BroRL: Scaling Reinforcement Learning via Broadened Exploration
Abstract: Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a key ingredient for unlocking complex reasoning capabilities in LLMs. Recent work ProRL has shown promise in scaling RL by increasing the number of training steps. However, performance plateaus after thousands of steps, with clear diminishing returns from allocating more computation to additional training. In this work, we investigate a complementary paradigm for scaling RL, BroR-Lincreasing the number of rollouts per example to hundreds to exhaustively Broaden exploration, which yields continuous performance gains beyond the saturation point observed in ProRL when scaling the number of training steps. Our approach is motivated by a mass balance equation analysis allowing us to characterize the rate of change in probability mass for correct and incorrect tokens during the reinforcement process. We show that under a one-step RL assumption, sampled rollout tokens always contribute to correct-mass expansion, while unsampled tokens outside rollouts may lead to gains or losses depending on their distribution and the net reward balance. Importantly, as the number of rollouts per example N increases, the effect of unsampled terms diminishes, ensuring overall correct-mass expansion. To validate our theoretical analysis, we conduct simulations under more relaxed conditions and find that a sufficiently large rollout size N-corresponding to ample exploration-guarantees an increase in the probability mass of all correct tokens. Empirically, BroRL revives models saturated after 3K ProRL training steps and demonstrates robust, continuous improvement, achieving state-of-the-art results for the 1.5B model across diverse benchmarks.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper introduces a new way to train AI models to think and reason better. The method is called BroRL, short for “Broad Reinforcement Learning.” The key idea is simple: when you train a model with reinforcement learning (RL), don’t just take a few tries (rollouts) for each question—take hundreds. By exploring many more possible answers per question during training, the model keeps improving instead of getting stuck.
What questions the paper tries to answer
The authors ask:
- Why do today’s reinforcement learning methods for reasoning models stop improving after a while?
- Can we keep improving by exploring more possible answers per training example (i.e., using many more rollouts)?
- Is there a solid reason (theory) to expect that “more exploration per step” will work better than “more training steps”?
- Will this idea also be faster and more efficient in practice?
How the method works, in everyday language
First, a few simple terms:
- Reinforcement Learning with Verifiable Rewards (RLVR): The model tries to solve problems (like math or code). If its answer can be automatically checked (right or wrong), it gets a reward. Right answers get positive reward; wrong answers get negative or zero reward.
- Rollouts: Think of these as “attempts.” For each question, the model writes out several full answers. With BroRL, instead of 16 attempts per question, you might use 512 or even more.
- Exploration: Trying many different ways to answer the same question so the model learns what works and what doesn’t.
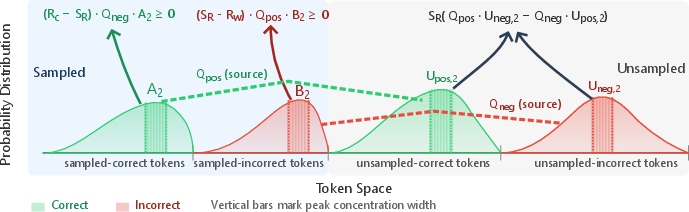
The paper’s key analogy: imagine all the model’s “belief” (probability) is like sand split between two buckets—one bucket for correct tokens (pieces of text that lead to correct answers) and one for incorrect tokens. Each RL update moves sand from one bucket to the other.
- Sampled sand (what the model actually tried in its rollouts): This always helps. When a correct token is rewarded, sand shifts into the “correct” bucket. When an incorrect token is punished, sand moves out of the “incorrect” bucket and effectively into the “correct” bucket.
- Unsampled sand (tokens the model didn’t try this time): This can help or hurt, depending on how things are distributed. But here’s the trick—if you increase the number of rollouts a lot, the amount of unsampled sand shrinks, so its effect fades.
So, by taking many rollouts per question, you mostly get the good effects (more sand to correct) and reduce the risky, unpredictable effects (from unsampled tokens). That makes learning more stable and reliable.
A small technical term that matters:
- Pass@k: If you let the model try k times on a problem, pass@k is the chance it solves it at least once. When the model puts more “probability sand” on correct tokens, pass@k goes up.
What they did to test the idea
They used three levels of testing:
- Theory (math reasoning about updates)
- They wrote down a “mass balance” equation that tracks how much probability moves to correct vs. incorrect tokens in one RL update.
- They proved that the part based on sampled rollouts always helps correct tokens.
- They showed the part based on unsampled tokens can sometimes hurt—but its influence shrinks as the number of rollouts N gets larger.
