Lumina-DiMOO: An Omni Diffusion Large Language Model for Multi-Modal Generation and Understanding
Abstract: We introduce Lumina-DiMOO, an open-source foundational model for seamless multi-modal generation and understanding. Lumina-DiMOO sets itself apart from prior unified models by utilizing a fully discrete diffusion modeling to handle inputs and outputs across various modalities. This innovative approach allows Lumina-DiMOO to achieve higher sampling efficiency compared to previous autoregressive (AR) or hybrid AR-Diffusion paradigms and adeptly support a broad spectrum of multi-modal tasks, including text-to-image generation, image-to-image generation (e.g., image editing, subject-driven generation, and image inpainting, etc.), as well as image understanding. Lumina-DiMOO achieves state-of-the-art performance on multiple benchmarks, surpassing existing open-source unified multi-modal models. To foster further advancements in multi-modal and discrete diffusion model research, we release our code and checkpoints to the community. Project Page: https://synbol.github.io/Lumina-DiMOO.
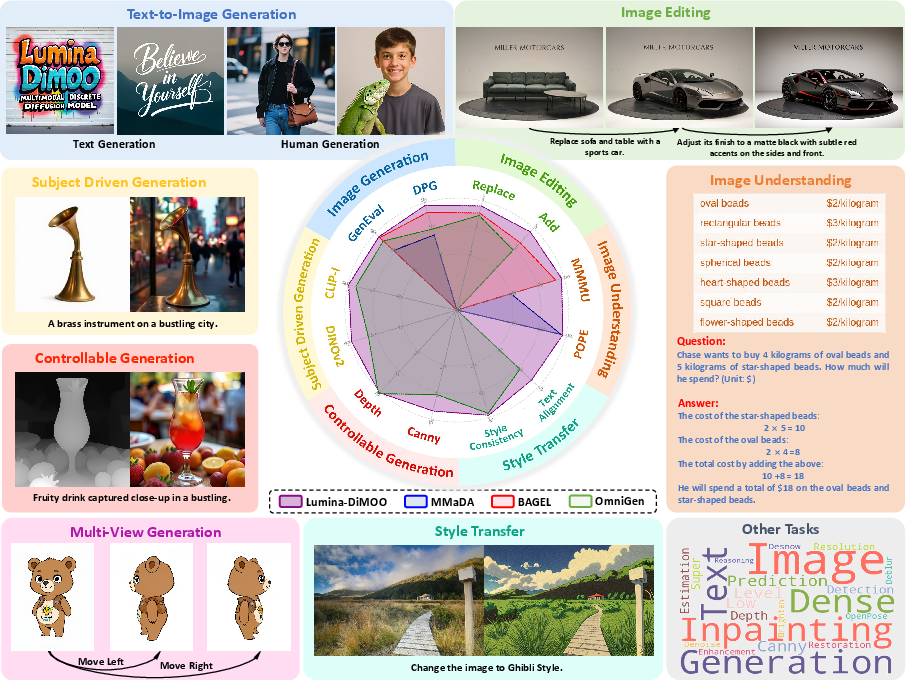
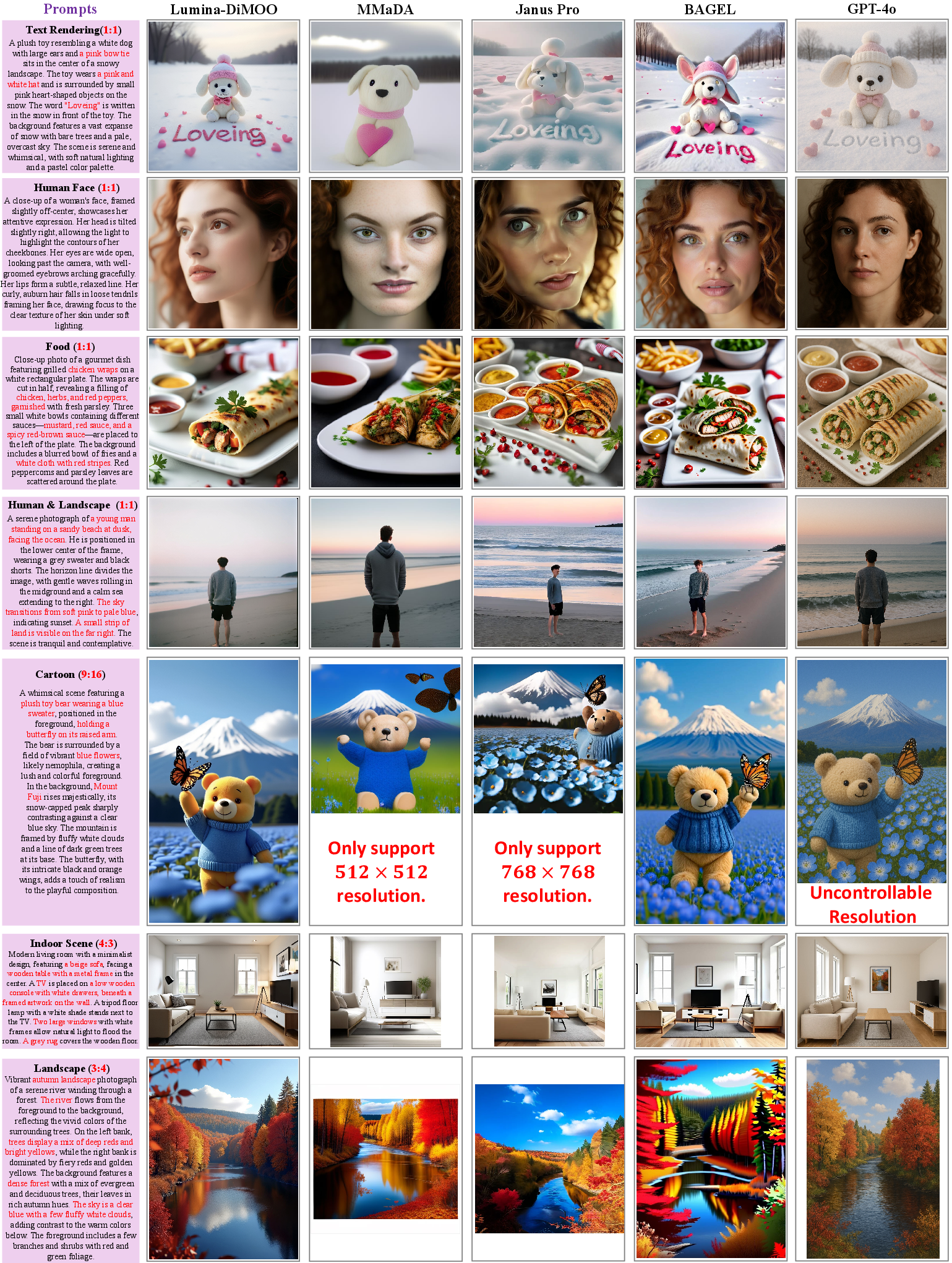





