JanusCoder: Towards a Foundational Visual-Programmatic Interface for Code Intelligence
Abstract: The scope of neural code intelligence is rapidly expanding beyond text-based source code to encompass the rich visual outputs that programs generate. This visual dimension is critical for advanced applications like flexible content generation and precise, program-driven editing of visualizations. However, progress has been impeded by the scarcity of high-quality multimodal code data, a bottleneck stemming from challenges in synthesis and quality assessment. To address these challenges, we make contributions from both a data and modeling perspective. We first introduce a complete synthesis toolkit that leverages reciprocal synergies between data modalities to efficiently produce a large-scale, high-quality corpus spanning from standard charts to complex interactive web UIs and code-driven animations. Leveraging this toolkit, we construct JanusCode-800K, the largest multimodal code corpus to date. This powers the training of our models, JanusCoder and JanusCoderV, which establish a visual-programmatic interface for generating code from textual instructions, visual inputs, or a combination of both. Our unified model is a departure from existing approaches that build specialized models for isolated tasks. Extensive experiments on both text-centric and vision-centric coding tasks demonstrate the superior performance of the JanusCoder series, with our 7B to 14B scale models approaching or even exceeding the performance of commercial models. Furthermore, extensive analysis provides key insights into harmonizing programmatic logic with its visual expression. Our code and checkpoints will are available at https://github.com/InternLM/JanusCoder.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper introduces JanusCoder, a new kind of AI that can understand both words and pictures to write computer code that creates visuals. Think charts, webpages, and even math animations. The team also built a huge, high-quality training set (called JanusCode-800K) and a toolkit to generate and check this kind of data. Together, these let the AI turn instructions or images—or both—into working code that produces the right visual results.
What questions the researchers asked
- Can one general-purpose model (instead of many specialized ones) handle lots of visual coding jobs, like:
- making charts from text,
- rebuilding a chart from an image (chart-to-code),
- creating/editing webpages from screenshots and instructions,
- making interactive scientific demos and math animations?
- How can we build enough good training data that connects words, code, and visuals so the model learns both logic (the code) and appearance (the look on screen)?
- How do we check that the code not only runs but also looks right and follows the instructions?
How they did it (methods explained simply)
The team built two big pieces: a data toolkit and the JanusCoder models.
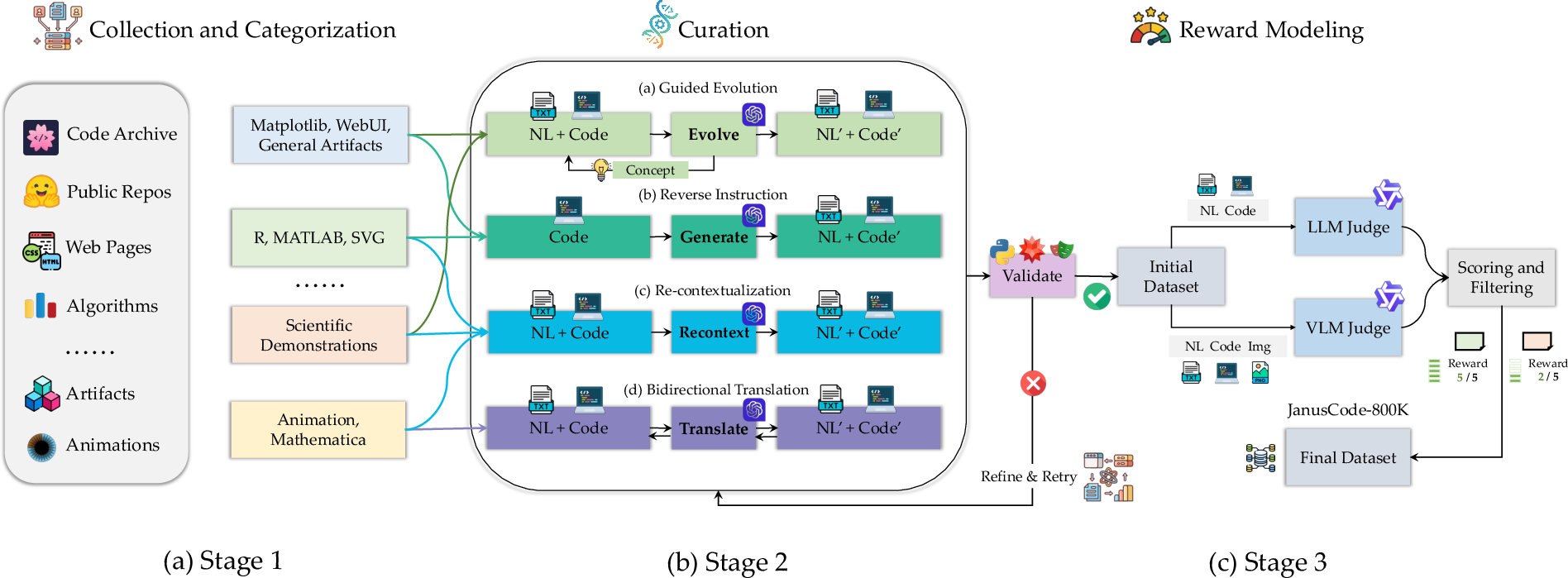
- A data toolkit to create and clean training data Think of it like a factory that:
- collects code and examples from many places (charts, web UIs, SVG graphics, Manim animations, Mathematica demos),
- writes new, realistic tasks and matching solutions,
- runs the code in a safe “sandbox” to make sure it works,
- then uses an AI judge to rate how well the visual output matches the instructions.
To make lots of varied, high-quality training pairs (instruction, code, visual), they used four simple strategies:
- Guided Evolution: Start with an example and “grow” it by asking for changes based on a concept (like “switch to a bar chart” or “add a button”).
- Re-Contextualization: Read the code first, then write a better, clearer instruction that truly matches what the code does.
- Reverse Instruction: See a code snippet and write a believable instruction that would lead to it—like writing a quiz question from the answer.
- Bidirectional Translation: Translate an idea between languages or tools (e.g., from Manim to Mathematica and back) so the same concept is learned in multiple coding “dialects.”
They also do two kinds of quality checks:
- Execution check: Does the code run and produce an image/page/animation?
- AI judge check: Does the result actually match the instruction and look clear? (This prevents “it runs, but it’s wrong.”)
