PlanarGS: High-Fidelity Indoor 3D Gaussian Splatting Guided by Vision-Language Planar Priors
Abstract: Three-dimensional Gaussian Splatting (3DGS) has recently emerged as an efficient representation for novel-view synthesis, achieving impressive visual quality. However, in scenes dominated by large and low-texture regions, common in indoor environments, the photometric loss used to optimize 3DGS yields ambiguous geometry and fails to recover high-fidelity 3D surfaces. To overcome this limitation, we introduce PlanarGS, a 3DGS-based framework tailored for indoor scene reconstruction. Specifically, we design a pipeline for Language-Prompted Planar Priors (LP3) that employs a pretrained vision-language segmentation model and refines its region proposals via cross-view fusion and inspection with geometric priors. 3D Gaussians in our framework are optimized with two additional terms: a planar prior supervision term that enforces planar consistency, and a geometric prior supervision term that steers the Gaussians toward the depth and normal cues. We have conducted extensive experiments on standard indoor benchmarks. The results show that PlanarGS reconstructs accurate and detailed 3D surfaces, consistently outperforming state-of-the-art methods by a large margin. Project page: https://planargs.github.io





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces PlanarGS, a method to build accurate 3D models of indoor spaces (like rooms) from regular photos. It improves a popular technique called 3D Gaussian Splatting by adding smart hints about flat surfaces, such as walls and floors, so the final 3D shapes are smooth, straight, and correct.
What questions did the researchers ask?
The researchers focused on three simple questions:
- Why do current 3D methods struggle with big, plain areas indoors (like white walls)?
- Can we automatically find flat surfaces in photos using words like “wall” or “floor” to guide the process?
- If we add strong, reliable hints about flatness and distance, can we recover better 3D surfaces that look and measure right?
How did they do it?
Think of a 3D scene as made up of many tiny, soft blobs called “Gaussians.” 3D Gaussian Splatting places and shapes these blobs so, when you look at them from a camera view, the image matches the real photo. This usually works well—except on big, texture-less areas (plain-colored walls) where the photos don’t give enough clues about true shape.
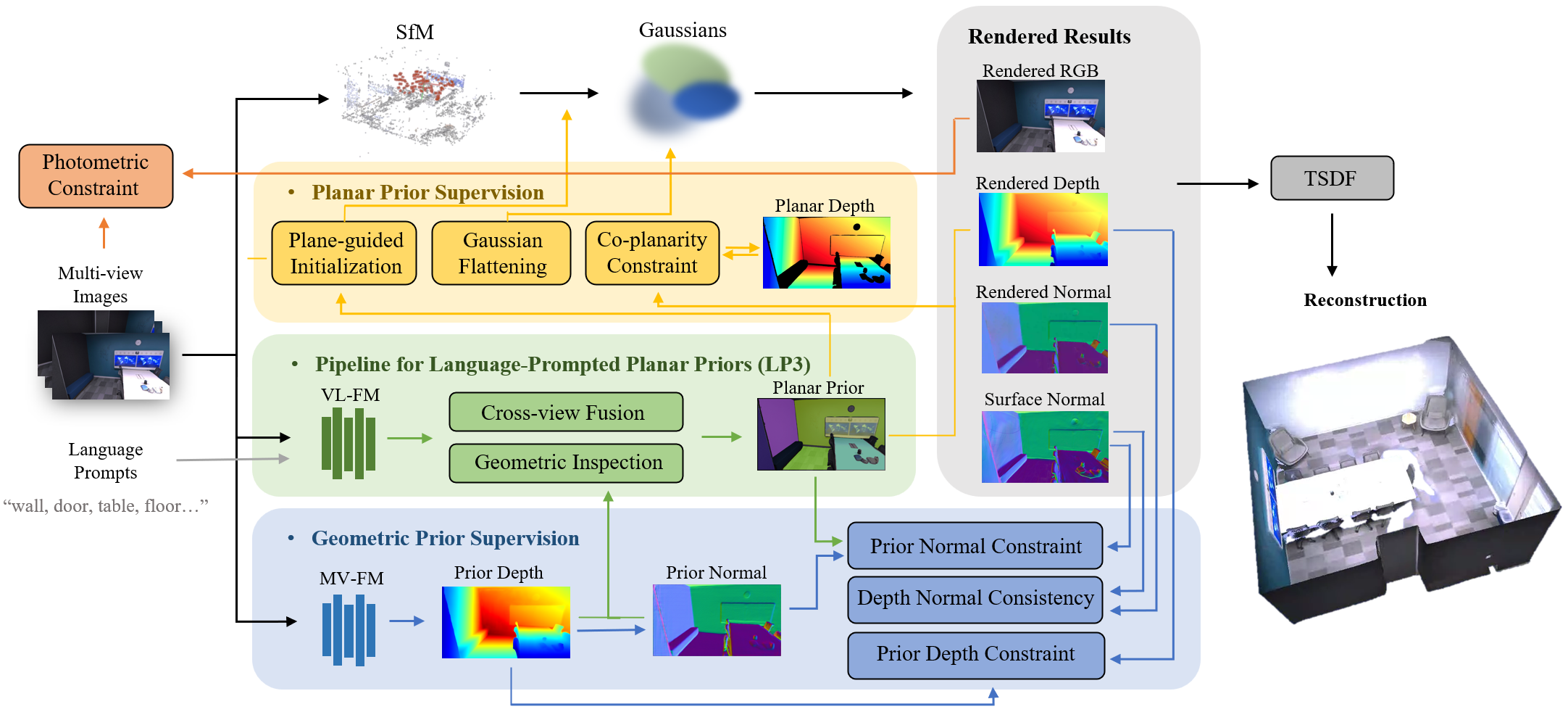
PlanarGS adds two types of helpful clues (“priors”) to fix this:
- Language-Prompted Planar Priors (LP3): finding flat areas using words
- A vision-LLM (a smart tool trained on huge datasets) is given simple prompts like “wall,” “floor,” “door,” “window,” “ceiling,” “table.”
- It marks those areas in each photo (like coloring all walls blue).
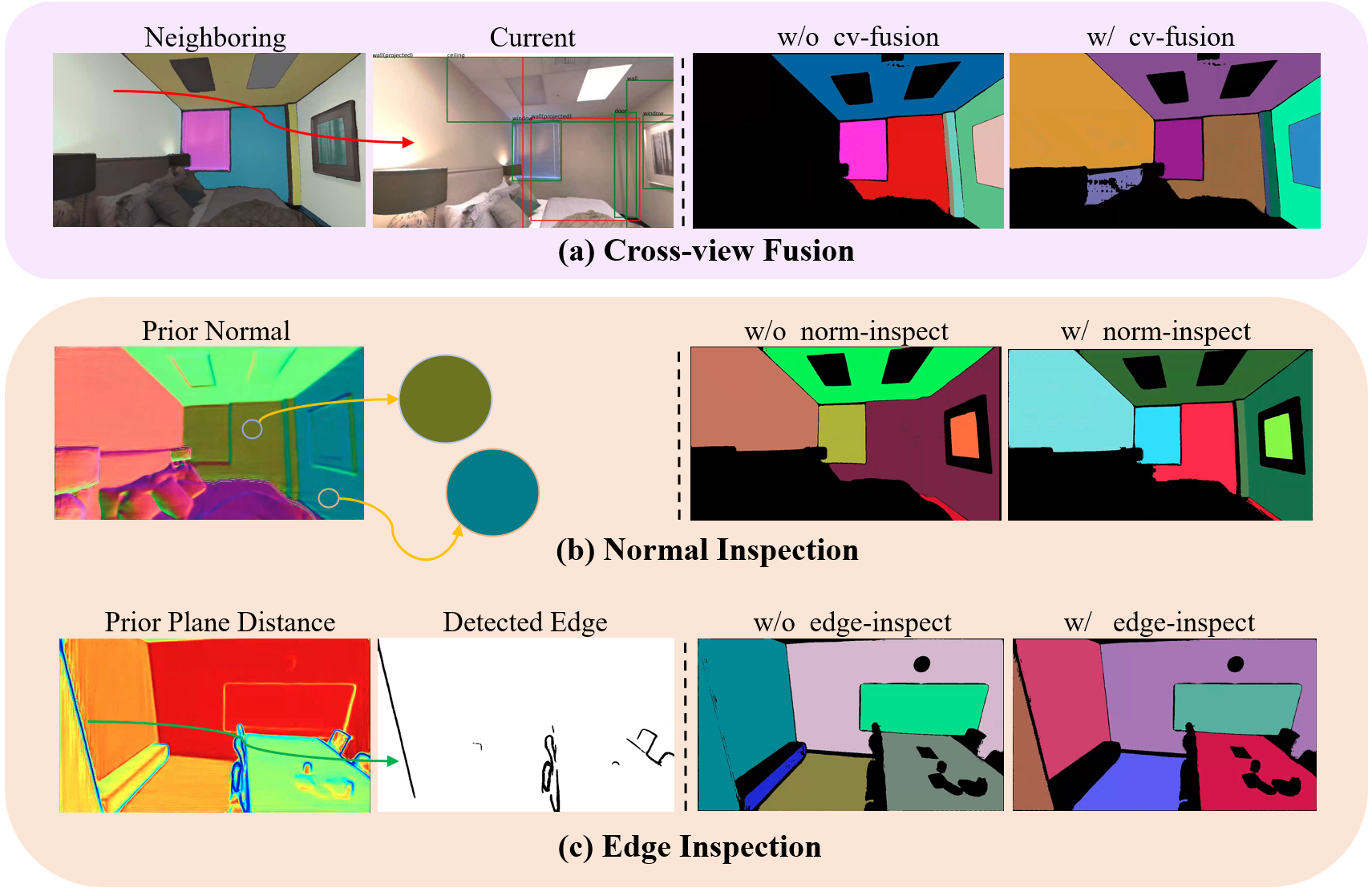
- Cross-view fusion: it checks the same surfaces across multiple photos to fix mistakes or missing parts.