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Lumina-DiMOO, a single AI model that can both understand images (like answering questions about a picture) and create images (from text or by editing an existing picture). It uses a fast “fill-in-the-blanks” style of thinking called discrete diffusion, so it can work much quicker than many older models that generate content one piece at a time. The team also released the code and model so others can use and improve it.
What questions are the researchers asking?
In simple terms, they wanted to know:
- Can one model do many visual tasks well, like text-to-image, image editing, inpainting (filling in missing parts), style transfer, and image understanding?
- Can we make it faster than older models that generate content one token (tiny piece) at a time?
- Can we keep everything truly unified inside one model, instead of relying on extra add-on models for different tasks?
- Can the model learn to improve itself by checking whether its generated images match the meaning of the prompts?
How does the model work?
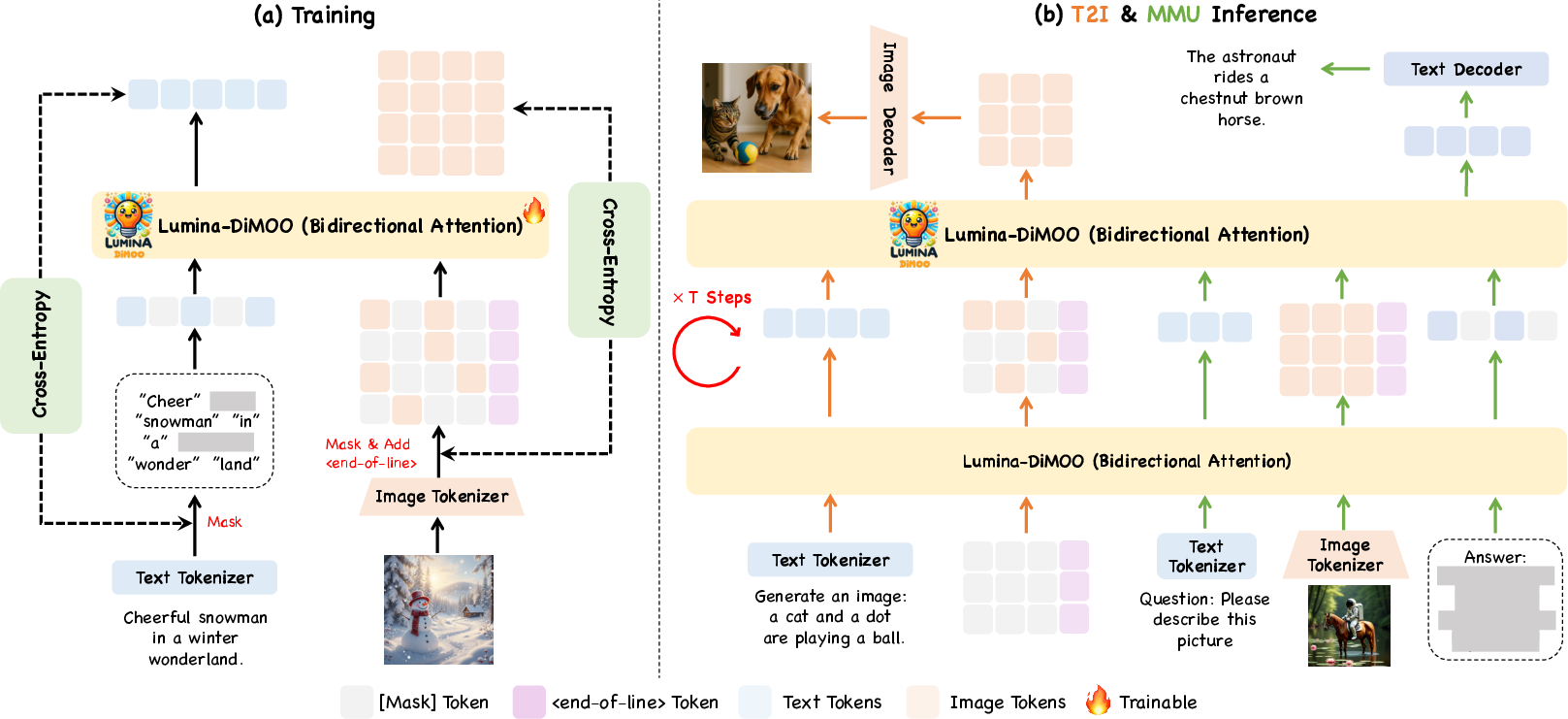
Turning pictures and words into tokens
Computers don’t see images and text the way people do. They turn them into tokens, which you can think of like small LEGO bricks or code numbers.
