wide data research across data lakes (sector: data platforms/analytics)
- Description: Always-on agents that continuously monitor, investigate anomalies, and publish deep reports across heterogeneous sources.
- Potential product/workflow: “Continuous Insights Engine” that orchestrates cross-domain analyses and alerts.
- Assumptions/dependencies: Robust data governance, scalable connectors, stronger guardrails, larger models or ensembles for reliability, organizational buy-in.
- Regulated-sector analytics (sector: healthcare/finance)
- Description: Clinical metrics, claims analysis, or regulatory reporting with strict privacy, accuracy, and audit requirements.
- Potential product/workflow: “Compliance-Ready Analytics Agent” certified for PHI/PII handling with formal validation.
- Assumptions/dependencies: Privacy-preserving deployments (on-prem/edge), certification processes (HIPAA, SOC2, etc.), bias and error controls, human-in-the-loop signoff.
- Autonomous BI creation and metric governance (sector: enterprise analytics)
- Description: Agents define KPIs, create governed dashboards, and maintain metric stores across teams.
- Potential product/workflow: “Metric Steward Agent” that reconciles definitions and ensures consistent, audited analytics.
- Assumptions/dependencies: Organization-wide metric taxonomy, data contracts, and change-management processes.
- Self-improving agentic learning loops (sector: ML systems)
- Description: Continuous RL with hybrid rewards (rule-based + judge) and human feedback to refine strategies and reduce error rates.
- Potential product/workflow: “Learning Analytics Agent” with safe exploration and staged deployment.
- Assumptions/dependencies: Reliable online evaluation harnesses, feedback pipelines, reward models more robust than LLM-as-a-judge, and safety constraints.
- Scientific discovery assistant (sector: academia/R&D)
- Description: Designs pre-analysis plans, runs robust statistical tests, explores causal relationships, and generates publishable research reports.
- Potential product/workflow: “Autonomous Lab Analyst” integrated with ELNs/LIMS and multi-modal data (tables, plots, instruments).
- Assumptions/dependencies: Domain-specific validation, causal inference modules, multi-modal training, and reproducibility standards.
- Scalable policy analysis and impact evaluation (sector: public policy)
- Description: Ingests national statistics, performs causal/forecast analyses, and produces policy memos with transparent methods.
- Potential product/workflow: “Policy Insight Engine” for ministries and think tanks.
- Assumptions/dependencies: Access to high-quality longitudinal data, methodological rigor (causal inference), peer review and interpretability requirements.
- Energy and industrial IoT analytics (sector: energy/manufacturing)
- Description: Time-series forecasting, anomaly detection, and operational optimization across SCADA/IoT streams.
- Potential product/workflow: “Industrial Analytics Agent” that proposes interventions and explains root causes.
- Assumptions/dependencies: Real-time connectors, streaming execution environments, safety and reliability certification.
- Autonomous quantitative research (sector: finance)
- Description: Factor discovery, backtesting, risk analysis, and research reporting with audit trails.
- Potential product/workflow: “Quant Research Copilot” integrated with market data and backtest engines.
- Assumptions/dependencies: High-quality market feeds, robust backtesting libraries, compliance and governance, stringent error controls.
- At-scale educational personalization (sector: education)
- Description: Personalized curricula, autograding, and formative feedback for data science courses at scale.
- Potential product/workflow: “Adaptive DS Tutor” deployed institution-wide.
- Assumptions/dependencies: Bias/fairness safeguards, cheating detection, reliable assessment rubrics, and curriculum alignment.
- Standardized, auditable agent frameworks (sector: governance/compliance)
- Description: Industry standards for action-token logs, environment feedback schemas, and reproducibility audits to satisfy regulators.
- Potential product/workflow: “Agent Audit Kit” with interoperable logging and verification tools.
- Assumptions/dependencies: Cross-vendor standards, independent verification bodies, secure logging infrastructure.
- Multimodal data research (sector: cross-domain analytics)
- Description: Integrating tables, text, charts, images, and geospatial data for richer analyses and visual explanations.
- Potential product/workflow: “Multimodal Data Researcher” capable of chart reading and geospatial analytics.
- Assumptions/dependencies: VLM extensions, datasets and training for multimodal reasoning, GPU capacity, and new evaluation benchmarks.
Glossary
- Adaptive optimization: The capability of iteratively refining actions based on feedback in real-world data environments. "Addressing these challenges requires endowing LLMs with two higher-level capabilities: autonomous orchestration and adaptive optimization."
