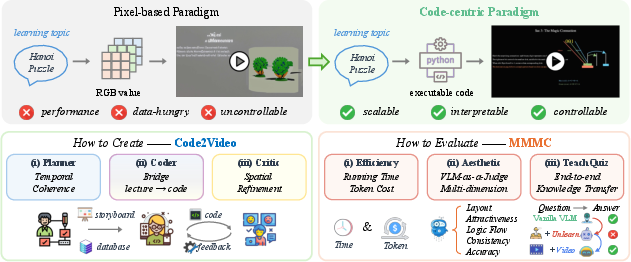
Code2Video: A Code-centric Paradigm for Educational Video Generation
Abstract: While recent generative models advance pixel-space video synthesis, they remain limited in producing professional educational videos, which demand disciplinary knowledge, precise visual structures, and coherent transitions, limiting their applicability in educational scenarios. Intuitively, such requirements are better addressed through the manipulation of a renderable environment, which can be explicitly controlled via logical commands (e.g., code). In this work, we propose Code2Video, a code-centric agent framework for generating educational videos via executable Python code. The framework comprises three collaborative agents: (i) Planner, which structures lecture content into temporally coherent flows and prepares corresponding visual assets; (ii) Coder, which converts structured instructions into executable Python codes while incorporating scope-guided auto-fix to enhance efficiency; and (iii) Critic, which leverages vision-LLMs (VLM) with visual anchor prompts to refine spatial layout and ensure clarity. To support systematic evaluation, we build MMMC, a benchmark of professionally produced, discipline-specific educational videos. We evaluate MMMC across diverse dimensions, including VLM-as-a-Judge aesthetic scores, code efficiency, and particularly, TeachQuiz, a novel end-to-end metric that quantifies how well a VLM, after unlearning, can recover knowledge by watching the generated videos. Our results demonstrate the potential of Code2Video as a scalable, interpretable, and controllable approach, achieving 40% improvement over direct code generation and producing videos comparable to human-crafted tutorials. The code and datasets are available at https://github.com/showlab/Code2Video.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Code2Video: Making Teaching Videos by Writing Code
1. What is this paper about?
This paper introduces Code2Video, a new way to make educational videos using computer code. Instead of asking an AI to paint every pixel of a video, Code2Video writes step-by-step instructions (Python code) that tell a graphics tool exactly what to draw, where to place things on the screen, and when to animate them. The goal is to create clear, well-organized teaching videos that actually help people learn.
2. What questions does the paper try to answer?
The paper focuses on two simple questions:
- How can we automatically create high-quality teaching videos that are easy to follow and visually clear?
- How can we judge whether these videos truly help someone learn a topic, not just look good?
3. How does Code2Video work?
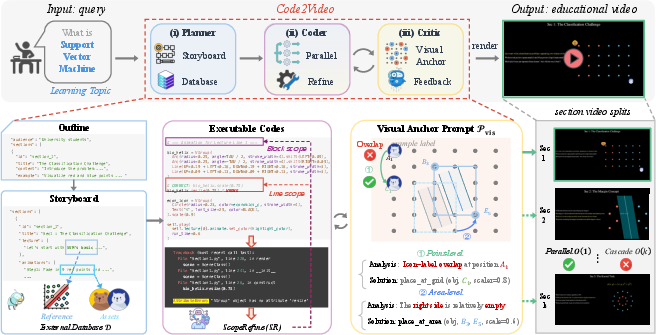
Think of making a teaching video like making a short film. You need a plan, a script, and a final check. Code2Video uses three AI “helpers” (agents), each with a job:
- Planner: Like a teacher planning a lesson. It breaks the topic into a clear order (intro, examples, recap), chooses the right level for the audience, and finds helpful images or icons to use.
- Coder: Like a programmer who turns the plan into Python code for Manim (a tool that draws math-style animations). It writes code for each section and fixes errors smartly.
- Critic: Like a director reviewing the cut. It watches the rendered video and suggests changes to the layout so that text isn’t blocked, elements don’t overlap, and everything is easy to read.