- Text is already handled as tokens.
- Images are split into a grid and turned into a sequence of image tokens using an “image tokenizer.” Lumina-DiMOO uses a tokenizer that balances quality and speed, so pictures can be rebuilt with good detail without making sequences too long.
- Special tokens mark where an image starts and ends, what kind of control image is given (like a sketch or depth map), and even where each image row ends. That last one helps the model keep track of image shape and aspect ratio (wide vs. tall) even though everything is processed as a 1D list.
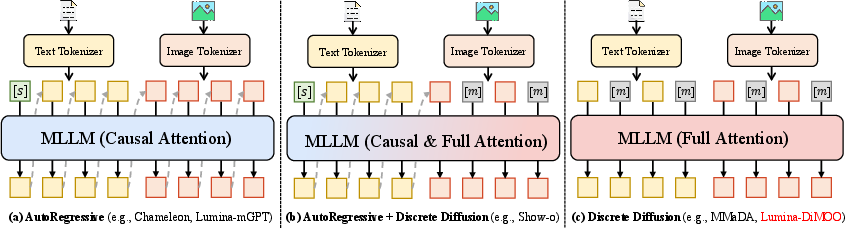
Discrete diffusion: a “fill-in-the-blanks” strategy
Instead of writing text or images left-to-right, one token at a time (which is slow), Lumina-DiMOO uses a masked “fill-in-the-blanks” approach:
- Imagine a crossword puzzle where many squares are covered. The model guesses many covered squares at once, then checks and refines its guesses step by step.
- This is called discrete diffusion. It lets the model:
- Look in both directions (before and after) in the sequence.
- Fill lots of blanks in parallel (faster).
- Improve or “inpaint” missing areas easily.
- Choose flexible orders for what to fill next.
Generating faster: parallel decoding and a smart cache
- Parallel decoding: For image generation, the model predicts many pixels’ tokens at the same time, not one-by-one.
- Max Logit-based Cache (ML-Cache): If the model is very confident about certain tokens (their internal scores—called “logits”—are high), it reuses the previous step’s calculations for those tokens instead of recomputing them. This is like not redoing math on answers you’re already sure about. It speeds things up further without retraining.
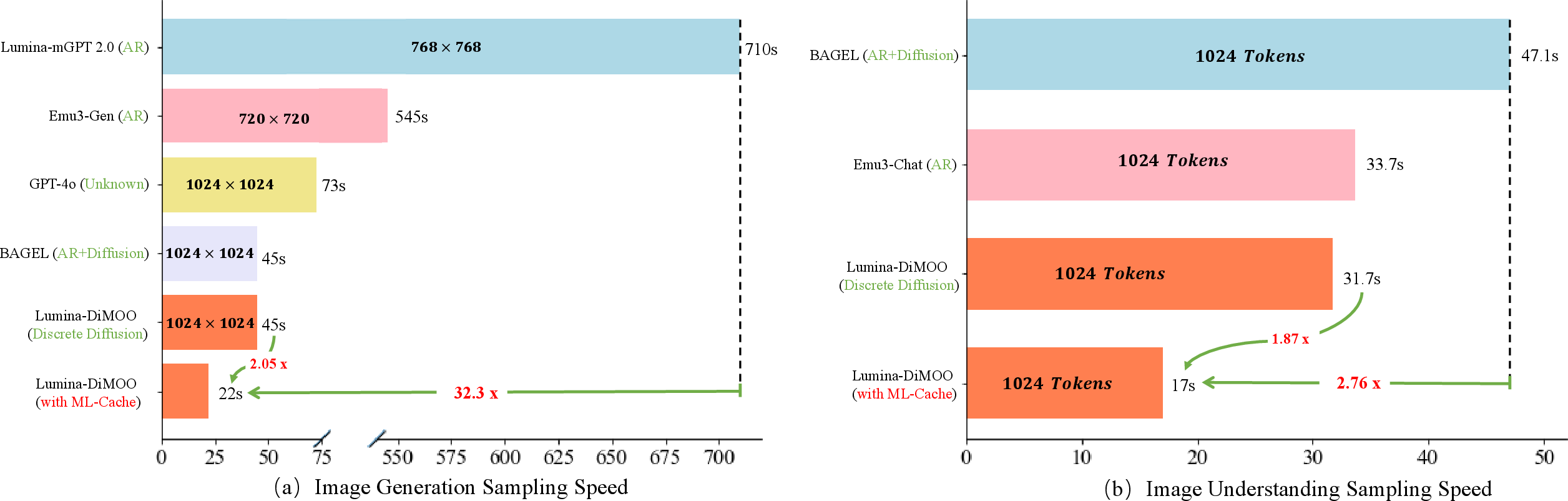
Together, this makes Lumina-DiMOO much faster than older “autoregressive” models (which generate token-by-token). The paper reports up to 32× speed-up over a strong autoregressive baseline, plus about 2× more with the cache.