- Geometric inspection: it uses extra 3D hints (depth and “normals,” which are little arrows pointing out from surfaces) to split merged planes and remove non-flat regions.
- Geometric Priors: adding 3D distance and surface direction hints
- A multi-view 3D foundation model called DUSt3R looks at photo pairs and estimates depth (how far things are) and normals (the direction a surface faces).
- These hints are consistent across views, so they’re more reliable than single-image guesses.
Once these hints are prepared, PlanarGS trains the 3D blobs with extra rules:
- Plane-guided initialization: add more blobs inside detected planes, especially where the usual method misses points (plain walls often lack features).
- Gaussian flattening: squish blob shapes so they lie flat like thin sheets on planes, making their depth and normals less ambiguous.
- Co-planarity constraint: force points in a plane region to fit one flat surface, so walls don’t end up wavy or curved.
- Depth and normal constraints: make the rendered depth and normals from the blobs agree with DUSt3R’s prior depth and normals.
- Consistency rule: ensure the blob-based normals align with the normals computed from depth, so positions and orientations match.
Analogy: imagine building a model room from semi-transparent stickers. The language prompts help you label stickers for walls and floors. DUSt3R tells you how far each sticker should be and which way it faces. Then you press the stickers flat and line them up so each wall is a proper sheet, not a crumpled surface.
What did they find and why it matters?
Across three indoor datasets (Replica, ScanNet++, MuSHRoom), PlanarGS:
- Reconstructed much more accurate 3D surfaces, especially on large, flat, low-texture areas like walls and floors.
- Outperformed several state-of-the-art methods by a large margin on surface quality metrics (like Chamfer Distance, F1 score, and Normal Consistency).
- Still produced high-quality rendered images for new viewpoints (good PSNR/SSIM/LPIPS).
- Trained in about an hour per scene, similar to other fast 3DGS methods.
Why it matters: Indoor spaces are full of big, flat, plain surfaces that confuse many 3D algorithms. Better reconstruction means smoother, straighter walls and consistent geometry. This helps applications in VR/AR, robotics (navigation and mapping), interior design, and digital twins, where both looks and measurements must be correct.
What could this mean for the future?
- Flexible scene understanding: because it uses word prompts, you can add new terms (like “blackboard” in a classroom) to detect new flat objects without retraining.
- Stronger 3D foundations: mixing language understanding with multi-view geometry gives robust, generalizable results.
- Practical impact: more reliable 3D models indoors could improve robot navigation, virtual tours, and realistic AR effects.
- Limitations: it focuses on flat, man-made structures. Curved walls or outdoor natural scenes (like forests) won’t benefit as much from “planar” hints. Future work could add other shape priors for curved or irregular surfaces.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, phrased to be concrete and actionable for future work.
- Quantify sensitivity to upstream errors: no analysis of how COLMAP pose inaccuracies or DUSt3R depth/normal errors propagate through LP3 and the co‑planarity constraints to affect final geometry; design controlled noise-injection studies and robustness metrics.
- Occlusion-aware fusion is missing: cross-view fusion reprojects plane masks without explicit occlusion handling; add ray consistency checks or depth-based visibility tests to prevent merging occluded or back-facing planar regions.
- Lack of ground-truth validation of planar priors: LP3 masks are not quantitatively evaluated against plane annotations (e.g., on PlaneNet/ScanNet with plane labels); establish plane segmentation precision/recall and over-/under-segmentation rates.