To make these ideas work, the paper introduces a few key techniques and terms explained in everyday language:
- Manim: A Python library that draws animated shapes, formulas, and diagrams. Think of it as a very precise “digital whiteboard” you can control with code.
- Parallel code generation: The Coder works on multiple sections of the video at the same time, so the whole process is faster.
- ScopeRefine (smart debugging): When the code breaks, instead of rewriting everything, the system first tries fixing just the broken line, then the small block, and only if needed, the whole section. This saves time and effort—like repairing a loose screw before replacing a whole machine.
- Visual anchor grid: The Critic uses a simple grid over the screen to decide where to place things. Each spot on the grid maps to exact coordinates. This turns “move the label slightly right” into a precise instruction like “place the label at anchor (row 3, column 5).” It’s like placing stickers on a tic-tac-toe board, but with more squares.
- VideoLLM feedback: A vision-LLM (an AI that looks and reads) checks the video and the code together. It can say things like “the formula overlaps the chart,” then point to the exact code line to fix.
- MMMC benchmark: A test set of real, professional teaching videos (many based on 3Blue1Brown’s Manim tutorials) across 13 subjects. It’s used to compare different video-making methods fairly.
- TeachQuiz metric: A new way to judge if a video teaches well. First, the “student AI” is made to temporarily “unlearn” a concept. Then it watches the video and takes a quiz. The score is the improvement from “unlearned” to “after watching,” which shows how much the video itself helped.
4. What did they find?
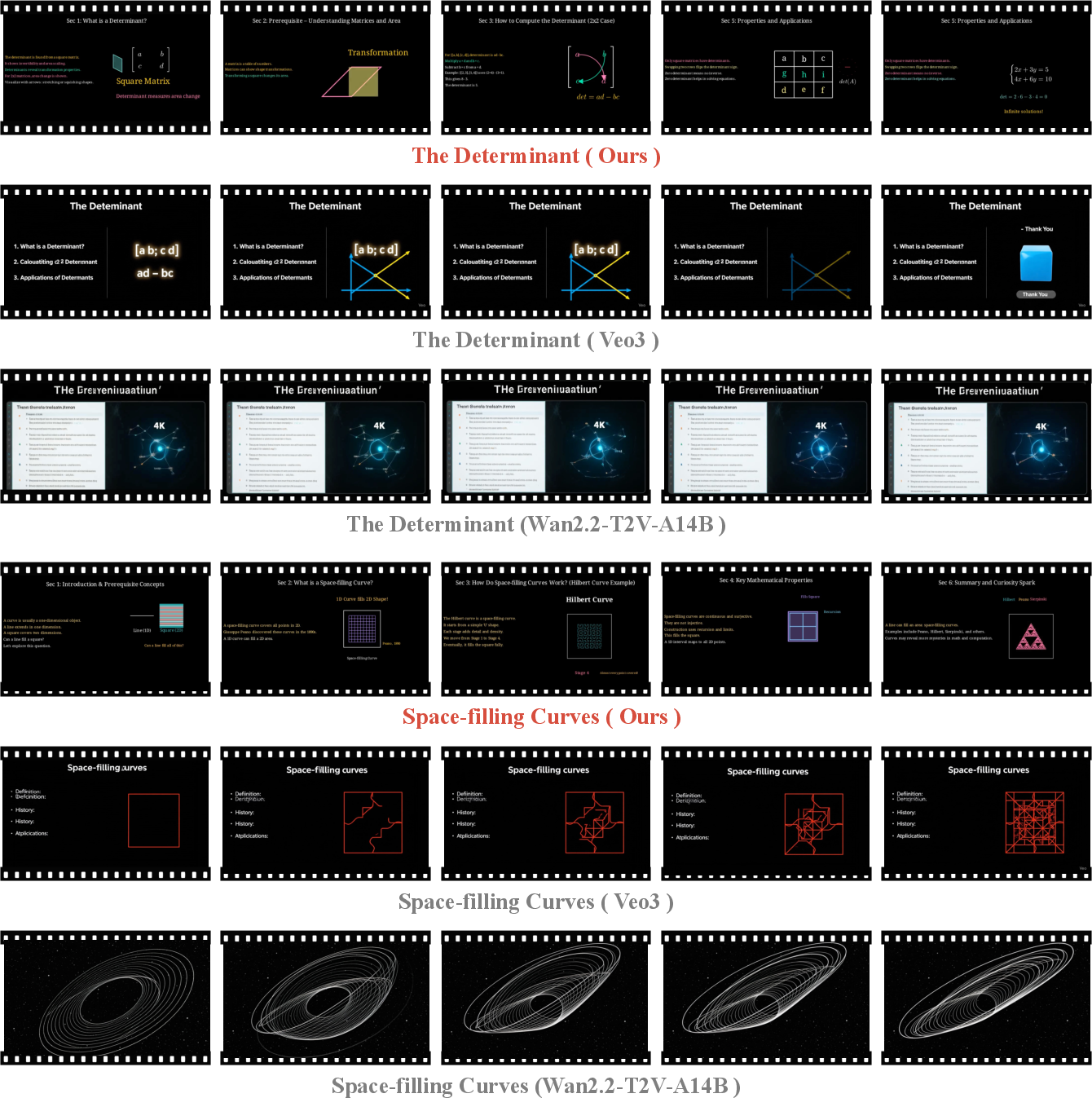
The paper compares four approaches: human-made videos, pixel-based generative videos, direct code generation by a single AI, and the full Code2Video agent pipeline.
Key findings:
- Pixel-based video models look flashy but struggle with teaching details. They often produce blurry text, inconsistent styles, and messy timing. These problems hurt learning.
- Direct code generation (just asking an AI to write Manim code) is better than pixel-based video for teaching, because code gives clean text and stable layouts.
- Code2Video’s three-agent pipeline does even better. It improves the teaching metric (TeachQuiz) by around 40% over direct code generation. It also scores higher on layout, logic flow, and correctness in aesthetic judging.
