- The paper presents Vlaser, a novel VLA model that integrates high-level embodied reasoning with low-level control through a two-stage training process.
- It employs a vision-language backbone and an action expert module, utilizing InternVL3 and flow matching to enhance robotic task planning and spatial reasoning.
- Experiments show Vlaser significantly outperforms benchmarks in embodied QA, grounding, spatial reasoning, and planning, demonstrating robust real-world potential.
Vlaser: Vision-Language-Action Model with Synergistic Embodied Reasoning
Introduction
The paper introduces Vlaser, a Vision-Language-Action (VLA) model that integrates high-level reasoning with low-level control for embodied agents. Vlaser leverages the Vlaser-6M dataset to bridge embodied reasoning with VLA policy learning. The model achieves state-of-the-art performance across various embodied reasoning benchmarks, systematically exploring the impact of Vision-LLM (VLM) initializations on supervised VLA fine-tuning.
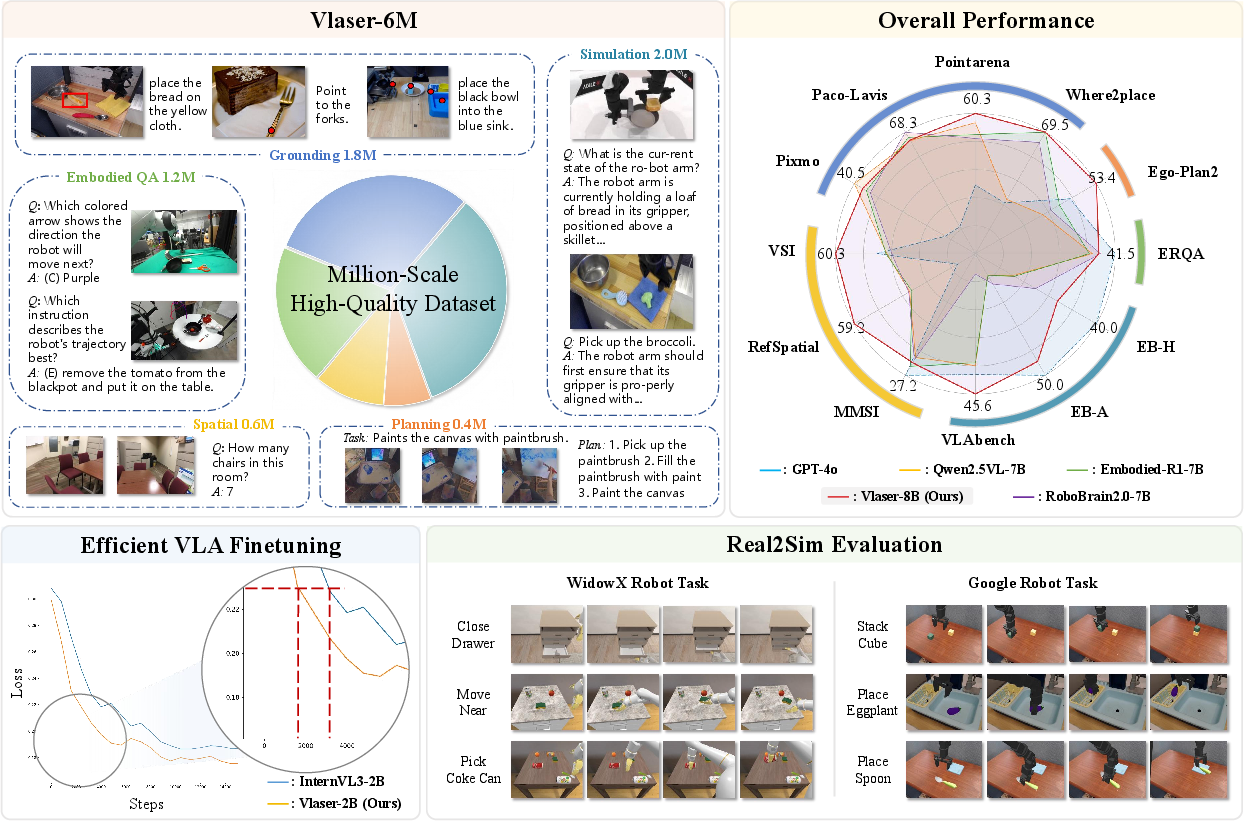
Figure 1: Overall framework, capabilities, and evaluation of Vlaser.
Methodology
Model Structure
Vlaser consists of two primary components: a vision-language backbone and an action expert module. The backbone enhances embodied reasoning capabilities, utilizing InternVL3 as a basis for vision and language encoding. It integrates superior multimodal understanding necessary for task planning and spatial reasoning.
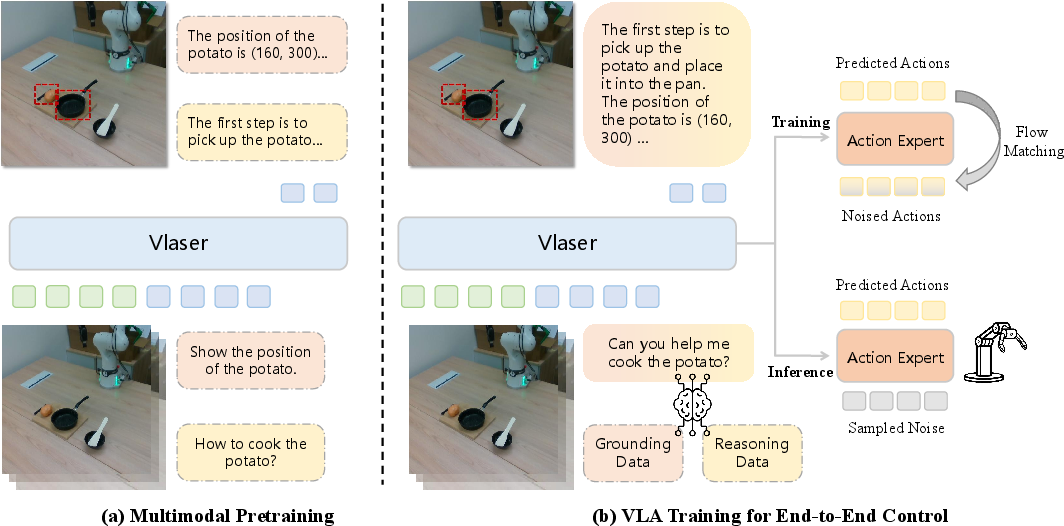
Figure 2: An illustration of Vlaser architecture.
The action expert module incorporates flow matching for generating low-level control actions, supporting efficient robot policy learning and execution.
Data Engine
The Vlaser-6M data engine systematically compiles diverse data from various public sources for embodied QA, grounding, spatial reasoning, and planning. This data supports the model's ability in reasoning across multiple domains, enhancing both open-loop and closed-loop control performance.