Handling any image size
Because images are flattened into sequences, they can lose their shape. Lumina-DiMOO inserts a special end-of-line token after each image row—like a newline in text—so it can rebuild the original width and height correctly. This lets it work with many image sizes and shapes.
Training in four steps
The model learns through a staged process:
- Pre-training: Teaches the model to connect text and images by masking random parts and asking it to fill them in at low, then medium resolutions.
- Mid-training: Adds diverse tasks like image editing, style transfer, subject-driven generation, controllable generation, multi-view generation, and teaches it to read special visuals (tables, charts, math, UI screens).
- Supervised fine-tuning: Improves following instructions and boosts overall quality using high-quality example conversations and tasks.
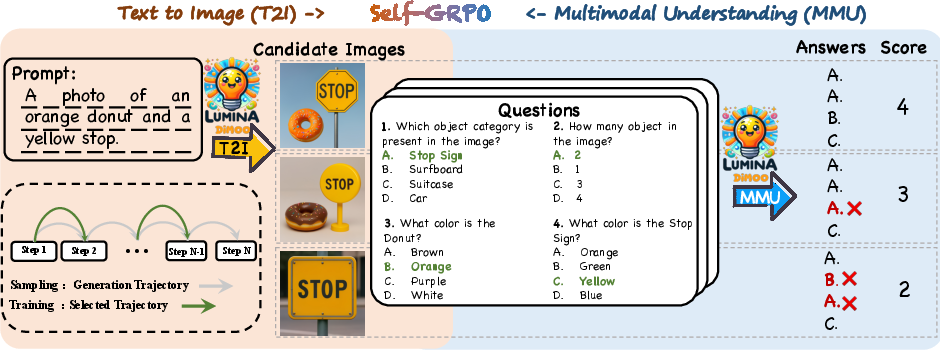
- Self-improvement (Self-GRPO): The model generates images, then “quizzes” itself with questions about those images. If its answers match the prompt and image, it rewards those outputs and learns from them. This links image making (generation) with image understanding in one loop.
What did they find?
- Strong performance across many tasks:
- Text-to-image: On public tests like GenEval and DPG, Lumina-DiMOO beats other open-source unified models and reaches top-tier scores, especially in correctly handling relations (who is where), attributes (colors, counts), and layout.
- Mixed tasks (understanding + generation): It ranks first among open-source models on the UniGenBench leaderboard (maintained by Tencent Hunyuan).
- Much faster generation:
- Up to 32× faster than a representative autoregressive model for text-to-image.
- The ML-Cache adds about another 2× speed-up.
- Flexible image-to-image abilities:
- Zero-shot inpainting: It can fill missing parts without extra special training.
- Interactive retouching: Users can mark specific areas to refine, offering precise, controllable edits that are hard for many other methods.
Why this matters: You get a single, open-source model that’s fast, accurate, and flexible across many visual tasks—without bolting on extra decoders or separate systems.
Why it matters and what could happen next
- Unified and efficient: Doing many visual tasks inside one model makes development simpler, faster, and more consistent.
- Practical uses: Better tools for design, photo editing, advertising, education (explain pictures), accessibility (describe images), and creative workflows (style transfer, multi-view generation).
- Research impact: Open code and checkpoints encourage others to build on this work, explore discrete diffusion for language and vision, and push multimodal AI closer to general-purpose intelligence.
- Future directions:
- Even better low-level image editing (like super-resolution or denoising), where the paper notes room to improve.
- Stronger self-improvement loops that keep aligning what the model draws with what it understands.
- Wider support for videos, 3D, and complex document understanding using the same unified approach.
In short, Lumina-DiMOO shows that a single, fast, “fill-in-the-blanks” model can handle many image tasks at high quality, and it points to a future where one unified system can both understand and create complex visual content.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper and would benefit from targeted follow-up work:
- Quantitative evaluation of image-to-image tasks is largely absent: no standardized metrics or protocols for editing, style transfer, subject-driven generation, controllable generation, multi-view generation, inpainting, or the proposed “interactive retouching” (e.g., identity preservation, CLIP alignment, mask fidelity, edit locality, geometry consistency).
- Image understanding capability is under-reported: no results on core VQA/vision-language benchmarks (e.g., MME, POPE, GQA, TextCaps, ChartQA, DocVQA, UI parsing), nor ablations attributing gains to Stage-II/III/IV.
- Low-level vision performance is explicitly noted as poor without analysis: no diagnosis of failure modes (e.g., VQ quantization limits, loss design), and no experiments testing remedies (e.g., hybrid latent decoders, specialized tokenizers, multi-scale supervision).
- “Arbitrary resolution” claim is not stress-tested: no evaluation beyond 512–1024 on extreme aspect ratios, ultra-high resolutions (2K–4K), or long/tall images; no latency/memory scaling curves; no comparison to 2D positional encodings vs the <end-of-line> workaround.
- Max Logit-based Cache (ML-Cache) is introduced without a systematic quality–efficiency study: default cache_ratio, warmup_ratio, refresh_interval are unspecified; no ablations across tasks/resolutions; no analysis of error accumulation, robustness, or failure cases.
- Sampling design choices lack ablations: number of refinement steps T, cosine re-mask schedule, sampling temperature/top-k, and full-image vs spatially blocked decoding are not compared to alternatives (e.g., confidence-adaptive or coarse-to-fine schedules).