- In some human tests, Code2Video’s videos taught as well as or better than professional tutorials for certain topics. People’s ratings strongly matched the AI judge’s ratings: clearer, more attractive videos helped learners score higher.
- Efficiency matters: parallel code writing and ScopeRefine debugging cut down the time and “token” cost (AI’s reading/writing budget), making the system more practical.
Why this is important:
- It shows that writing code to create videos—rather than painting pixels—makes teaching content clearer and more reliable.
- It provides a fair, learning-focused way to measure video quality using TeachQuiz, not just looks.
5. Why does this research matter?
If you want to learn, you need videos that are clear, correct, and well-paced. Code2Video points to a future where:
- Teachers and creators can quickly make accurate, customizable teaching videos by editing code.
- Videos are easier to fix and improve because everything is scripted and traceable.
- We have better tools (like TeachQuiz) to check whether a video actually teaches, not just entertains.
In short, Code2Video makes educational video creation more scalable, more controllable, and more effective for learning. It’s a step toward smarter, code-driven classrooms where what you see on screen matches what you need to understand.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a single, consolidated list of concrete knowledge gaps and limitations left unresolved by the paper. Each point is framed so future researchers can act on it.
- Scope limited to Manim-based 2D instructional animations; no assessment of applicability to 3D scenes, real-world footage, screencasts (e.g., programming tutorials), lab demonstrations, or mixed-media educational videos.
- Absence of audio pipeline: no narration, sound design, or TTS integration, and no measurement of how audio and pacing affect TeachQuiz or human learning outcomes.
- Visual anchor discretization fixed at a 6×6 grid; no study of alternative resolutions, adaptive grids for different aspect ratios/resolutions, or continuous coordinate prediction and its effects on occlusions and element readability.
- Lack of formal layout optimization: Critic’s placement uses heuristic anchors and occupancy tables, but there is no algorithmic formulation (e.g., ILP/RL/gradient-based optimization) or global objective to minimize occlusion and maximize clarity.
- Unspecified detection of dynamic occlusions across time; no method for frame-wise or temporal continuity constraints to prevent transient overlap or drift during animations.