Figure 3: An illustration of Vlaser-6M data engine for in-domain general QA samples.
Training Recipe
Vlaser encompasses a two-stage training approach: multimodal pretraining for embodied reasoning, followed by VLA-specific fine-tuning. This method ensures robust adaptation from broad pretraining data to domain-specific applications, facilitating the transition from perception to actionable control tasks.
Experiments
Vlaser outperforms existing models on diverse embodied reasoning benchmarks by a significant margin, indicating its superior generalization capabilities in embodied QA, grounding, spatial reasoning, and planning.

Figure 4: An illustration of Vlaser-6M data engine for in-domain embodied grounding QA sample.
Its performance in simulation environments demonstrates high efficacy in handling complex manipulation tasks, proving its potential for real-world robotic applications.

Figure 5: An illustration of Vlaser-6M data engine for in-domain spatial reasoning QA sample.
In-Domain Data Analysis
The importance of in-domain data is evident, as Vlaser shows how strategic data selection greatly influences downstream success in VLA tasks. Specifically, in-domain multimodal QA pairs help enhance embodied perception and action planning capabilities.

Figure 6: Qualitative samples in SimplerEnv on WidowX Robot Tasks.
Vlaser builds on previous efforts in extending VLMs into VLA models, incorporating advanced reasoning tasks within embodied AI paradigms. It innovatively combines state-of-the-art architecture with meticulously curated datasets, redefining benchmarks for embodied intelligence.
Conclusion and Future Work
Vlaser represents a significant step forward in embodied AI, setting a new standard across varied reasoning domains. Future work can explore reducing domain gaps further and enhancing real-world dataset alignment. The deployment of such VLA models opens avenues for more autonomous and intelligent robotic systems.

Figure 7: Qualitative samples in SimplerEnv on Google Robot Tasks.