- Prompt selection remains manual and ad hoc: no automatic discovery or adaptation of prompts to new scenes; investigate CLIP-based prompt retrieval, caption-guided prompt generation, or active prompt refinement from reconstruction feedback.
- Limited generalization beyond indoor planar scenes: performance and failure modes on outdoor, non-Manhattan, curved, or organic environments are not explored; define extensions (e.g., piecewise planar, cylindrical or spline priors) and evaluate on non-indoor datasets.
- Uncertainty-aware priors are not modeled: LP3 treats plane masks largely as hard constraints; integrate uncertainty from GroundedSAM and DUSt3R (confidence maps, epistemic/aleatoric uncertainty) to weight losses and avoid over-constraining mis-segmented regions.
- Boundary handling is under-specified: co‑planarity may bleed across object-plane boundaries; study soft masks, edge-aware weighting, or boundary erosion/dilation strategies, and quantify effects on fine details near plane edges.
- Hyperparameter and schedule sensitivity: λ weights, group-wise scale/shift alignment, and staged introduction of losses are fixed; perform sensitivity analysis and propose adaptive schedules or learned weighting (e.g., via meta-learning or validation-driven controllers).
- Scale alignment robustness: group-wise scale/shift alignment to sparse SfM depth is assumed reliable; test cases with scarce/biased SfM points and explore global scale optimization, per-view alignment, or joint optimization of scale across all views.
- Compute and memory footprint: DUSt3R preprocessing requires a 48GB GPU and batched multi-view inference; report end-to-end runtime/memory, and explore lightweight alternatives (e.g., VGGT, monocular priors with view-consistency post-hoc) and scalability to thousands of images.
- Real-time/online operation: pipeline is offline; develop incremental LP3 fusion and streaming Gaussian updates for SLAM-style online reconstruction, and evaluate latency/accuracy trade-offs.
- Pose error resilience: no experiments on perturbed or low-quality pose estimates (e.g., low-texture scenes where SfM struggles); assess joint optimization of poses with Gaussians or pose refinement using priors.
- Reflective/transparent surfaces: performance on specular/transparent planes (windows, glass doors) is not studied; integrate reflection-aware rendering or specialized priors and evaluate NVS artifacts in such regions.
- Degeneracy of Gaussian flattening: minimizing min(s1, s2, s3) can produce degenerate covariances and oversimplify local geometry; analyze degeneracy cases and propose constraints on anisotropy or curvature-aware flattening.
- Failure mode analysis for mis-segmentation: while ablations show benefits of LP3, systematic characterization of errors when plane masks merge perpendicular planes or include clutter is lacking; create benchmarks and mitigation strategies (e.g., normal-distance clustering thresholds).
- Planar prior coverage: large planes spanning image boundaries are addressed via fusion, but small, fragmented planes (e.g., shelves, panels) remain under-discussed; evaluate detection/coverage of small planar patches and refine clustering to avoid over-/under-merging.
- Integration of semantic hierarchies: LP3 relies on category prompts but does not exploit structural relations (Manhattan/Atlanta constraints or room layout priors); study hybrid semantic–structural constraints and their impact on global consistency.
- Mesh extraction choices: only TSDF fusion is used; compare Poisson, screened Poisson, or Gaussian-to-mesh conversions and quantify differences in planarity, normal consistency, and small-detail preservation.
- NVS trade-offs: while PSNR/SSIM/LPIPS are reported, the impact of strong geometry priors on view-dependent effects (specularity, reflections) and temporal consistency/flicker is not analyzed; include perceptual and temporal metrics.
- Dynamic scenes: method assumes static environments; investigate robustness to minor scene changes (moving objects/people) and extend LP3 and optimization for dynamic segments with motion-aware masks.
- Camera calibration assumptions: intrinsic/extrinsic accuracy is assumed; explore self-calibration or robustness to calibration errors, especially for consumer devices with rolling shutter or lens distortion.
- Automatic loss scheduling: staged introduction (e.g., co‑planarity at 14k iters) is heuristic; design criteria to trigger constraints based on convergence or confidence signals (e.g., prior agreement), and measure impacts across scenes.
- Cross-dataset generalization: evaluation covers Replica, ScanNet++, and MuSHRoom with limited scene diversity; broaden to varied indoor domains (industrial, museums) and report generalization with unchanged prompts and hyperparameters.
- Joint adaptation of foundation models: DUSt3R and GroundedSAM are frozen; study scene-aware fine-tuning or adapter training to improve view-consistency and segmentation for specific environments without sacrificing generalization.