- Planner’s audience-level adaptation (e.g., middle school vs. undergraduate) is claimed but not empirically validated; no metrics or user studies that quantify appropriateness of difficulty, explanations, or scaffolding.
- External asset curation and retrieval are not audited for factual fidelity, consistency, or licensing; no pipeline for asset quality filtering, deduplication, versioning, or provenance tracking.
- Mathematical correctness is judged via VLM-as-Judge “Accuracy & Depth,” but there is no domain-expert verification or formal checking of formulas, derivations, or proofs.
- ScopeRefine (SR) debugging is only compared against naive baselines; no error taxonomy or per-error-type performance analysis (syntax, API misuse, logic bugs, rendering artifacts), nor comparisons with state-of-the-art program repair or test-driven synthesis.
- Efficiency reporting lacks clarity on whether times include rendering, environment setup, and asset retrieval; hardware specs, parallelization strategy, and reproducibility controls are not standardized across conditions.
- TeachQuiz unlearning mechanism is underspecified; unclear how prior knowledge is “blocked,” raising validity concerns about measuring video-induced learning versus latent knowledge or leakage.
- TeachQuiz robustness not evaluated across multiple student models; dependence on a single VLM “student” risks model-specific bias and undermines generality.
- TeachQuiz measures immediate post-exposure performance only; no retention tests (e.g., delayed quizzes at 24–72 hours) or assessments of deeper understanding versus rote recall.
- Quiz construction (size, difficulty calibration, coverage, item formats) is not described in detail; no psychometric validation, item discrimination indices, or checks against model training contamination.
- VLM-as-Judge reliability not audited: no inter-rater reliability across different VLM judges, prompt sensitivity analysis, or calibration with gold human ratings on a shared subset.
- Human study is small and potentially confounded: durations vary widely across conditions, generated videos lack narration, and topic difficulty is not controlled; no stratified sampling, preregistration, or demographic diversity analysis.
- No safety and security discussion around executing model-generated code: sandboxing, resource limits, OS/Manim version dependencies, and safeguards against malicious or unstable code are not addressed.
- Accessibility is not considered: no evaluation of color contrast, font legibility, captioning/subtitles, language localization, right-to-left script handling, or colorblind-friendly palettes.
- Interactivity is absent: no integration of in-video quizzes, pausable checkpoints, or adaptive feedback loops, and no measurement of how interactivity impacts learning efficacy.
- Benchmark MMMC is derived from 3Blue1Brown and may be biased toward mathematics-heavy topics; coverage of domains requiring diagrams, 3D models, or real experiments (e.g., chemistry, biology, medicine) is untested.
- Generalization to multilingual educational content is unexplored: font rendering for non-Latin scripts, translation quality, localized examples, and culturally adapted pedagogy are not evaluated.
- Hybrid pipelines are not explored: combining code-centric rendering with pixel-based generative models (e.g., for complex textures or backgrounds) and studying their trade-offs.
- Pipeline failure modes lack qualitative analysis: cases with incorrect layouts, unreadable text/formulas, misaligned timing, or content inaccuracies are not categorized with actionable fixes.
- No public protocol for reproducible evaluation: exact prompts, student VLM configurations, unlearning procedures, environment specs, and rendering settings need open, versioned release for replicability.
- Scalability and cost analyses are limited: token usage is reported, but long-horizon videos, large curricula, batching strategies, and cost-performance curves across different LLM backbones are not characterized.
- Content ethics and misinformation risks are not discussed: mechanisms for fact-checking, instructor identity transparency, and accountability in automated educational content generation remain open.
- Lack of pedagogical metrics beyond aesthetics and quiz scores: no measures of cognitive load, engagement over time, transfer to new problems, or alignment with established instructional design frameworks (e.g., Bloom’s taxonomy).
- Asset reuse and temporal consistency are asserted but not measured quantitatively: no metrics for visual consistency across sections or the impact of cached assets on learner comprehension and memory.
- Integration pathways with LMS platforms and classroom use-cases are unaddressed: scheduling, assessment integration, personalization, and teacher-in-the-loop workflows remain unexplored.