- Semi-autoregressive block-wise decoding for text understanding is sensitive to block size and early stopping, but these sensitivities are not measured; the risk of premature termination and degraded long-form answers is unquantified; adaptive block sizing is unexplored.
- LLaDA-based initialization is asserted to help but the promised ablation (Section “initial”) is missing: no evidence on sample efficiency, convergence, or retention of pure language ability vs training from scratch; no catastrophic forgetting analysis.
- Tokenizer choice is under-explored: aMUSEd-VQ is selected despite “lack of semantic information”; no controlled comparisons vs semantically-informed or joint-learned tokenizers; no studies on how tokenizer design affects understanding tasks or dense predictions.
- Vocabulary expansion and partial parameter training could limit fusion: only visual/special tokens are learned; no comparison to full-model finetuning, LoRA/adapters, or cross-modal fusion modules; impact on language perplexity and multimodal calibration is unknown.
- Classifier-free guidance for discrete diffusion lacks detail: guidance scale ranges, conditional dropout rates, impact on diversity vs fidelity, and interaction with ML-Cache are not reported.
- Self-GRPO leaves key details and risks unresolved: the reference policy p_thetaref is not defined; the removal of the old policy may induce instability; no variance or reward-hacking analysis; sensitivity to α (temperature) and β (KL) is unreported.
- Reward construction is synthetic and potentially noisy: DSG-extracted triples and multiple-choice distractors may bias learning; the effect of label noise on both T2I and MMU is unmeasured; generalization to open-ended QA and reasoning (beyond MCQ) is untested.
- Trajectory-consistent RL computes gradients on selected timesteps (T_sel), but selection criteria are unspecified; no ablation of T_sel size/placement or the risk of missing late-stage refinements.
- Data provenance and bias are insufficiently audited: heavy use of model-generated captions (Qwen2.5-VL) and synthetic data may propagate biases and errors; no demographic, content, or domain-bias assessment; no evaluation on human-annotated, real-world datasets for contrast.
- Potential data contamination with evaluation prompts/sets (e.g., GenEval, UniGenBench) is not addressed; no deduplication or leakage checks are described.
- Safety, misuse, and provenance are not discussed: zero-shot inpainting and interactive editing raise content manipulation risks; no safety filters, watermarking, provenance (C2PA), or red-teaming evaluations are provided.
- Robustness and generalization are untested: no stress tests for adversarial/ambiguous prompts, rare objects, OOD concepts, or compositional generalization; multilingual prompts and non-English support are not evaluated.
- Subject-driven generation lacks identity metrics: no standardized identity preservation measures (e.g., FaceID similarity, DreamBench) or comparisons to identity-locking baselines.
- “Dense prediction” support is asserted without benchmarks: no tasks (e.g., segmentation, depth/normal estimation) or metrics (IoU, RMSE) are reported; how discrete tokenization supports pixel-accurate outputs remains unclear.
- Computational profile is opaque: training FLOPs, wall-clock, GPU-hours, energy/CO2, and inference throughput vs resolution are not reported; bidirectional attention’s memory footprint and maximum context length limits are unstated.
- Speedup claims lack full context: the “32× vs AR” and “2× via ML-Cache” gains are not normalized for hardware, KV cache usage, batch size, or end-to-end latency (tokenization/decoding included); quality–latency Pareto curves are missing.
- Zero-shot inpainting is not quantitatively compared to diffusion inpainting baselines: no metrics for masked region fidelity, boundary consistency, or prompt adherence.
- Text rendering in images (OCR-like content) is under-explored: UniGenBench “Text” remains challenging broadly, but no targeted evaluation or training strategy (e.g., text-aware rewards) is provided for Lumina-DiMOO.
- Extensibility to additional modalities is not demonstrated: while the discrete framework suggests generality, no experiments explore audio, video, or 3D tokenizers; integration challenges (temporal tokens, long contexts) remain open.
- Theoretical understanding of multimodal discrete diffusion is limited: no analysis of joint vocabulary co-adaptation, error propagation across modalities, or convergence/consistency properties under re-masking schedules.
- Failure mode analysis is missing: no taxonomy of common T2I/understanding errors (attribute binding, spatial relations, counting) to guide targeted data curation, training, or reward shaping.
- Reproducibility gaps persist: several critical hyperparameters (mask ratio distributions, T, cache/refresh schedules, block sizes) are unspecified; the status and completeness of released code/checkpoints, data filters, and evaluation scripts are not verified in the text.
Glossary
- Autoregressive (AR): A modeling approach that generates sequences by predicting one token at a time based on previous tokens. "relied on a purely autoregressive (AR) architecture."
- Bidirectional attention: An attention mechanism that allows the model to consider both past and future tokens simultaneously. "dLLMs offer distinctive advantages such as bidirectional attention, iterative refinement, flexible generation order, parallel decoding, and infilling capabilities."
- Block-wise inference: A decoding strategy that processes outputs in contiguous blocks, often mixing parallel prediction within a block and sequential progression across blocks. "A major drawback of block-wise inference is inefficiency: the semi-autoregressive procedure always generates the full predefined length in a next-block manner, even though the model often terminates its response earlier."
- Classifier-Free Guidance (CFG): A technique to steer generative models by mixing conditional and unconditional outputs to adjust adherence to prompts. "we employ classifier-free guidance (CFG), a commonly used strategy in the field of image generation."
- Codebook: The discrete set of indices representing compressed image tokens in a vector-quantized tokenizer. "we integrate 8,192 visual tokens from the pre-trained aMUSEd-VQ codebook."