- The JanusCoder models
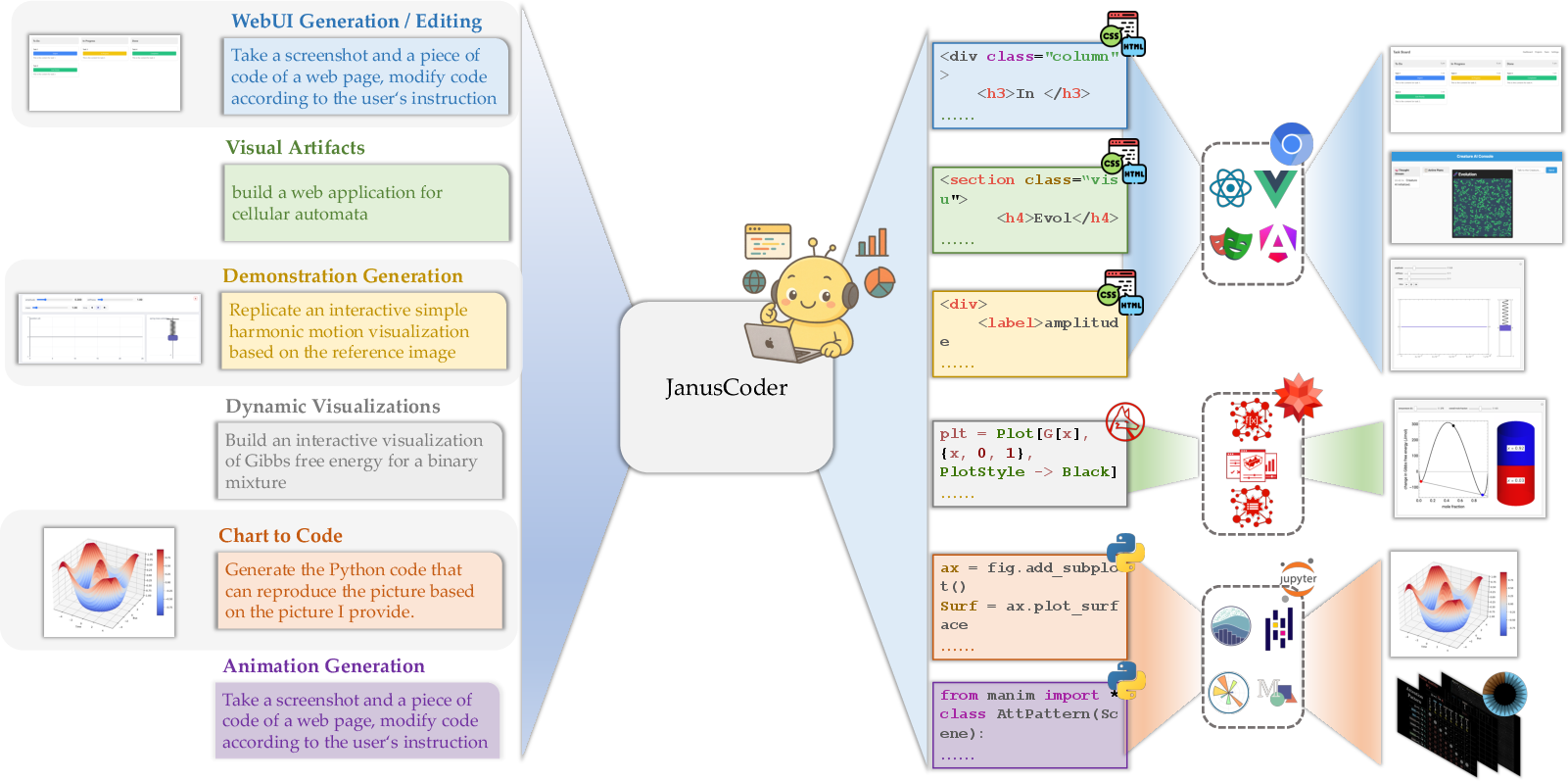
- JanusCoder: focuses on text-to-code tasks (you type an instruction; it writes code that produces a visual).
- JanusCoderV: handles text plus images (for example, you show it a chart and it writes the code to recreate it).
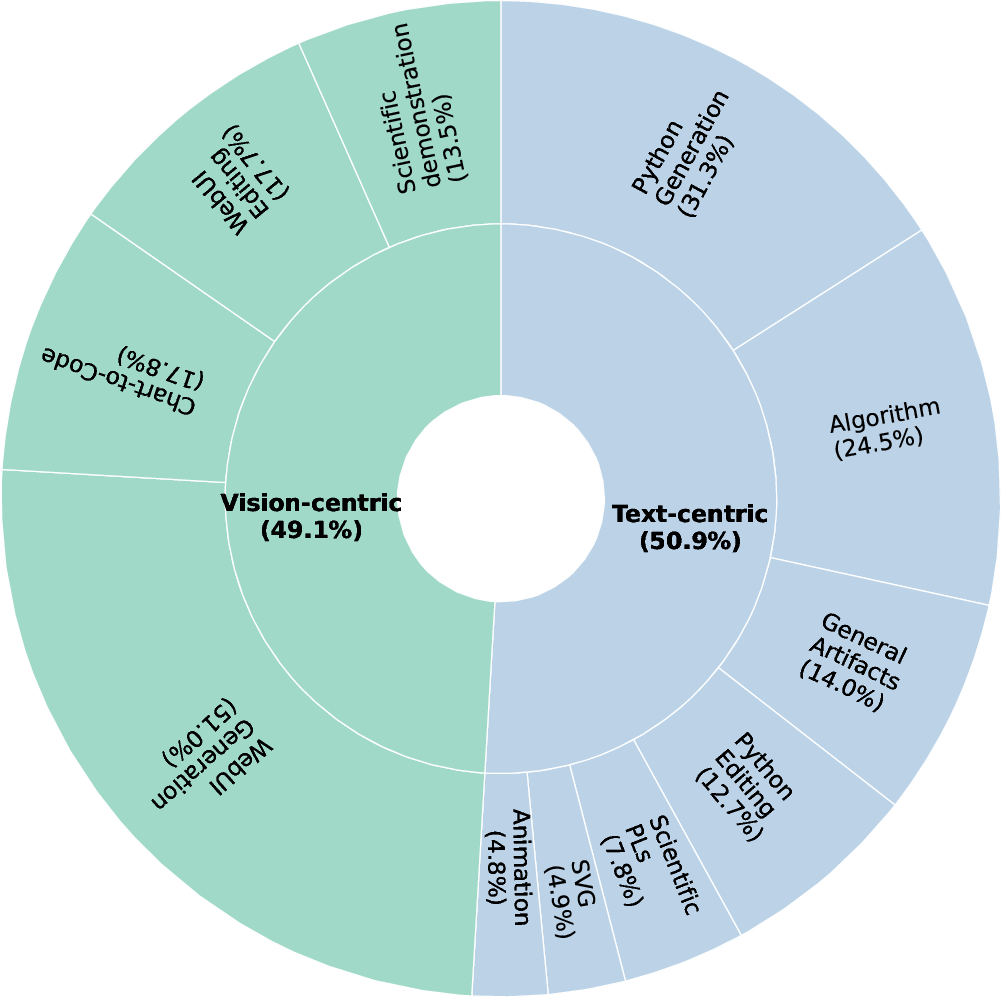
- Both are trained on JanusCode-800K, an 800,000-sample dataset that mixes charts, web UIs, SVGs, animations, and scientific demos.