Practical Applications
Immediate Applications
The following applications can be deployed now with the methods, tools, and evidence described in the paper (Planner–Coder–Critic pipeline, Manim code generation, ScopeRefine debugging, visual anchor prompts, TeachQuiz evaluation).
- Educational micro‑lesson generation — sectors: education, edtech, media/publishing
- What: Auto-generate short, structured STEM explainers, worked examples, and recap videos for K–12 and undergraduate topics from syllabi or lesson objectives.
- Workflow/Product: “Code2Video Studio” (authoring IDE) or LMS plug‑in (Canvas/Moodle) invoking Planner→Storyboard→Manim code→Render→Critic; asset cache for consistent icons/figures; optional TTS and captions.
- Assumptions/Dependencies: Topics are representable with 2D vector graphics/diagrams; instructor reviews for concept accuracy; Manim rendering resources; API access to capable LLM/VLM.
- Courseware authoring copilot — sectors: education, edtech
- What: Instructor-in-the-loop tool to rapidly storyboard lectures, generate animated diagrams, and enforce level-appropriate pacing.
- Workflow/Product: VSCode/Jupyter extension to convert markdown/LaTeX cells into Manim animations with anchor-grid layout; WYSIWYG overlay for anchor positions.
- Assumptions/Dependencies: Faculty adoption; content policies and accessibility (WCAG) checks; license-cleared assets.
- Corporate L&D content from policy/SOPs — sectors: enterprise HR/training, manufacturing, finance, compliance
- What: Turn SOPs, safety procedures, and compliance policies into clear, step-by-step training videos with unambiguous layout (no occlusions).
- Workflow/Product: “Policy‑to‑Training” pipeline: doc ingestion → outline → storyboard → code with ScopeRefine → render → TeachQuiz‑based internal QA.
- Assumptions/Dependencies: Legal review for regulated domains; proprietary data security; terminology/domain assets available.
- Developer documentation to animated walkthroughs — sectors: software, devrel, customer support
- What: Convert API guides, architectural diagrams, and product onboarding docs into animated explainers and feature walkthroughs.
- Workflow/Product: Docs‑to‑Animation CLI/SaaS; Sphinx/Markdown plug‑ins; occupancy table ensures text/diagram readability; version control for code‑as‑content.
- Assumptions/Dependencies: Alignment with brand guidelines; continuous docs updates trigger re‑renders; Manim-friendly diagram abstractions.
- YouTube creator toolkit for explainers — sectors: media, creator economy, daily life
- What: Solo creators generate consistent, professional visuals (math, physics, finance literacy) with code‑driven reproducibility and multilingual variants.
- Workflow/Product: Template library of storyboards and reusable Manim scenes; batch render scripts; subtitle and VO tracks swapped per locale.
- Assumptions/Dependencies: Asset licensing; narration quality; platform compliance (music/fonts).
- Localization and accessibility at scale — sectors: education, public information, NGOs
- What: Re‑render the same lesson in multiple languages with faithful layout; stabilize high‑contrast text and avoid occlusions to support low‑vision learners.
- Workflow/Product: Translation → text layer swap → re‑render via anchor‑grid; auto‑captioning; color‑contrast and font‑size validators in the Critic stage.
- Assumptions/Dependencies: High‑quality translation; TTS/VO; accessibility audits.
- Patient and public education explainers — sectors: healthcare, public health
- What: Short animations explaining procedures, consent, medication adherence, or vaccination schedules.
- Workflow/Product: Evidence‑sourced storyboard + vetted assets library → Critic checks for clarity and non‑overlapping text → TeachQuiz‑style pretests (proxy with VLMs) before pilots.
- Assumptions/Dependencies: Clinical validation; regulated terminology; risk disclaimers; institutional review.
- Public policy communication — sectors: government, civic tech
- What: Procedural guides (tax filing steps, voting process, disaster preparedness) as reproducible code‑authored videos with version history.
- Workflow/Product: Git‑tracked “code narratives” with auditable changes; asset cache for seals/logos; quick re‑render on policy updates.
- Assumptions/Dependencies: Legal approvals; accessibility and translation; open licensing for public reuse.