- Piecewise-planar modeling for curved walls: explicit limitation notes no improvement for curved walls; explore local planar patches with smooth continuity constraints or parametric curved surfaces (B-splines) and integrate into Gaussian optimization.
Glossary
- 3D Gaussian Splatting (3DGS): An explicit point-based 3D scene representation that optimizes Gaussian parameters to render images from novel views. "Three-dimensional Gaussian Splatting (3DGS) has recently emerged as an efficient representation for novel-view synthesis, achieving impressive visual quality."
- Alpha-blending: A compositing technique that blends contributions from multiple primitives along a ray using their opacities. "Rendering color C of a pixel can be given by α-blending~\citep{kopanas2022neural}:"
- Atlantaworld assumption: A structural prior that generalizes Manhattan-world by allowing multiple dominant plane directions. "and another method~\citep{10476755} relaxes the constraints to the Atlantaworld assumption."
- Chamfer Distance (CD): A bidirectional distance measure between point sets used to evaluate surface reconstruction accuracy. "we report Accuracy (Acc), Completion (Comp), and Chamfer Distance (CD) in cm."
- COLMAP: A popular SfM/MVS toolkit for estimating camera poses and sparse 3D points from images. "We use COLMAP~\citep{schonberger2016structure} for all these scenes to generate a sparse point cloud as initialization."
- Co-planarity constraint: An optimization constraint enforcing points or surfaces in a region to lie on a single plane. "we apply the co-planarity constraint on the depth map."
- Cross-view fusion: Aggregating detections or masks across multiple viewpoints via geometric reprojection to improve completeness. "we employ cross-view fusion to supplement bounding box proposals."
- Depth-normal consistency regularization: A loss encouraging normals derived from depth to agree with Gaussians’ normals and orientations. "we introduce the depth normal consistent regularization between rendered GS-normal $\hat{\bm{N}$ and rendered surface-normal $\hat{\bm{N}_d$ to optimize the rotation of Gaussians consistent with their positions:"
- DUSt3R: A pretrained multi-view 3D foundation model that predicts view-consistent depth and normals. "we employ DUSt3R~\citep{wang2024dust3r}, a pretrained multi-view 3D foundation model, to extract the depth and normal maps from neighboring images."
- F-score (F1): The harmonic mean of precision and recall computed under a distance threshold for reconstructed surfaces. "F-score (F1) with a 5cm threshold and Normal Consistency (NC) are reported as percentages."
- Gaussian flattening: Making Gaussians thin along one axis (their normal) to better approximate planar surfaces. "Our planar prior supervision includes plane-guided initialization, Gaussian flattening, and the co-planarity constraint, accompanied by geometric prior supervision."
- GroundedSAM: A vision-language segmentation framework combining grounding with SAM for promptable segmentation. "our pipeline for Language-Prompted Planar Priors (abbreviated as LP3) employs a vision-language foundation model GroundedSAM~\citep{ren2024grounded}"
- Jacobian: The matrix of partial derivatives used to locally linearize a transformation for covariance projection. "J is the Jacobian of the affine approximation of the projective transformation."
- K-means clustering: An unsupervised method for partitioning data (e.g., normals) into clusters to separate plane groups. "We apply the K-means clustering to partition the prior normal map to separate non-parallel planes."
- LPIPS: A learned perceptual image similarity metric used to evaluate rendering quality. "we follow standard PSNR, SSIM, and LPIPS metrics for rendered images."
- Manhattan-world assumption: A structural prior assuming dominant planes align with three orthogonal axes. "enforces a Manhattan-world assumption~\citep{coughlan1999manhattan} by constraining floors and walls to axis-aligned planes"
- Multi-view geometric consistency: A constraint enforcing that geometry inferred from different views agrees across viewpoints. "applies the multi-view geometric consistency constraint to enhance the smoothness in areas with weak textures."
- Multi-view stereo (MVS): Techniques that estimate dense depth from multiple images via correspondence and matching. "Multi-view stereo (MVS)~\citep{bleyer2011patchmatch,schonberger2016pixelwise,yao2018mvsnet,luo2016efficient} generates dense depth maps from multi-view images via dense image matching"
- Neural Radiance Field (NeRF): An implicit 5D radiance field representation trained via volume rendering of posed images. "Neural Radiance Field (NeRF)~\citep{mildenhall2021nerf} utilizes a multilayer perceptron (MLP) to model a 3D scene as a continuous 5D radiance field optimized via volumetric rendering of posed images."
- Normal Consistency (NC): A metric measuring the agreement of reconstructed surface normals with ground truth. "F-score (F1) with a 5cm threshold and Normal Consistency (NC) are reported as percentages."