They also introduce a new test called DTVBench for dynamic theorem visualizations (math animations in Manim and interactive Mathematica demos). It checks whether the model can turn instructions into correct, working, and visually faithful math explanations.
What they found and why it matters
- One unified model can do many visual coding tasks well. Instead of building separate models for charts, web UIs, and animations, JanusCoder handles them all.
- Strong performance across the board:
- Chart-making from text,
- Chart-to-code from images,
- Webpage generation and editing from screenshots,
- Interactive science demos,
- Math animations.
- In many tests, their 7–14B models reach or beat popular commercial systems on visual coding tasks.
- The data toolkit and quality checks really help. Ablation studies (turning parts off) show that:
- Cross-domain data (like learning from R/Matlab/Mathematica/Manim/SVG) improves skills even outside the original domain.
- Reward modeling (the AI judge step) filters out “bad but runnable” code and boosts results.
- The new DTVBench shows these models can produce not just static pictures but also dynamic, educational visuals—like short math animations that explain a concept.
Why this is important:
- It bridges code logic (the “how”) and visual appearance (the “what you see”). That’s critical for real apps: data journalism charts, dashboards, website design, interactive science demos, and educational animations.
What this could change (implications)
- Fewer specialized tools: Developers, designers, teachers, and students could use one model to go from idea → code → working visuals across many formats.
- Faster prototyping: You can show a screenshot or describe what you want, and the model writes the code to recreate or edit it.
- Better learning tools: Creating clear math animations and interactive demos becomes easier, helping explain hard topics.
- Strong open-source base: The released dataset, code, and models give the community a common starting point to build better visual-programming AI.
In short: JanusCoder shows that one well-trained, well-checked AI can understand instructions and images and write the right code to make visuals—charts, webpages, and animations—bringing us closer to flexible, “see-and-code” tools for education, science, and design.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a targeted list of unresolved issues and limitations that future work could concretely address:
- Reliability of VLM/LLM-based quality control
- The reward model relies on large VLMs/LLMs (e.g., Qwen2.5-VL-72B, Qwen3-235B) to judge code–visual alignment; the calibration, inter-rater reliability, and bias of these automated judges are not quantified.
- No human–AI agreement study or adjudicated gold standard is provided to validate that reward scores reflect true task satisfaction, especially for nuanced visual semantics.
- Executability versus semantic correctness
- Passing execution checks is treated as a gate for quality, but the paper acknowledges executability is insufficient; there is no systematic assessment of cases where code executes yet violates data semantics (e.g., wrong chart axes, misleading scales).
- For Web UI tasks, functional behavior beyond rendering (e.g., event handling correctness, edge-case interactions) is weakly evaluated.
- Evaluation metrics for dynamic and interactive content
- DTVBench scoring depends heavily on GPT-4o and optional subjective ratings; no standardized, reproducible metrics for temporal coherence, interaction fidelity, or animation semantics are established.
- The benchmark is small (102 tasks), limiting statistical power and generalizability; there is no inter-annotator agreement reporting for subjective scores.
- Potential data leakage and benchmark contamination
- Several training sources overlap conceptually with evaluation domains (e.g., WebCode2M, visualization corpora), but the paper does not detail de-duplication, near-duplicate filtering, or temporal splits to prevent leakage into benchmarks.
- No audit quantifies overlap between JanusCode-800K and test benchmarks (ChartMimic, WebCode2M, DesignBench, etc.).
- Scope of domain and modality coverage
- Important modalities and toolchains are missing or underrepresented, such as 3D graphics (WebGL/Three.js), D3/Plotly/ggplot, native/mobile GUIs, AR/VR, audio-visual program synthesis, or robotics visualization pipelines.
- Generalization to unseen DSLs or libraries is not directly evaluated (out-of-library transfer).
- Translation fidelity across programming languages and engines
- Bidirectional translation (e.g., Manim ↔ Mathematica) lacks formal guarantees or quantitative tests of semantic preservation; error modes (loss of mathematical meaning, layout, or interaction) are not analyzed.
- No ablation isolates translation quality versus instruction rewriting quality.
- Multi-turn and persistent state editing
- Editing tasks are framed as single-turn transformations; there is no evaluation of multi-step, stateful editing where successive changes must remain coherent and reversible.
- The impact of history/context length and recovery from earlier mistakes in iterative editing is unexplored.
- Robustness and distribution shift
- Robustness to noisy or imperfect inputs (e.g., low-resolution, occluded, compressed, color-shifted images; screenshots with overlays) is not evaluated.
- No adversarial or stress tests (ambiguous or conflicting instructions, adversarial prompts) are included to probe failure modes.
- Safety and security of code execution
- The sandboxing/execution environment E is not described in detail (capabilities, syscall/network restrictions, filesystem isolation, time/memory limits), leaving uncertainty about safety of running untrusted code at scale.
- There is no security audit of generated web code (e.g., XSS, unsafe inline scripts), nor checks for unsafe libraries or patterns.
- Interpretability and alignment
- How the model aligns visual features to code structures is not probed (e.g., attention analysis, token–region attribution); no diagnostics for spurious correlations.
- The system does not provide edit provenance or rationale linking specific code changes to visual changes for user trust and debuggability.
- Reward modeling design and thresholds
- The choice of reward dimensions and their aggregation (equal weighting) is not justified; no sensitivity analysis on thresholds or per-domain recalibration is provided.
- The effect of noisy or biased reward signals on downstream model behavior is not quantified.
- Data synthesis pipeline validation
- Guided evolution and re-contextualization may compound small errors across iterations; the paper does not track error propagation or provide stopping/rollback criteria.
- Reverse-instruction generation may produce mismatched or underspecified prompts; coverage and failure rates are not reported.
- Ablation granularity and causal attribution
- Ablations remove coarse categories (e.g., “w/o Text-centric”), but do not control for total token budget or instruction complexity; causal attribution of gains to specific strategies remains uncertain.
- Cross-domain synergy claims are promising but not dissected to identify which pairings (e.g., SVG → Web UI, R/Matlab → Manim) contribute most.
- Model scaling and data scaling laws
- Results stop at ~14B parameters; there is no analysis of how performance scales with model size versus data size/composition, nor of diminishing returns.
- The interplay between data quality (rewarded vs. unrewarded) and model capacity is not systematically studied.
- Generalization beyond snapshots to live data and tooling
- Tasks generally target static inputs/outputs; there is no evaluation of code that integrates live data sources, asynchronous events, or external APIs.
- Tool-augmented or agentic settings (planning, tool calling, verification loops) are not explored.
- Accessibility, responsiveness, and standards compliance
- Web UI generation is not assessed for accessibility (ARIA, keyboard navigation), responsiveness (mobile/desktop breakpoints), or standards compliance.