- A/B evaluation of teaching content with TeachQuiz — sectors: edtech R&D, instructional design
- What: Pre‑release QA by measuring knowledge transfer deltas (unlearning → learning from video) to compare alternative storyboards/visuals.
- Workflow/Product: TeachQuiz Evaluator SaaS; automatic quiz packs per concept; dashboards for EL/LF/VC/AD aesthetics and TeachQuiz gains.
- Assumptions/Dependencies: Quiz quality and coverage; alignment between VLM “student” improvements and target learner outcomes; human validation.
- Generalizable code‑generation debugging pattern — sectors: software tooling
- What: Apply ScopeRefine (line→block→global repair) to other compile‑checkable pipelines (LaTeX docs, build scripts, front‑end layout code).
- Workflow/Product: IDE extensions with hierarchical error localization and minimal token/latency fixes; CI bots that attempt localized repairs first.
- Assumptions/Dependencies: Deterministic build/compile feedback; structured error logs; LLM reliability for small scoped edits.
- Research benchmark and baseline reproduction — sectors: academia, AI/ML
- What: Use MMMC to evaluate new agentic video or code-to-visual methods; reproduce baselines; extend TeachQuiz for ablation and curricula studies.
- Workflow/Product: Public dataset and prompts; leaderboards for aesthetics/TeachQuiz/efficiency; research tutorials on code‑centric generation.
- Assumptions/Dependencies: Licensing for derivative benchmarks; consistent evaluation protocols; compute for renders.
Long‑Term Applications
These applications are feasible extensions but require further research, scaling, or ecosystem development (e.g., longer video coherence, live interactivity, domain validation, cost reductions).
- End‑to‑end course generation and maintenance — sectors: education, edtech, publishing
- What: Agentic production of full multi‑hour courses with consistent style, pacing, and automated updates when curricula or standards change.
- Workflow/Product: Course graph + dependency‑aware Planner; style guide enforcement; periodic diffs and re‑renders; instructor review loops.
- Assumptions/Dependencies: Stronger “Attractiveness” and “Visual Consistency” (noted gap); content accreditation; sustainable compute costs.
- Adaptive and personalized teaching videos — sectors: edtech, tutoring
- What: Real‑time regeneration of segments based on learner performance; multiple pacing tracks and alternative explanations per misconception.
- Workflow/Product: LMS integration with telemetry → trigger localized re‑renders of segments; on‑device rendering or low‑latency cloud.
- Assumptions/Dependencies: Privacy‑preserving analytics; rendering latency constraints; robust small‑scope code edits on demand.
- Hybrid code + pixel generation for rich visuals — sectors: media, design, education
- What: Use code to control structure/semantics and diffusion models to texture/style scenes, enabling professional look with rigorous layouts.
- Workflow/Product: “Structure‑first” renderer outputs guide frames for T2V/super‑resolution; Critic ensures legibility and avoids text corruption.
- Assumptions/Dependencies: Stable text rendering in diffusion; guardrails for semantic drift; compute budgets.
- AR/VR and 3D training with spatial anchors — sectors: manufacturing, robotics, maintenance, healthcare simulation
- What: Extend anchor prompts to 3D/AR scenes for procedure training with spatial waypoints and occlusion‑aware overlays.
- Workflow/Product: 3D anchor grids mapped to world coordinates; multi‑modal Critic checking depth and visibility; HMD deployment.
- Assumptions/Dependencies: 3D asset libraries; interaction design; ergonomic testing; device compatibility.
- Enterprise “compliance explainer” factory — sectors: finance, healthcare, aviation, energy
- What: Ingest regulatory changes and auto‑produce validated training plus assessments; maintain an auditable code‑to‑content chain for audits.
- Workflow/Product: Regulation parser → Planner with legal constraints → governed asset repository → TeachQuiz + human SME sign‑off.
- Assumptions/Dependencies: Legal liability frameworks; regulator acceptance; robust change‑tracking.
- Standardized evaluation for policy/education content — sectors: government, accreditation, NGOs
- What: Adopt TeachQuiz‑style metrics for large‑scale pretesting of public information and educational media before funding or release.