- Cosine sampling schedule: A timestep schedule based on a cosine function used to determine how many tokens to re-mask or refine each step. "We use a cosine sampling schedule to determine the number of tokens to re-mask at the timestep ."
- Cosine similarity: A measure of similarity between two vectors based on the cosine of the angle between them, often used to compare logits or representations. "logits of tokens with top 94\% maximal logit have over 0.99 cosine similarity."
- Cross-entropy (masked cross-entropy): A loss function measuring the discrepancy between predicted and true token distributions, computed only on masked positions. "Training minimizes the masked cross-entropy over randomly sampled mask ratios applied to both text and image positions:"
- Dense prediction: Tasks that produce outputs for many or all spatial positions (e.g., per-pixel labels), rather than sparse or global descriptions. "including image editing, style transfer, subject-driven generation, controllable generation, multi-view generation, and dense prediction"
- Diffusion head: An added module that decodes tokens or features using diffusion processes after an autoregressive stage. "added a diffusion head after the AR process to decode image tokens, enhancing quality but sacrificing the unified model concept."
- Discrete diffusion: A diffusion modeling approach operating over discrete token spaces instead of continuous noise vectors. "utilizing a fully discrete diffusion modeling to handle inputs and outputs across various modalities."
- dLLM (diffusion-based LLM): A LLM that uses discrete diffusion mechanisms rather than purely autoregressive decoding. "Recent advancements in diffusion-based LLMs (dLLMs) are built upon the theory of discrete diffusion"
- Early stopping strategy: A procedure to terminate decoding once a specified condition is met, reducing unnecessary computation. "we introduce an early stopping strategy, which halts inference immediately once the current block has been completed and an </answer> token is detected"
- End-of-line token: A special token inserted to mark the end of each row in flattened image sequences, preserving 2D structure. "we introduce a <end-of-line> token after the last image token of each row, serving as an explicit delimiter of the structure."
- Forward and reverse process (in diffusion): The forward process progressively corrupts data (e.g., masking), and the reverse process reconstructs it. "introduces a special [mask] state in the forward process—transforming data into [mask]—and recovers data in the reverse process"
- GRPO: A reinforcement learning algorithm (Group Relative Policy Optimization) that optimizes a policy using relative rewards and stabilizing regularization. "The GRPO strategy requires computing the outputs of the old policy $\pi_{\theta_{old}$ and then optimizing the current policy model ."
- Hybrid AR-Diffusion: An architectural paradigm combining autoregressive generation with diffusion-based decoding. "previous autoregressive (AR) or hybrid AR-Diffusion paradigms"
- Image tokenizer: A model that converts images into sequences of discrete tokens for processing by transformers. "The discrete image tokenizer is a fundamental component in discrete diffusion modeling paradigms, crucial to the ultimate performance of visual generation and understanding tasks."
- Infilling: The capability to fill in masked or missing tokens or regions in a sequence or image. "dLLMs offer distinctive advantages such as bidirectional attention, iterative refinement, flexible generation order, parallel decoding, and infilling capabilities."
- Inpainting (zero-shot inpainting): Editing images by filling masked regions without training on explicit examples of the specific task. "Beyond its speed advantages, the discrete diffusion architecture enables Lumina-DiMOO to execute zero-shot inpainting."
- Iterative refinement: Repeatedly updating predictions over multiple timesteps to progressively improve outputs. "dLLMs offer distinctive advantages such as bidirectional attention, iterative refinement, flexible generation order, parallel decoding, and infilling capabilities."
- Joint vocabulary: A unified set of tokens that includes text, image, and special tokens used by the model. "mixed text-image sequence drawn from the joint vocabulary (text tokens, image tokens, and special tokens, details in subsequent paragraph)."
- KL-regularized policy updates: Reinforcement learning updates that include a Kullback–Leibler term to keep the policy close to a reference, stabilizing training. "By combining KL-regularized policy updates, memory-efficient training, and multi-modal reward supervision, it closes the training loop between generation and understanding."
- KV-Cache: A caching mechanism that stores key/value attention states to accelerate autoregressive decoding. "Autoregressive models can be losslessly accelerated through KV-Cache."
- Logit: The unnormalized score output by a model before applying softmax to obtain probabilities. "tokens with high maximal logit values often share similar representations with previous steps."
- Log-likelihood: The logarithm of the probability assigned by the model to observed data, used as an optimization objective. "The T2I log-likelihood is defined as:"
- Mask ratio: The fraction of tokens in a sequence that are replaced with a mask during training or sampling. "A mask set is sampled by a mask ratio "
- Masked diffusion: A discrete diffusion method that uses a special mask token in the forward process and reconstructs tokens in the reverse process. "masked diffusion has emerged as the de facto standard due to its simplicity and effectiveness"
- MaskGIT: A parallel token generation algorithm that iteratively masks and predicts tokens. "Following MaskGIT~\citep{chang2022maskgit}, we partition the image generation process into four stages."
- Max Logit-based Cache (ML-Cache): An acceleration method that reuses representations of tokens with high maximal logits to reduce computation. "we introduce a training-free Max Logit-based Cache (ML-Cache) method for Lumina-DiMOO, resulting in an additional 2x boost in sampling speed."
- Multi-view generation: Producing images of the same subject from different viewpoints. "including image editing, style transfer, subject-driven generation, controllable generation, multi-view generation, and dense prediction"
- Next-token prediction: The standard autoregressive decoding strategy that predicts one token at a time conditioned on previous tokens. "Their next-token prediction paradigm resulted in extremely slow generation speeds, often requiring several minutes, which significantly affected user experience."