- Advantage (RL): A reinforcement learning quantity estimating how much better an action is than a baseline for a given state. "where is the advantage calculated from the rewards of outputs within each group, $\pi_{\mathrm{ref}$ is the reference model, and are hyperparameters."
- Agentic LLM: A LLM trained to act autonomously through multi-step reasoning and interactions with environments. "we introduce DeepAnalyze-8B, the first agentic LLM designed for autonomous data science"
- Agentic model: A model endowed with autonomous planning and interaction abilities, learned via agentic training. "Agentic Model: To the best of our knowledge, DeepAnalyze is the first agentic LLM tailored for autonomous data science, endowed with two indispensable capabilities, autonomous orchestration and adaptive optimization."
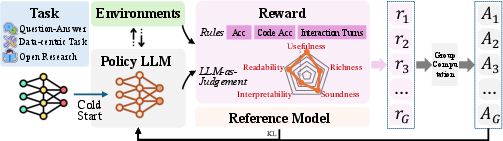
- Agentic reinforcement learning: Reinforcement learning applied to train LLMs to perform multi-step reasoning and environment interactions. "we employ agentic reinforcement learning to train DeepAnalyze to apply multiple abilities in real-world environments to complete complex data science tasks."
- Agentic training: A training paradigm that equips LLMs with autonomous, interactive problem-solving capabilities via reinforcement learning in real-world settings. "we propose a curriculum-based agentic training paradigm"
- Autonomous data science: End-to-end automation of the data science pipeline from raw data to research reports. "Autonomous data science has long been pursued as an important goal of intelligent systems."
- Autonomous orchestration: The ability to plan and coordinate interdependent actions to accomplish complex tasks. "autonomous orchestration enables LLMs to comprehend user intents and systematically coordinate a sequence of interdependent actions to accomplish complex tasks"
- Chain-of-Thought (CoT): Explicit reasoning traces used during training or inference to improve multi-step problem solving. "we fine-tune the foundation LLM using long CoT data (i.e., including reasoning traces)"
- Cold start: An initial fine-tuning phase to teach interaction formats or basic behaviors before reinforcement learning. "we first perform a cold start by fine-tuning the LLM on synthesized interaction trajectories"
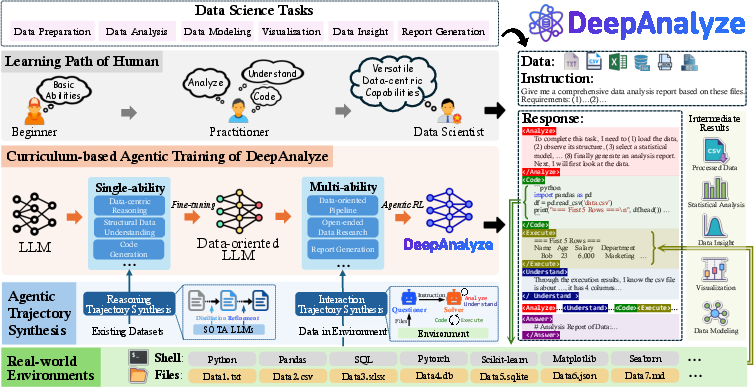
- Curriculum-based agentic training: A progressive training schedule from easier single-ability tasks to complex multi-ability tasks. "we propose a curriculum-based agentic training paradigm with data-grounded trajectory synthesis"
- Data-grounded trajectory synthesis: Automatic construction of high-quality reasoning and interaction trajectories anchored to real data sources. "We also introduce a data-grounded trajectory synthesis framework"
- Database-oriented LLMs: LLMs specialized for interacting with databases and SQL-related tasks. "and database-oriented LLMs"
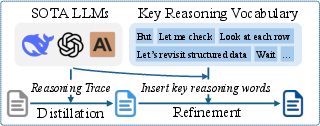
- Distillation: Extracting reasoning or behavior from stronger models to supervise training of another model. "In the distillation step, we employ advanced LLMs as teacher models to extract their reasoning trajectories"
- GRPO (Group Relative Policy Optimization): A reinforcement learning algorithm that optimizes policies using group-wise relative advantages. "group relative policy optimization (GRPO)"
- Hybrid reward modeling: Combining rule-based metrics with learned or LLM-judged scores to evaluate outputs. "we adopt a hybrid reward modeling that combines rule-based rewards with LLM-as-a-judge rewards."
- Interaction trajectory synthesis: Generating multi-step action–feedback sequences by interacting with data environments. "Interaction Trajectory Synthesis, which constructs entire data science trajectory based on structured data sources in the environment."