- No metrics or tests verify code maintainability (modularity, CSS/JS hygiene) or performance (layout thrashing, heavy reflows).
- Licensing and reproducibility concerns
- The corpus aggregates diverse sources (e.g., Wolfram demonstrations, The Stack V2, WebCode2M); licensing compatibility and redistribution rights for JanusCode-800K are not fully clarified.
- Heavy reliance on proprietary models for data synthesis (gpt-oss-120b) and judging (GPT-4o) challenges strict reproducibility and cost-effective replication.
- Environmental and system reproducibility
- Rendering and execution are sensitive to library and browser versions; the paper does not provide containerized specs or version locks ensuring reproducible results across machines.
- No reporting of computational cost, energy usage, or carbon footprint; efficiency trade-offs and latency constraints (especially for animation rendering) are not discussed.
- Benchmark design breadth
- DTVBench concentrates on Manim/Mathematica; expanding to other theorem/geometry/interactive-math ecosystems (e.g., GeoGebra, Desmos, TikZ/Asymptote) could better stress generality.
- Compositional generalization is not tested (e.g., zero-shot combinations of unseen chart types, styles, and interaction patterns).
- Ethics and misuse risks
- The paper does not discuss potential misuse (e.g., auto-generation of deceptive charts, insecure webpages), nor propose guardrails, filters, or watermarking for generated artifacts.
- There is no evaluation for bias propagation in visual representations (color palettes, iconography) or content safety in UI/text generation.
Practical Applications
Immediate Applications
Below is a concise set of actionable, real-world use cases that can be deployed now, organized by sector and linked to concrete tools, products, or workflows enabled by the paper’s models, dataset, and data toolkit.
- NL-to-Chart Assistant for Data Science Workflows (Software, Finance, Healthcare, Energy)
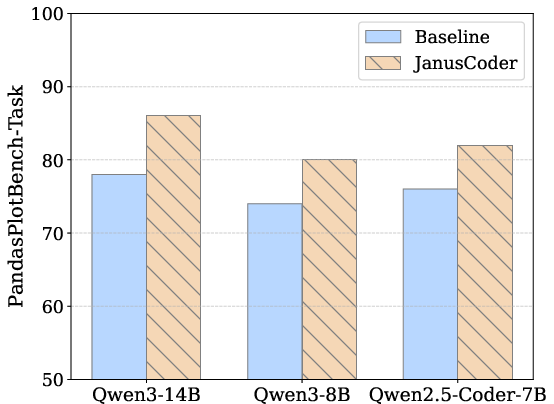
- Use JanusCoder in Jupyter/VS Code to turn natural language instructions into executable Python visualization code (Matplotlib/Seaborn), and to edit plots programmatically.
- Potential product/workflow: “Chart Copilot” plugin that reads DataFrames and generates/edit plots; CI checks for incorrect code or visual mismatch.
- Dependencies/assumptions: Python runtime and plotting libraries; deterministic rendering config; access to tabular data with appropriate governance.
- Chart-to-Code Replication and Migration (Finance, Journalism/Media, Academia, Policy)
- Use JanusCoderV to reproduce published charts from images/screenshots, creating auditable, modifiable code artifacts for reports and dashboards.
- Potential product/workflow: “ChartMimic CLI” that ingests an image/caption and outputs Matplotlib code; visual-to-code diff for audit trails.
- Dependencies/assumptions: High-quality chart images; domain conventions (color/type/layout) recognized by the model; sandboxed execution.
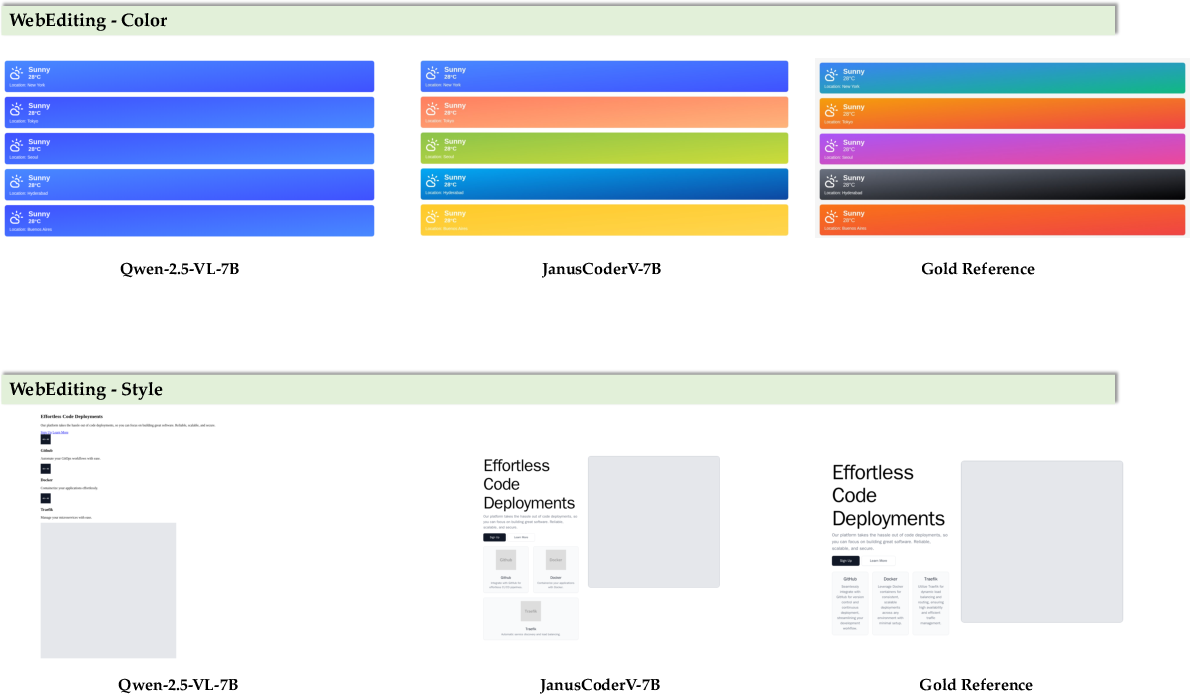
- Design-to-HTML Generation and UI Editing from Screenshots (Software, E-commerce, Public Sector Web)
- Generate or edit HTML/CSS/JS to match a screenshot or design mock; accelerate prototyping and variant testing.
- Potential product/workflow: Figma/Sketch/Playwright-integrated “Design2Code” assistant that proposes editable diffs and validates rendering.
- Dependencies/assumptions: Alignment with local component libraries/design systems; cross-browser testing; Playwright or similar renderer in CI.
- Visualization QA Gate in CI/CD (Software, Compliance)
- Integrate the reward-modeling pipeline to verify that rendered visuals match instructions and code intent, not just compile/execution success.
- Potential product/workflow: “Visual QA Gate” that runs Exec(E), captures outputs, and uses a VLM judge on task relevance/completion, code quality, and visual clarity.