- Photometric loss: An image-space loss on color/intensity used to supervise reconstruction from photographs. "the photometric loss used to optimize 3DGS yields ambiguous geometry and fails to recover high-fidelity 3D surfaces."
- Plane-distance map: A per-pixel map of distances from local planes to the camera used for geometric inspection. "we then express the distance from the local plane to the camera as and get a prior plane-distance map ."
- Plane-guided initialization: Densely seeding Gaussians on detected planar regions using back-projected depth to improve coverage. "Our planar prior supervision includes plane-guided initialization, Gaussian flattening, and the co-planarity constraint"
- PSNR: Peak Signal-to-Noise Ratio, an image fidelity metric for rendered views. "we follow standard PSNR, SSIM, and LPIPS metrics for rendered images."
- SAM (Segment Anything Model): A segmentation model that produces masks from various prompts. "We also replace the vision-language foundation model with YoloWorld~\citep{cheng2024yolo} and SAM~\citep{kirillov2023segment}"
- Scale-and-shift correction: Aligning dense depth predictions to sparse SfM depth via a global scale and offset. "For low-texture regions, we constrain the rendered depth to match the scale-and-shift corrected prior depth"
- Structure-from-Motion (SfM): A pipeline that recovers camera motion and sparse 3D points from image sequences. "structure-from-motion (SfM)~\citep{schonberger2016structure} is used to recover camera poses and sparse 3D points by matching feature points across different views."
- TSDF fusion: Mesh reconstruction by integrating Truncated Signed Distance Fields over views. "the high-fidelity 3D mesh can be recovered from the rendered depth maps from PlanarGS via TSDF fusion~\citep{lorensen1998marching,newcombe2011kinectfusion}."
- VGGT: A fast multi-view foundation model alternative used to obtain geometric priors. "The multi-view foundation model can be substituted with VGGT~\citep{wang2025vggt}, allowing this stage to be completed within a few seconds."
- Vision-language segmentation model: A model that segments images conditioned on text prompts for semantic control. "we employ a pretrained vision-language segmentation model~\citep{ren2024grounded} prompted with terms such as "wall", "door", and "floor"."
- Volumetric rendering: Integrating radiance and density along rays through a continuous volume to synthesize images. "optimized via volumetric rendering of posed images."
- YoloWorld: An open-vocabulary detection model used for prompt-based object detection to seed segmentation. "We also replace the vision-language foundation model with YoloWorld~\citep{cheng2024yolo} and SAM~\citep{kirillov2023segment}"
Practical Applications
Immediate Applications
The following applications can be deployed now with the methods, priors, and workflow described in the paper. Each item notes sectors, potential products/workflows, and feasibility assumptions or dependencies.
- High-fidelity indoor digital twins for as-built capture and inspection (AEC, facilities management, real estate)
- What: Produce accurate, hole-free meshes of indoor spaces with planar consistency (walls, floors, ceilings) for as-built documentation, clash detection, space planning, and 3D tours.
- Workflow/tools: Multi-view capture (phone/DSLR), COLMAP for SfM, DUSt3R or VGGT for multi-view depth/normal, GroundedSAM (or YOLOWorld+SAM) with prompts ("wall, floor, door, window, ceiling, table") through LP3 fusion, train PlanarGS (~30k iters, ~1 hour on RTX 3090), TSDF mesh fusion, export GLB/USDZ for CAD/BIM/Unreal/Unity.
- Assumptions/dependencies: Static indoor scenes with large planar regions; adequate image overlap and coverage; GPU availability; foundation model licenses; not optimized for curved geometry or outdoor scenes; scale alignment via sparse SfM.
- AR/VR occlusion meshes and scene understanding for indoor experiences (software, gaming, education, retail)
- What: Generate clean, co-planar occluders for AR overlays and accurate collision and lighting surfaces in VR.
- Workflow/tools: Integrate PlanarGS as a preprocessing step in content pipelines, export simplified plane-aware meshes to ARKit/ARCore/Unity/Unreal; prompt extension for domain-specific planes (e.g., “blackboard”, “glass partition”).
- Assumptions/dependencies: Indoor environments; acceptable latency (offline preprocessing); quality depends on prompt coverage and multi-view capture.
- Robot mapping and navigation with plane-aware geometry (robotics, warehousing, service robots)
- What: Improve global planarity and surface smoothness over traditional 3DGS for reliable path planning, obstacle inflation, and semantic map generation (e.g., wall/door detection).