- Keyword-guided refinement: Inserting key reasoning words to strengthen focus and quality of reasoning traces. "we introduce keyword-guided refinement to further enhance the reasoning trajectories"
- Kullback–Leibler (KL) divergence: A measure of how one probability distribution diverges from a reference distribution; used as a regularizer in RL. "- \beta \mathrm{D}{KL}\left(\pi\theta \parallel \pi_{\mathrm{ref}\right)"
- LLM-as-a-judge: Using an LLM to evaluate the quality of outputs for reward assignment. "LLM-as-a-judge rewards."
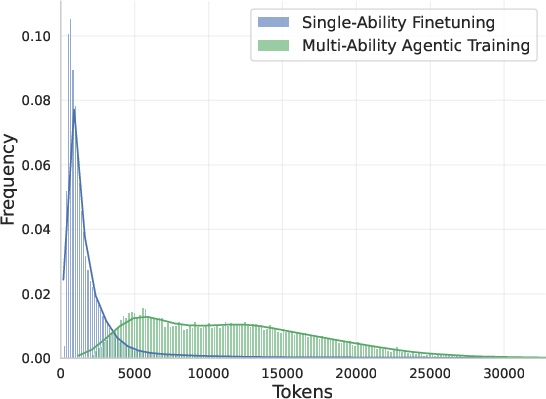
- Multi-ability agentic training: Training that enables a model to integrate reasoning, data understanding, and code generation in real environments. "In the multi-ability agentic training stage (including both cold start and RL phases)"
- Multi-agent system: A coordinated set of roles (e.g., questioner, solver, inspector) that collaborate to synthesize trajectories. "we develop a multi-agent system to synthesize data science interaction trajectories"
- Multi-turn interaction trajectory: A sequence of actions and environment feedback spanning multiple steps. "construct multi-turn interaction trajectory data with the environment"
- NL2SQL: Natural language to SQL task/datasets mapping text questions to executable SQL over databases. "NL2SQL datasets such as Spider \citep{yu-etal-2018-spider} and BIRD \citep{li2024can}"
- Open-ended data research: Exploratory, unconstrained analysis leading to comprehensive findings and reports. "The emergence of open-ended data research further elevates the level of complexity"
- Policy model: The parameterized model that outputs actions (tokens) given states (inputs), optimized via RL. "then optimizes the policy model by maximizing the following objective:"
- Reasoning trajectory synthesis: Creating detailed reasoning processes for instruction–response pairs to supervise training. "Reasoning Trajectory Synthesis, which construct the reasoning trajectory for existing structured data instruction datasets"
- Reference model: A fixed or slowly changing model used to regularize policy updates during training. "$\pi_{\mathrm{ref}$ is the reference model, and are hyperparameters."
- Reinforcement learning (RL): Learning to act via trial-and-error with rewards in an environment. "Agentic training aims to enhance LLMs as agentic models through reinforcement learning"
- Reward sparsity: A challenge where successful outcomes (positive rewards) are rare, hindering effective learning. "This leads to severe reward sparsity, i.e., a lack of positive reinforcement signals"
- RL-Zero: A reinforcement learning setup without supervised warm-start, often difficult due to sparse rewards. "existing agentic training (such as RL-Zero or RL with cold-start training \citep{deepseekr1})"
- Self-reflection: An agent technique where it critiques or revises its own reasoning/actions to improve performance. "including ReAct \citep{yao2023react}, AutoGen \citep{wu2024autogen}, and self-reflection \citep{pan2023automaticallycorrectinglargelanguage}"
- Single-ability fine-tuning: Supervised training focused on individual skills before multi-ability RL. "Single-ability Fine-tuning.\quad"
- Structured data understanding: The ability to interpret and reason over structured formats like tables and databases. "Unlike foundation LLMs that focus on understanding and generating natural language, LLMs for data science meet the additional challenge of understanding and interaction with structured data"
- Tabular LLMs: LLMs specialized in tasks over tables and spreadsheets. "tabular LLMs"
- Trajectory scarcity: The lack of long, high-quality solution paths impeding exploration and learning. "two key challenges: reward sparsity and trajectory scarcity."
- Workflow-based agents: Systems that rely on predefined procedural steps to guide LLMs through tasks. "workflow-based data science agents \citep{NEURIPS2023_8c2df4c3,dsagent,sun2024lambda,hong-etal-2025-data}, which rely on predefined procedural workflows"
Collections
Sign up for free to add this paper to one or more collections.