- Workflow/Product: Public evaluation service; domain‑specific quiz banks; bias/fairness checks; correlation studies with human outcomes.
- Assumptions/Dependencies: External validity across populations; governance for fair testing; dataset curation.
- Synthetic teaching data for AI training — sectors: AI/ML
- What: Generate large corpora of code‑grounded educational videos with precise semantic labels to train/align VLMs on reasoning and explanation.
- Workflow/Product: Programmatically varied storyboards; controllable difficulty; paired quizzes; curriculum generation.
- Assumptions/Dependencies: Avoid overfitting to synthetic distributions; licensing for derivative datasets; compute/storage.
- Marketplace of storyboard‑code templates and asset packs — sectors: creator economy, edtech vendors
- What: Commercial ecosystem for reusable lesson templates (e.g., calculus proofs, circuit basics), styles, and compliant icon sets.
- Workflow/Product: Template store integrated in Code2Video Studio; quality badges via TeachQuiz; localization bundles.
- Assumptions/Dependencies: IP/licensing; quality moderation; revenue sharing.
- Cross‑disciplinary science communication at scale — sectors: academia, journals, foundations
- What: “Paper‑to‑Explainer” pipelines producing consistent, audience‑leveled videos for grant reports and public outreach.
- Workflow/Product: Ingest LaTeX/papers → Planner builds tiered narratives → anchor‑aware diagram animations → DOI‑linked repositories.
- Assumptions/Dependencies: Author approvals; sensitive data redaction; journal policies.
- UI/UX co‑design agents with anchor semantics — sectors: software, product design
- What: Generalize the anchor‑grid idea to static/dynamic UI layout tools for precise, LLM‑controllable placement with compile‑time constraints.
- Workflow/Product: Design agents that propose layouts with anchor constraints; ScopeRefine for lint/fix; export to code (React/SwiftUI).
- Assumptions/Dependencies: Rich constraint solvers; design system integration; usability validation.
- Teacher–AI co‑creation platforms — sectors: education
- What: Real‑time collaboration where teachers sketch sequences and the agent fills in animations, quizzes, and variations; shared institutional repositories.
- Workflow/Product: Multi‑user editing; provenance and versioning; analytics on engagement vs. TeachQuiz gains.
- Assumptions/Dependencies: Training and change‑management for educators; identity/rights management.
- Open governance repositories of “code narratives” — sectors: civic tech, open government
- What: Public, auditable repositories where policy explanations are maintained as code with multilingual, accessible builds and change diffs.
- Workflow/Product: CI pipelines render videos per commit; public feedback loops; archival for accountability.
- Assumptions/Dependencies: Institutional adoption; governance for PRs/issues; long‑term hosting.
Notes on common assumptions and dependencies
- Technical stack: Manim (or equivalent renderers), access to capable LLM/VLM APIs, render compute, and storage/CDN for video distribution.
- Content limits: Best for 2D symbolic/diagrammatic content; photoreal procedures may require hybrid or live capture.
- Quality and safety: Human SME review required in regulated/safety‑critical domains; asset licensing and brand compliance must be enforced.
- Cost/latency: Token usage and rendering time may constrain scale; parallelization and ScopeRefine help but budgets matter.
- Evaluation validity: TeachQuiz correlates with human outcomes in reported studies but needs larger, diverse cohorts for policy‑level use.
- Privacy and governance: When adapting to learners or ingesting enterprise policies, ensure data security and compliance (FERPA, HIPAA, GDPR, etc.).