- Workflow/tools: Use PlanarGS to reconstruct spaces from onboard camera logs; integrate meshes into ROS/ROS2 costmaps and semantic navigation stacks; optional LP3 prompts to include task-specific planes (e.g., “shelf”, “gate”).
- Assumptions/dependencies: Mostly static scenes; indoor spaces; sufficient visual coverage; compute offboard or on a base station; DUSt3R/VGGT inference available.
- Insurance, claims, and property documentation (finance, real estate, public safety)
- What: Create accurate 3D records of interiors post-incident or pre-coverage, enabling measurement (wall/floor areas), damage assessment, and cost estimation.
- Workflow/tools: Mobile photo capture, PlanarGS reconstruction, measurement tools on exported mesh; enterprise pipeline integration.
- Assumptions/dependencies: Documented capture protocols (lighting, coverage); measurement tolerance acceptable for claims (typ. cm-level); compliance/privacy controls for foundation models.
- Interior design, furnishing, and home improvement (consumer apps, retail)
- What: Room measurement, wall/floor area estimation, and accurate virtual furniture placement using plane-consistent meshes.
- Workflow/tools: “Plane-aware 3D scanner” feature in mobile apps; PlanarGS run in the cloud; exports to room planners and AR visualizers.
- Assumptions/dependencies: Adequate photos; offline processing acceptance by users; fails gracefully on curved surfaces.
- Store layout and planogram validation (retail operations)
- What: Validate aisle width, display placement, and wall/floor geometry using robust planar reconstructions.
- Workflow/tools: Scheduled image capture, PlanarGS pipeline, analytics dashboard for deviations; prompts can include “endcap”, “counter”, “display”.
- Assumptions/dependencies: Consistent imaging; curated prompts; compute budget for batch processing.
- Museum/cultural heritage indoor digitization (media, culture)
- What: High-fidelity reconstructions of galleries/halls where planar constraints improve surface quality and reduce artifacts.
- Workflow/tools: Structured capture, PlanarGS mesh generation, publishing to web viewers or VR experiences.
- Assumptions/dependencies: Static scenes; indoor lighting; object-level reconstruction of curved artifacts still relies on photometric cues (no planar prior).
- Data generation for research and benchmarking (academia)
- What: Create indoor ground-truth-like meshes for evaluating SLAM, depth/normal estimation, and AR occlusion without laser scans.
- Workflow/tools: Standard capture sets, PlanarGS outputs as pseudo-GT; leverage LP3 for broad scene categories by swapping prompts.
- Assumptions/dependencies: Quality depends on SfM/DUSt3R accuracy; valid for indoor planar regions; clearly stated limitations vs LiDAR GT.
- Compliance pre-checks and accessibility audits (policy, AEC, public sector)
- What: Preliminary checks of hallway widths, door sizes, and plane deviations from vertical/horizontal for accessibility and safety pre-assessments.
- Workflow/tools: PlanarGS reconstruction; analytic scripts to detect plane normals, distances, openings; reports vs threshold criteria.
- Assumptions/dependencies: cm-level tolerances; not a certified measurement substitute; requires controlled capture; curved ramps and non-planar features not fully supported.
- Pipeline components reusable as product modules (software tooling)
- What: LP3 as a “language-prompted plane segmentation” SDK; “plane-guided densification” plugin for 3DGS; “DUSt3R-aligned depth prior” module.
- Workflow/tools: Package LP3 with GroundedSAM/YOLOWorld+SAM; provide ROS/Unity/Unreal plugins; API for batched reconstruction.
- Assumptions/dependencies: Model weights redistribution policy; GPU/VRAM needs; fallbacks to VGGT for faster inference.
Long-Term Applications
The following require further research, scaling, or algorithmic extensions beyond the current method (e.g., robust handling of curved/outdoor scenes, real-time performance, dynamic objects).
- Real-time, on-device plane-aware reconstruction for AR and robotics (software, robotics)
- Vision: Streamed PlanarGS-like performance on mobile GPUs or edge devices for instant occlusion/collision meshes.
- Needed advances: Lightweight multi-view priors (or learned online priors), memory-lean LP3, incremental optimization, and hardware acceleration.
- Dependencies: Mobile-friendly foundation models; efficient SfM/SLAM integration; thermal/power constraints.
- Unified indoor SLAM with PlanarGS priors (robotics)
- Vision: Jointly estimate poses, depth/normal priors, and Gaussians with co-planarity in a single, online SLAM loop for robust navigation and mapping.
- Needed advances: Tightly coupled optimization, loop closure with plane constraints, dynamic scene handling.