- Parallel decoding: Generating multiple tokens simultaneously instead of strictly sequentially. "dLLMs offer distinctive advantages such as bidirectional attention, iterative refinement, flexible generation order, parallel decoding, and infilling capabilities."
- Parallel prediction-sampling-remasking: The iterative procedure in discrete diffusion that predicts, samples, and re-masks tokens in parallel at each timestep. "generation starts from fully masked tokens and proceeds for refinement steps via parallel prediction-sampling-remasking"
- Raster-scan generation order: A sequential ordering that follows row-by-row (raster) traversal, often inefficient for large token grids. "inefficiencies from raster-scan generation orders"
- Refresh interval: A hyperparameter controlling how frequently all tokens are fully recomputed to mitigate accumulated approximation error. "we compute all tokens every refresh_interval steps to alleviate the error accumulation."
- RoPE (Rotary Positional Embeddings): A positional encoding technique that rotates representations to encode relative positions. "uses 1D RoPE designed for text"
- Semi-autoregressive strategy: A decoding approach that mixes parallel prediction within blocks and sequential progression across blocks. "we adopt a semi-autoregressive strategy."
- Style transfer: Generating an image that adopts the visual style of a reference while preserving content or constraints. "including image editing, style transfer, subject-driven generation, controllable generation, multi-view generation, and dense prediction"
- Subject-driven generation: Generating images that preserve or emphasize a specific subject identity or attributes. "including image editing, style transfer, subject-driven generation, controllable generation, multi-view generation, and dense prediction"
- Top-k rule: Selecting the highest-confidence k items (e.g., tokens) at a given step for masking or prediction decisions. "we select the re-masked image tokens with a top- rule according to each token's confidence"
- Trajectory-consistent reinforcement learning: RL training that aligns reward assignment and gradient computation with the actual sampling trajectory. "Self-GRPO unifies text-to-image (T2I) generation and multi-modal understanding (MMU) under trajectory-consistent reinforcement learning."
- Unmasking network: The model component used to predict original tokens at masked positions during diffusion steps. "We only feed the tokens to compute into the unmasking network."
Practical Applications
Immediate Applications
The following applications can be deployed now using Lumina-DiMOO’s demonstrated capabilities (text-to-image, image-to-image editing, controllable generation, multi-view generation, and image understanding), its speed advantages (parallel discrete diffusion + ML-Cache), and open-source release of code and checkpoints.
- Creative and design tooling (sector: software, media, advertising)
- Rapid ad creative and social content generation from text prompts with brand-consistent variations (batch generation, CFG control).
- Interactive retouching for precise, local edits via zero-shot inpainting (e.g., object cleanup, artifact removal, background fixes) without task-specific fine-tuning.
- Style transfer and subject-driven generation for content reuse across campaigns and channels (pose, depth, edge control using special tokens like <openpose>, <depth>, <hed>, <canny>).
- Workflow: “brief → prompt → parallel sampling → interactive retouch → export,” integrated as plugins for Adobe/Blender/Figma or a web app.
- Assumptions/dependencies: human-in-the-loop quality control; adherence to brand and IP policies; GPU inference; prompt engineering; watermark/provenance policies external to the paper.
- E-commerce imagery and product display (sector: retail)
- Automated product photo enhancement (inpainting, background standardization, clutter removal).
- Multi-view generation for consistent 360° or alternate angles for product listings.
- Workflow: “SKU metadata → prompt + reference → multi-view generation → QC → publish.”
- Assumptions/dependencies: per-category fine-tuning may improve consistency (e.g., fashion vs. electronics); image tokenization fidelity; legal compliance for synthetic imagery.
- Document, chart, and UI understanding (sector: finance, enterprise software, QA)
- Convert charts/tables/UI screenshots into structured summaries or test cases (trained domains: tables, charts, math/geometry, UI).
- Generate natural language reports from dashboards; assist QA by parsing UI states to generate test scripts.
- Workflow: “ingest screenshot → block-wise semi-autoregressive text generation → early stopping → structured outputs.”
- Assumptions/dependencies: domain-specific lexicon/adaptation improves accuracy; human validation for regulated processes; the tokenizer’s limited semantics mitigated by scaled understanding data.
- Education content authoring and grading support (sector: education)
- Generate and explain geometry diagrams, charts, and instructional visuals; produce practice problems with answer keys.
- Visual question answering over educational images (e.g., math figures, tables).
- Workflow: “teacher prompt → image + explanations → export to LMS.”
- Assumptions/dependencies: teacher review; alignment to curricula; guardrails to prevent hallucinations.
- Synthetic data generation for perception and vision research (sector: robotics, autonomy)
- Create controllable, labeled scenes via depth/pose/edge conditioning to augment training datasets.
- Multi-view generation for consistency checks and domain randomization.
- Workflow: “spec → control signals → parallel generation → dataset curation.”
- Assumptions/dependencies: domain gap to real-world; need photorealism calibration; dataset governance.
- Privacy and compliance operations (sector: policy, public sector, healthcare admin)
- Redaction and masking of sensitive regions in images (faces, IDs, PHI) via interactive inpainting.
- Generate accessible alt-text for images (image understanding to text).
- Workflow: “ingest → detect/label → interactive retouch → compliance review.”
- Assumptions/dependencies: organizational policies and approvals; accuracy of sensitive region identification; not for medical diagnosis.