- Dependencies/assumptions: Access to VLM/LLM judges; reproducible environments; agreed thresholds for accept/reject.
- Curriculum Content Creation: Code-Driven Animations of Theorems (Education)
- Use JanusCoder to generate Manim animations or Wolfram Mathematica demonstrations from textbook-level NL prompts to explain math/CS concepts.
- Potential product/workflow: LMS plug-in to auto-generate classroom visuals; “Animation Editor” to iteratively refine sequences.
- Dependencies/assumptions: Installed Manim/Wolfram engines; instructor review; licensing for course distribution.
- Interactive Scientific Demonstrations for Labs and Outreach (Academia, Healthcare/Clinical Research)
- Produce web-based, code-driven demos (InteractScience) explaining algorithms, simulations, or methods for internal reviews or public outreach.
- Potential product/workflow: “Science Demo Builder” with Playwright validation, embedding into lab pages or notebooks.
- Dependencies/assumptions: Hosting and rendering stack; curated datasets; domain expert oversight.
- Cross-Language Code Translation for Scientific Computing (Academia, Engineering)
- Apply bidirectional translation to port conceptual logic across Manim/Mathematica and R/Matlab, reducing duplication in multi-language teams.
- Potential product/workflow: “SciCode Translator” that uses source code as a structural template to produce target-domain equivalents.
- Dependencies/assumptions: Library parity and platform-specific APIs; license constraints; human validation on edge cases.
- Domain-Specific Dataset Construction with the Synthesis Toolkit (Academia, AI/ML Industry)
- Adopt the paper’s toolkit (guided evolution, re-contextualization, reverse instruction, bidirectional translation, AST decomposition, sandbox validation, VLM/LLM reward) to build new multimodal code datasets in specialized domains.
- Potential product/workflow: Automated data factory for chart/UI/animation corpora; plug-in validators for domain-specific renderers.
- Dependencies/assumptions: Source corpora availability and licensing; scalable execution environments; compute for synthesis/judging.
- Web Accessibility Improvement Assistant (Policy/Public Sector, Software)
- Auto-suggest code edits to improve contrast, add ARIA roles, and generate alt text from screenshots/instructions.
- Potential product/workflow: “WCAG Fixer” that proposes diffs and validates improvements via rendering/judging.
- Dependencies/assumptions: Access to codebase; WCAG rules encoded; screenshot fidelity; human approval loop.
- BI Dashboard Auto-Building from Plain Language (Finance, Energy, Healthcare Ops)
- Map business questions to multi-panel charts and dashboards with code artifacts for reproducibility.
- Potential product/workflow: “Dashboard Generator” that produces consistent charting code and visual QA reports.
- Dependencies/assumptions: Data source connectivity and governance; environment security; organizational standards for visuals.
- Report Reproduction and Verification (Policy, Journalism, Auditing)
- Validate published figures by recreating them programmatically, checking consistency with stated methodology or captions.
- Potential product/workflow: “Visual Integrity Auditor” that compares reproduced outputs to originals using VLM judges and structural metrics.
- Dependencies/assumptions: Access to source methods and data; agreed evaluation criteria; legal use of images.
Long-Term Applications
The following applications require additional research, scaling, integration, or productization before broad deployment.
- Generalist Vision–Programmatic Design Agent for End-to-End Front-End Development (Software, E-commerce)
- An autonomous agent that iteratively plans, generates, tests, and edits code from NL specs and evolving visual feedback across pages, components, and states.
- Potential product/workflow: “Janus Studio” with closed-loop reward modeling, multi-renderer checks, and design-system alignment.
- Dependencies/assumptions: Robust multi-modal planning; scalable, secure sandboxes; enterprise-grade guardrails and provenance tracking.
- Visualization Governance and Compliance Auditing (Policy/Regulation, Finance, Pharma)
- Standardized checks for visual misrepresentation (e.g., axis manipulation, color semantics) and alignment with reporting standards, embedded into regulatory workflows.
- Potential product/workflow: “Visual Compliance Engine” producing audit trails and remediation diffs.
- Dependencies/assumptions: Access to ground truth, sector-specific standards, trust metrics for VLM/LLM judgments.
- Adaptive Tutoring Systems with Dynamic Concept Visualizations (Education)
- Personalized teaching agents that generate tailored animations and interactive demos, adapting difficulty and modality based on learner feedback.
- Potential product/workflow: Integrated classroom assistant that tracks mastery and produces scaffolded visuals and code exercises.
- Dependencies/assumptions: Student modeling and privacy; pedagogical validation; safe content generation policies.
- Reproducible Scientific Publishing Pipeline (Academia, Industry R&D)
- Journals and preprint servers adopt “visuals-as-code” artifacts, bundling executable notebooks/animations/demos with papers for verifiable reproduction.
- Potential product/workflow: “Executable Figures Packager” integrated with submission portals and containerized reviewers.
- Dependencies/assumptions: Publishers’ standards; containerization/versioning; long-term archivability.
- Cross-Framework UI Migration and Refactoring (Software Modernization)
- Automated translation from legacy frontend codebases (e.g., jQuery/vanilla) to modern stacks (React/Vue/Svelte) using screenshot-code synergy and structural mapping.
- Potential product/workflow: “Legacy-to-Modern Migrator” with component library mapping and iterative visual diffs.
- Dependencies/assumptions: Reliable component equivalence; extensive paired datasets; human-in-the-loop review.
- Robotics/IoT Control Dashboards and Simulation Visuals (Robotics, Industrial IoT)
- Auto-generate interactive UIs and data plots from device schemas and state diagrams; produce simulation animations for operator training.
- Potential product/workflow: “Device UI Generator” and “Simulation Visualizer” tied to telemetry streams.
- Dependencies/assumptions: Real-time data pipelines; strict safety constraints; domain-specific validators.
- Scenario Visualization for Grid Operations and Risk Analytics (Energy, Finance)
- Animated “what-if” simulations driven by code for stress testing and contingency planning dashboards.
- Potential product/workflow: “Scenario Animator” with domain models, visual QA, and governance controls.
- Dependencies/assumptions: Accurate models and access-control; sector compliance; high compute for simulations.
- Privacy-Preserving, On-Device Multimodal Code Assistants (Software, Mobile/Edge)
- Compressed JanusCoder variants running offline to generate/edit visuals and UI code, preserving sensitive data.
- Potential product/workflow: Edge SDKs for IDEs and mobile dev tools.
- Dependencies/assumptions: Model compression/distillation without large performance loss; device GPUs/NPUs; secure local sandboxes.
- Industry-Wide Standards and Benchmarks for Visual–Code Alignment (Cross-Sector)
- Shared evaluation suites (like DTVBench) and reward-model specs to measure semantics, faithfulness, and execution across domains.