Glossary
- 3Blue1Brown (3B1B): A well-known YouTube channel producing mathematically rigorous, Manim-based educational videos used as high-quality references. Example: "3Blue1Brown (3B1B)"
- Agentic: Refers to systems designed as autonomous agents that plan, act, and refine outputs collaboratively. Example: "an agentic, code-centric framework"
- Autoregressive architectures: Sequence models that generate outputs one step at a time conditioned on previous outputs, used for video generation. Example: "autoregressive architectures"
- Code-centric paradigm: A generation approach that centers on producing and executing code as the primary medium for controlling content and layout. Example: "A code-centric paradigm for educational video generation"
- Diffusion models: Probabilistic generative models that iteratively denoise data to synthesize images or videos. Example: "extend diffusion models into the temporal domain"
- Executable grounding: Ensuring concepts and plans are tied to code that can actually run to produce the intended visuals. Example: "executable grounding"
- External database: A curated repository of reference images and visual assets used to guide accurate and consistent rendering. Example: "an external database"
- Fine-grained spatiotemporal control: Precise manipulation of spatial layout and timing in animations. Example: "fine-grained spatiotemporal control"
- Latent 3D VAEs: Variational Autoencoders operating in a latent space extended to 3D, used to model spatiotemporal video structure. Example: "latent 3D VAEs"
- Manim: An open-source mathematical animation engine used to script and render educational videos. Example: "Manim code"
- Multi-agent collaboration: Coordinated pipelines where multiple specialized agents share tasks and feedback to improve outcomes. Example: "multi-agent collaboration"
- Multimodal feedback: Using combined visual and textual signals (e.g., from VLMs) to refine code and layouts. Example: "multimodal feedback"
- Neuro-symbolic modularity: Architectures that combine neural learning with symbolic tools and structured reasoning. Example: "neuro-symbolic modularity"
- Occupancy table: A data structure tracking which canvas regions (anchors) are occupied, enabling conflict-free element placement. Example: "an occupancy table"
- Occupancy-aware adjustment: Layout refinement that accounts for which regions are already used to avoid overlaps. Example: "occupancy-aware adjustment"
- Parallel Code Generation: Generating and debugging code for different video sections concurrently to reduce latency. Example: "Parallel Code Generation."
- Pixel-space: Direct synthesis of videos as pixels rather than via symbolic or programmatic representations. Example: "pixel-space video synthesis"
- Planner–Coder–Critic pipeline: A tri-agent workflow where planning, coding, and critical refinement are separated and iterated. Example: "PlannerâCoderâCritic pipeline"
- Renderable environment: A programmatically controlled scene where elements can be placed and animated deterministically. Example: "manipulation of a renderable environment"
- ScopeRefine (SR): A scope-guided debugging strategy that escalates from line-level to block-level to global repairs. Example: "ScopeRefine (SR)"
- Space–time UNets: U-Net architectures adapted to jointly model spatial and temporal dimensions for video diffusion. Example: "spaceâtime UNets"
- Storyboard: A structured plan mapping lecture lines to specific animations and timings. Example: "storyboard"
- Symbolic alignment: Ensuring that visual elements (symbols, text, diagrams) correspond accurately to the intended semantic content. Example: "symbolic alignment"
- TeachQuiz: An evaluation protocol that measures knowledge transfer by comparing performance before and after watching a video. Example: "TeachQuiz"
- Temporal coherence: Logical continuity and ordering of concepts over time in a video. Example: "temporal coherenceâconcepts introduced, expanded, and reinforced in logical sequence"
- Text2Video: Generating videos directly from textual prompts using generative models. Example: "Text2Video"
- Token usage: The number of LLM tokens consumed during code generation and refinement, used as an efficiency metric. Example: "token usage"
- Unlearning: Intentionally removing a model’s prior knowledge about a target concept to fairly assess learning from the generated video. Example: "Unlearning."
- Vision-LLM (VLM): Models that jointly process visual and textual inputs for understanding and generation. Example: "vision-LLMs (VLM)"
- VLM-as-a-Judge: An evaluation setup where a VLM rates videos along quality dimensions to approximate human judgments. Example: "VLM-as-a-Judge"
- VideoLLM: A LLM specialized for video understanding and feedback. Example: "VideoLLM"
- Visual Anchor Prompt: A discretized placement scheme where elements are assigned to predefined grid anchors to simplify layout control. Example: "Visual Anchor Prompt"
- Visual programming: Generating visual content by synthesizing and executing code that specifies layouts and animations. Example: "Visual programming"
Collections
Sign up for free to add this paper to one or more collections.