- Inference acceleration for multi-modal apps (sector: software infrastructure)
- Deploy training-free Max Logit-based Cache (ML-Cache) to reduce step compute while preserving quality, with tunable warmup/refresh schedules.
- Immediate speedups for discrete diffusion inference pipelines and services.
- Assumptions/dependencies: quality-speed trade-off tuning; monitoring for error accumulation; bidirectional attention constraints.
- Multi-modal API productization (sector: developer platforms, SaaS)
- Provide endpoints: text-to-image, image-to-image editing, controllable generation, interactive retouching, chart/UI-to-text.
- Include throughput knobs (parallel sampling, ML-Cache, early stopping) for cost-aware deployment.
- Assumptions/dependencies: GPU provisioning; request-level guardrails; licensing of model and datasets.
- Marketing A/B testing at scale (sector: advertising/marketing analytics)
- Generate hundreds of controlled variants (layout, color, attributes, position) for prompt-driven experiments.
- Workflow: “experiment spec → batch generation (cosine re-mask schedule) → KPI measurement → iterate.”
- Assumptions/dependencies: campaign guardrails; tracking consent and synthetic content disclosure.
- Research and benchmarking (sector: academia)
- Use the open-source model as a baseline for unified discrete diffusion; evaluate on GenEval/DPG/UniGenBench; reproduce speed gains with parallel sampling + ML-Cache.
- Apply Self-GRPO to co-train generation and understanding on custom prompts/QAs.
- Assumptions/dependencies: compute budget; availability of curated prompts/QAs; ethical data use.
Long-Term Applications
These require further research, domain adaptation, scaling, safety alignment, or integration with external systems (e.g., 3D, medical, compliance pipelines).
- On-device multi-modal assistants (sector: consumer software, accessibility)
- Real-time captioning and interactive retouching on mobile/edge devices using optimized dLLMs (quantization, caching, distillation).
- Assumptions/dependencies: significant model optimization; hardware acceleration; robust safety controls.
- Design-to-3D asset pipelines (sector: gaming, AR/VR, e-commerce)
- Bridge multi-view generation with 3D reconstruction (NeRF/mesh) for turnkey asset creation from text/specs.
- Assumptions/dependencies: coupling with 3D toolchains; geometric consistency; IP/brand validation.
- High-reliability report automation from visual dashboards (sector: finance, operations)
- End-to-end “dashboard → narrative → compliance-ready report,” with verifiable grounding.
- Assumptions/dependencies: strict audit trails; symbolic verification; domain-specific evaluation; human audit.
- Medical education and anonymization toolkits (sector: healthcare education, compliance)
- Generate educational visuals and anonymize clinical images safely; assist in layout explanations and diagram understanding.
- Assumptions/dependencies: domain-specific training (medical images), rigorous validation, regulatory approvals; not for diagnosis.
- Scientific visualization copilots (sector: R&D, policy communication)
- Generate accurate plots from data, interpret them (chart understanding), and produce reproducible artifacts.
- Assumptions/dependencies: data integrity constraints; standardized pipelines; provenance and reproducibility policies.
- Fact-consistent editorial illustration for media (sector: newsrooms)
- Create illustrations aligned with verified facts and world knowledge, reducing misinformation risks.
- Assumptions/dependencies: advanced grounding to knowledge sources; media ethics and review processes.
- Urban planning and public engagement (sector: government/policy)
- Scenario visualizations (multi-view, controllable generation) to illustrate proposed changes and gather feedback.
- Assumptions/dependencies: fidelity to planning data; disclaimers about synthetic visuals; stakeholder approval.
- Robotics sim-to-real training (sector: robotics)
- Generate structured, controllable visual environments with pose/depth guidance; eventually extend to video for temporal learning.
- Assumptions/dependencies: physics realism; video-capable diffusion; sim-to-real validation.
- Accessible software interfaces and real-time UI assistance (sector: accessibility, productivity)
- Parse complex UIs and provide stepwise guidance or automation scripts for users with accessibility needs.
- Assumptions/dependencies: robust UI understanding across apps; privacy guarantees; user consent.
- Standardization and governance for unified discrete diffusion (sector: standards bodies, policy)
- Develop benchmarks, best practices, and safety frameworks for multi-modal dLLMs (content integrity, watermarking, provenance).
- Assumptions/dependencies: cross-industry collaboration; regulatory input; open evaluations.
- Multi-modal IDEs for product teams (sector: software/product design)
- Unified platforms where specs, UI screenshots, and prompts yield design comps, assets, and test plans.
- Assumptions/dependencies: integration across design/dev tools; role-based access controls; organizational buy-in.
Notes on feasibility and constraints across applications:
- Compute and deployment: While faster than AR baselines (32x speedup + ~2x ML-Cache), high-resolution generation still requires GPU resources; production SLAs need throughput tuning.
- Safety and compliance: The paper does not implement watermarking/provenance; organizations must add content integrity layers and policies to mitigate misuse (e.g., deepfakes).
- Domain generalization: Strong on general imagery and structured visual domains (tables/charts/UI), but low-level vision tasks (e.g., super-resolution) are currently weak and should not be relied upon without further research.
- Data and licensing: Ensure legal use of datasets and prompts; audit synthetic content in regulated sectors.
- Human oversight: Critical for regulated or high-stakes settings (finance, healthcare, public policy) to manage errors and ensure trust.
Collections
Sign up for free to add this paper to one or more collections.