- Potential product/workflow: “Visual-Code Alignment Benchmark Suite” adopted by tool vendors and CI platforms.
- Dependencies/assumptions: Consensus on metrics; interoperability across renderers; community stewardship.
- Autonomous Multi-Modal Data Synthesis for High-Stakes Domains (Healthcare Imaging, Geospatial)
- Extending the toolkit to generate carefully validated datasets for sensitive visual modalities, enabling robust multimodal code intelligence.
- Potential product/workflow: “Domain Data Factory” with domain-specific judges and safety filters.
- Dependencies/assumptions: Expert labeling and governance; compliance requirements; stronger visual fidelity guarantees.
Glossary
- Abstract Syntax Tree (AST): A tree-structured representation of source code used for static analysis, transformation, or decomposition. "We parse complex source code into its AST representation"
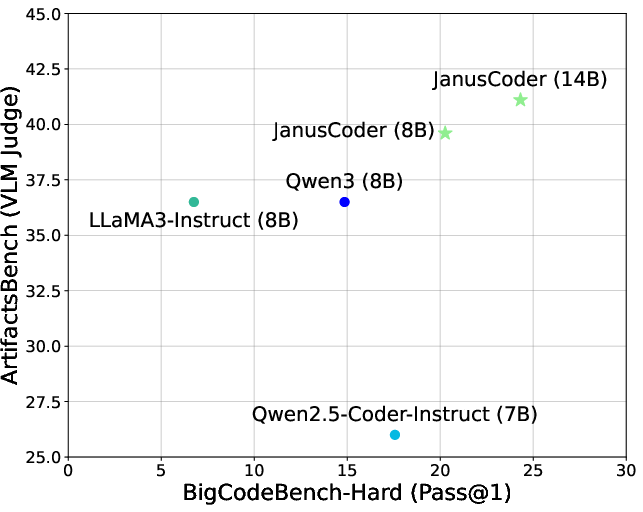
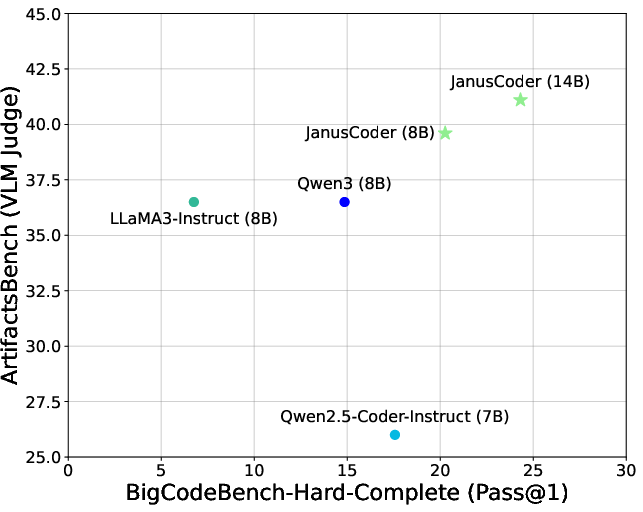
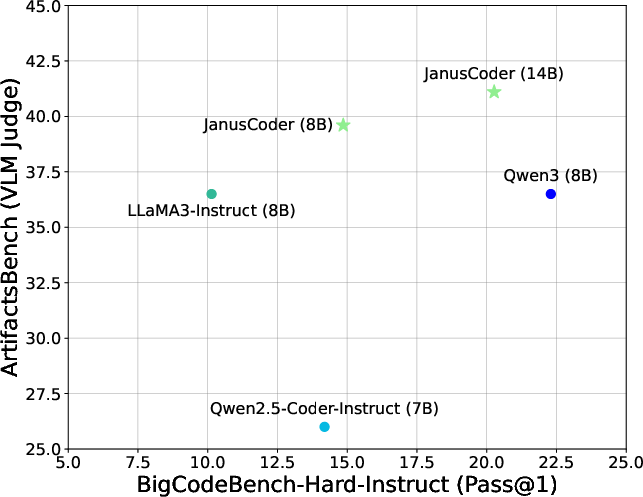
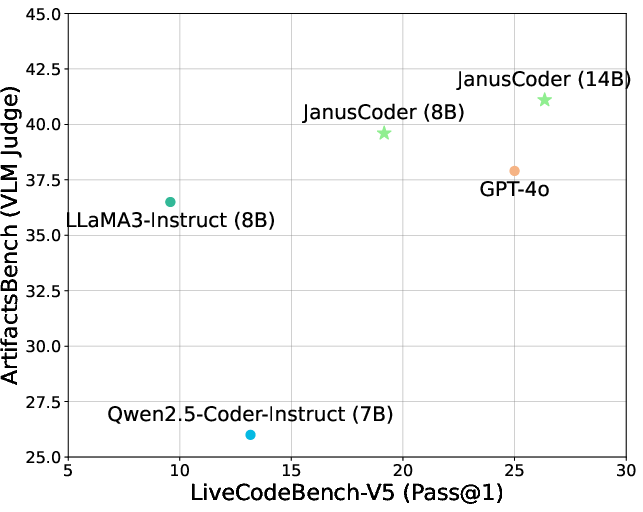
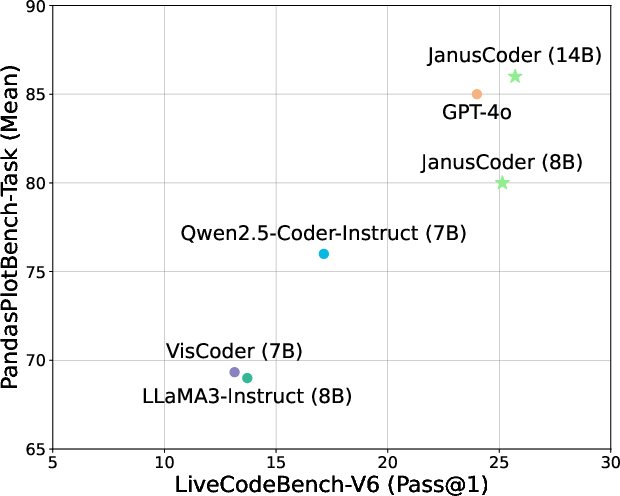
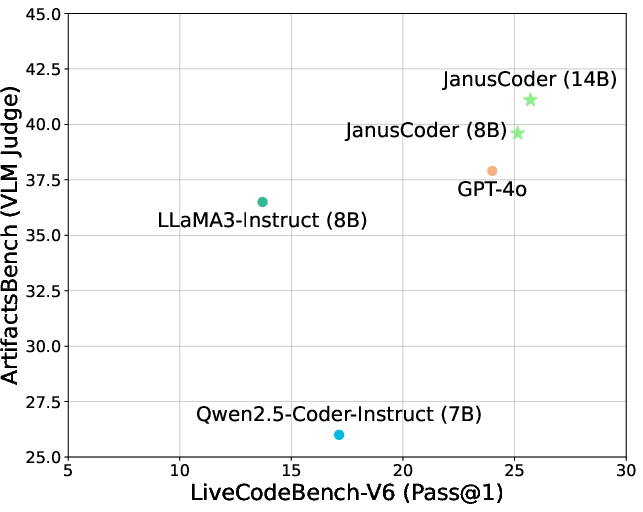
- ArtifactsBench: A benchmark evaluating code generation for interactive visual artifacts (web-based components). "JanusCoder delivers results on ArtifactsBench~\citep{zhang2025artifactsbench} that are significantly better than GPT-4o"
- Bidirectional Translation: A data synthesis strategy that translates tasks and code between semantically analogous domains to learn abstract, syntax-agnostic representations. "This strategy fosters the learning of abstract, syntax-independent representations by translating conceptual intent between semantically analogous domains (e.g., Manim and Mathematica), effectively multiplying the value of our specialized datasets."