- Dependencies: Robust online DUSt3R/VGGT variants; drift-aware priors; real-time plane prompting.
- CAD/BIM-from-reconstruction pipelines with parametric plane extraction (AEC)
- Vision: Convert PlanarGS meshes into parametric CAD/BIM elements (walls, slabs, doors) with tolerances and metadata.
- Needed advances: Robust instance segmentation of planar elements, topology reasoning, doorway/window extraction, IFC/Revit pluginization.
- Dependencies: Stronger semantics (vision-language) beyond plane detection; standardized QA for code compliance.
- Indoor analytics at scale (retail, real estate, smart buildings)
- Vision: Fleet-scale processing of large property portfolios for change detection, inventory mapping, and occupancy planning.
- Needed advances: Batch orchestration, automatic prompt tuning by scene type, drift detection, results harmonization.
- Dependencies: Cloud compute budgets; governance for foundation model usage; data privacy pipelines.
- Safety compliance and formal inspections (policy, regulation)
- Vision: Certified measurement-grade reconstructions for fire code and accessibility compliance verification.
- Needed advances: Verified accuracy bounds across devices and conditions; calibration protocols; third-party validation and standards.
- Dependencies: Legal acceptance; robust handling of non-planar features; documentation chains.
- Energy modeling and retrofits planning from scans (energy, sustainability)
- Vision: Derive room volumes, envelope areas, and adjacency relations for HVAC/lighting simulations directly from plane-accurate meshes.
- Needed advances: Robust material/reflectance cues, window/door leakage modeling, automatic zone partitioning.
- Dependencies: Coupling to energy simulation software; semantic enrichment; validated accuracy for engineering use.
- Domain-specialized plane taxonomies via language prompts (healthcare, manufacturing)
- Vision: Prompt libraries for sector-specific planes (e.g., “operating table”, “cleanroom partition”, “conveyor guard”) to accelerate domain reconstructions and audits.
- Needed advances: Curated vocabularies, prompt disambiguation, cross-view fusion tuned for thin/reflective/transparent planes.
- Dependencies: Dataset curation; improved VLM segmentation for rare classes; safety/privacy constraints in sensitive environments.
- Outdoor/complex geometry generalization (construction sites, infrastructure)
- Vision: Extend planarity priors to “near-planar” and curved primitives (cylinders, NURBS), and handle large-scale outdoor scenes.
- Needed advances: Primitive detection beyond planes, multi-scale priors, robust handling of texture-poor, repetitive facades under variable illumination.
- Dependencies: New priors and constraints; outdoor-tuned foundation models; scalable optimization.
- Human-in-the-loop reconstruction QA and editing tools (software, creative industries)
- Vision: Interactive tools to accept/reject plane proposals, adjust co-planarity constraints, and refine meshes for production.
- Needed advances: UI/UX for editing LP3 outputs, fast re-optimization, semantic consistency checks.
- Dependencies: Authoring tool integrations (Blender, Maya, Revit); reproducible pipelines.
- Privacy-preserving and on-prem deployments (public sector, regulated industries)
- Vision: On-prem or federated PlanarGS with self-hosted foundation models and strict data controls.
- Needed advances: Efficient self-hosted alternatives to cloud FMs, reduced VRAM footprints, audit tooling.
- Dependencies: Enterprise IT constraints; model licensing; compute provisioning.
Notes on Feasibility and Dependencies (cross-cutting)
- Compute: Current pipeline assumes access to a capable GPU (e.g., RTX 3090 for PlanarGS training; A6000 for DUSt3R batches). VGGT can substitute DUSt3R for faster, lower-memory depth priors with some quality trade-offs.
- Data capture: Requires multi-view images with sufficient overlap and static scenes. Camera intrinsics/poses (SfM) must be reliable; lighting stability helps.
- Scene priors: Method excels in indoor, planar-dominant spaces; limited gains on curved or highly cluttered non-planar regions; outdoor performance is not a target.
- Foundation models: Quality and generalization depend on GroundedSAM/YOLOWorld+SAM and DUSt3R/VGGT; prompts must cover domain-specific planes. Licensing and privacy policies apply.
- Accuracy: Reported cm-level reconstruction improvements and strong plane consistency; for regulated uses (e.g., compliance), formal calibration/validation is needed.
- Integration: Outputs are meshes and rendered depth/normal; plug-ins can target Unity/Unreal, ROS, and BIM tools; TSDF fusion is part of the default workflow.
Collections
Sign up for free to add this paper to one or more collections.