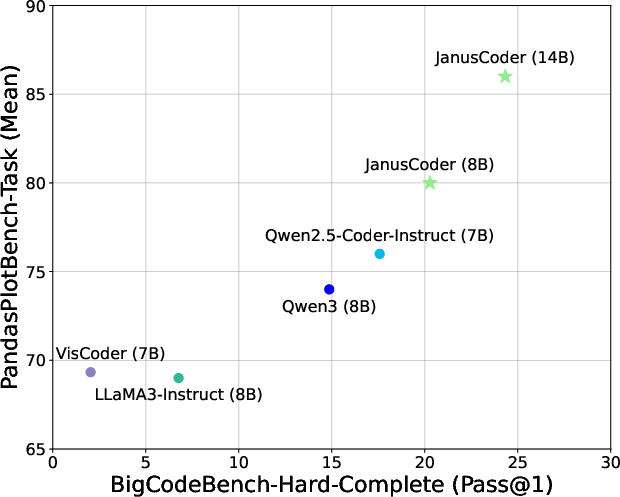
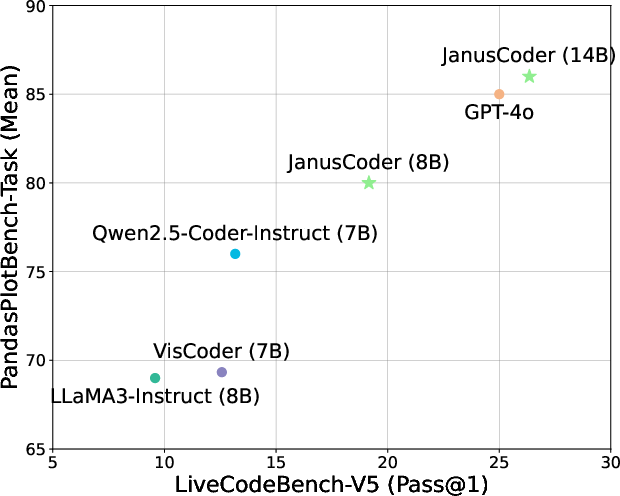
- BigCodeBench: A general coding benchmark assessing instruction following and algorithmic capability. "We also evaluate on BigCodeBench~\citep{zhuo2025bigcodebench} and LiveCodeBench~\citep{jain2025livecodebench}"
- bfloat16: A reduced-precision floating-point format commonly used to accelerate deep learning training with minimal accuracy loss. "All training experiments are conducted using the LLaMA-Factory framework~\citep{zheng2024llamafactory} with bfloat16 precision."
- ChartMimic: A benchmark for chart-to-code tasks measuring both low-level and high-level fidelity of reproduced plots. "We evaluate JanusCoderV on ChartMimic~\citep{yang2025chartmimic}"
- Chart-to-code: The task of generating plotting code from a chart image (and optionally text) to faithfully reproduce the visualization. "chart-to-code generation, which requires reproducing scientific plots from images with captions or instructions"
- CLIP: A vision-language similarity model used as an automatic metric for visual alignment. "CLIP"
- DeepSpeed: A deep learning optimization and distributed training framework for large models. "and the DeepSpeed framework~\citep{deepspeed}."
- DesignBench: A benchmark for webpage generation and editing from visual inputs (screenshots/designs). "and DesignBench~\citep{xiao2025designbench} for WebUI generation and editing"
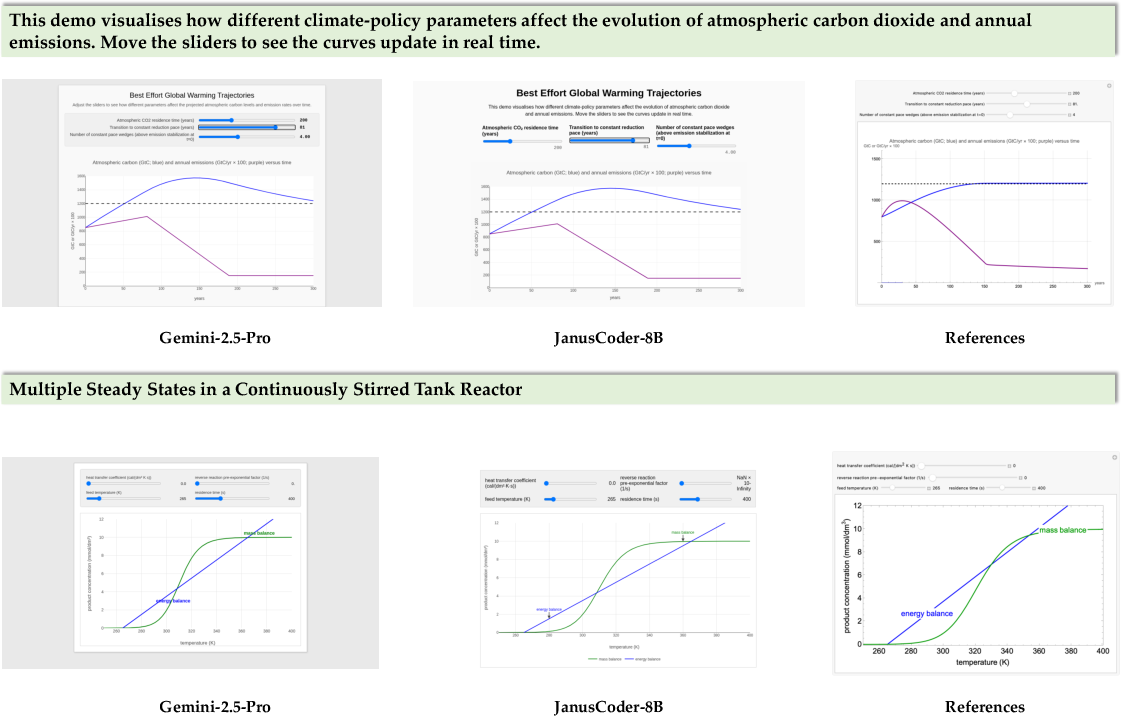
- DTVBench: A benchmark for dynamic theorem visualization via Manim and Wolfram Mathematica. "We present DTVBench for evaluating the capability of models to generate code for dynamic theorem visualizations."
- Executability: A binary criterion indicating whether generated code runs successfully. "Executability ($s_{\text{exec} \in \{0,1\}$): whether the generated code can be successfully executed."
- Faithfulness: A score reflecting the plausibility and visual correctness of dynamic or interactive outputs beyond strict reference matching. "Faithfulness ($s_{\text{faith} \in [1,5]$): since dynamic content is primarily intended for human interpretation and interactive outputs are difficult for LLM-based judges to evaluate, we introduce an optional subjective score assessing the plausibility and visual correctness of the generated animation or interactive content."
- FlashAttention-2: An efficient attention kernel that accelerates Transformer training and inference with reduced memory overhead. "we employ FlashAttention-2~\citep{dao2023flashattention2}"
- Guided Evolution: A synthesis strategy that evolves seed instruction-code pairs using concept-level guidance to increase diversity and complexity. "We adapt our previously proposed interaction-driven synthesis~\citep{sun2025codeevo} to this strategy, aiming to increase data complexity and diversity."
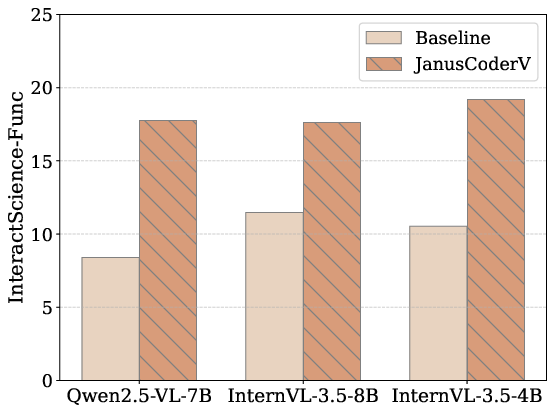
- InteractScience: A benchmark for generating scientific demonstration code grounded in multimodal understanding and front-end capabilities. "and InteractScience~\citep{chen2025interact} for scientific demonstration code generation."
- InternVL: A family of open-weight vision-LLM backbones used for multimodal code generation. "we additionally include Qwen3-4B, Qwen2.5-Coder-7B-Instruct~\citep{qwen25coder}, and InternVL3.5-4B for further comparison."
- JanusCode-800K: A large-scale multimodal code corpus spanning charts, web UIs, artifacts, animations, and scientific domains. "we curate JanusCode-800K, the largest multimodal code intelligence corpus to date."
- JanusCoder: A unified model family establishing a visual-programmatic interface for generating and editing code from text and/or visuals. "JanusCoder is a suite of models that establishes a unified visual-programmatic interface, advancing multimodal code intelligence."
- LLM: A neural model trained on vast text corpora capable of generating and reasoning over natural language and code. "The advent of LLMs (LLMs; \citealp{hurst2024gpt,anthropic2024claude}) has significantly advanced the field of code intelligence"
- Liger-Kernel: High-performance CUDA kernels improving efficiency of Transformer training. "we employ FlashAttention-2~\citep{dao2023flashattention2}, Liger-Kernel~\citep{hsu2025ligerkernel}, and the DeepSpeed framework~\citep{deepspeed}."
- LiveCodeBench: A dynamic coding benchmark evaluating real-time code generation and problem-solving. "We also evaluate on BigCodeBench~\citep{zhuo2025bigcodebench} and LiveCodeBench~\citep{jain2025livecodebench}"
- Manim: A Python engine for explanatory mathematical animations used to visualize theorems and concepts. "Manim, an engine for creating explanatory mathematical animations"
- Meta task: A canonical edit operation class that abstracts user intent for web page editing. "We define a meta task as an abstract, canonicalized edit operation on a web page that captures the essential type of user intent while remaining agnostic to the specific context, location, or wording."
- Multimodal code intelligence: The capability to understand and generate code using both textual and visual inputs/outputs. "advancing multimodal code intelligence."
- Perceptual–symbolic gap: The disconnect between raw perceptual (visual) data and symbolic (code/logical) representations. "with the aspiration of bridging the perceptualâsymbolic gap."
- Playwright: A browser automation and rendering tool used to validate web UI code executions. "Playwright"
- Program-aided understanding: A modeling approach that leverages executable programs to enhance understanding and reasoning over tasks. "Current research predominantly focuses on program-aided understanding~\citep{qiu2025can,chen2025symbolicgraphics} and reasoning~\citep{suris2023viper,guo2025mammothvl}"
- Reverse Instruction: A synthesis method that derives natural-language instructions from existing code snippets to create aligned instruction-code pairs. "we develop a reverse-instruction process: given a reference file $C_{\text {ref } \in D_{\text {coder }$"
- Reward modeling: An automated scoring pipeline using LLMs/VLMs to rate task relevance, completion, code quality, and visual clarity for data filtering. "We therefore construct a reward modeling pipeline, tailored to our different data types, to systematically assess and filter out misaligned or low-quality data at scale."
- Sandbox: An isolated execution environment providing interpreters/renderers for safe validation of generated code. "We leverage a sandbox that provides the necessary backends (e.g., Python interpreters, web renderers)."
- SVG (Scalable Vector Graphics): A text-based vector image format enabling precise, structured graphics and programmatic manipulation. "structured vector graphics such as SVGs~\citep{yang2025omnisvg,nishina2024svgeditbench}."
- Symbolic computation: Computation over mathematical expressions in symbolic form (exact algebra/calculus) rather than numeric approximation. "Wolfram Mathematica~\citep{Mathematica}, a symbolic computation engine supporting interactive visualizations."
- TreeBLEU: A structural code similarity metric that compares parsed code trees rather than raw tokens. "TreeBLEU"
- Unified visual-programmatic interface: A modeling paradigm that integrates visual content generation, editing, and interpretation with programmatic logic. "establishes a unified visual-programmatic interface"
- Vision-LLM (VLM): A model jointly trained on images and text, used to assess visual fidelity and instruction alignment. "Our reward model employs a VLM as its core engine to assess the quality of data."
- WebUI: Web user interfaces composed of HTML/CSS/JS, often generated or edited from visual inputs or NL instructions. "and DesignBench~\citep{xiao2025designbench} for WebUI generation and editing"
- Wolfram Mathematica: A symbolic computation system supporting interactive visualizations and dynamic content generation. "Wolfram Mathematica~\citep{Mathematica}, a symbolic computation engine supporting interactive visualizations."
- ZeRO sharding: A memory-optimization technique that partitions optimizer states and parameters across distributed GPUs to scale training. "with ZeRO-2 sharding and a per-device batch size of 2"
Collections
Sign up for free to add this paper to one or more collections.