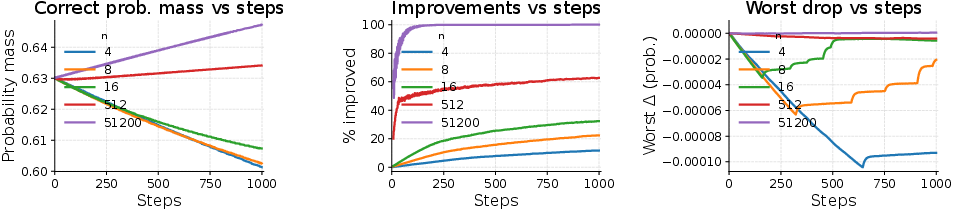
- Simulations (controlled experiments with fake tokens)
- They built a simple simulator and varied N (like 4, 8, 16, 512, 51,200).
- As N got bigger, the simulator showed:
- Faster growth of probability on correct tokens.
- Fewer “bad drops” where correct tokens accidentally lose probability.
- At very large N, those bad drops basically disappeared (no “forgetting” of what’s correct).
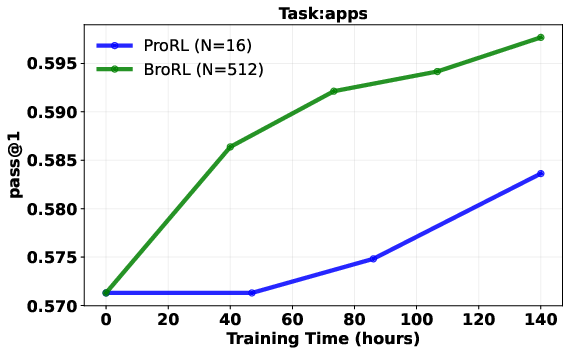
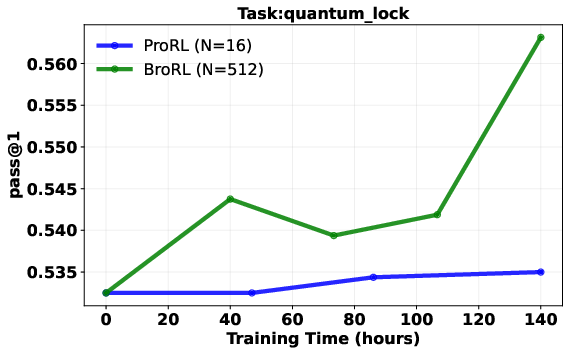
- Real models (actual LLMs)
- They took a strong model that had already trained a long time using a prior method (ProRL) and had stopped improving.
- They continued training it with BroRL (large N, like 512 rollouts per question).
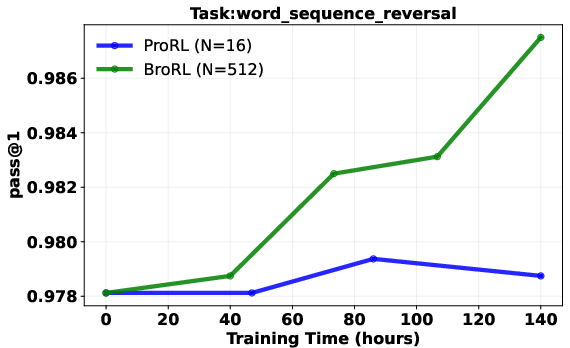
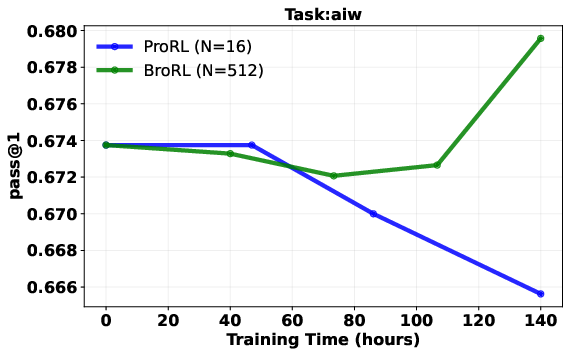
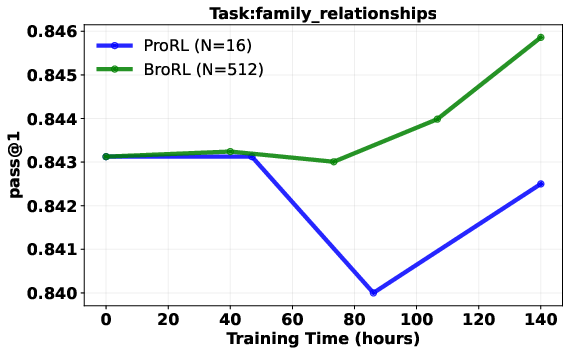
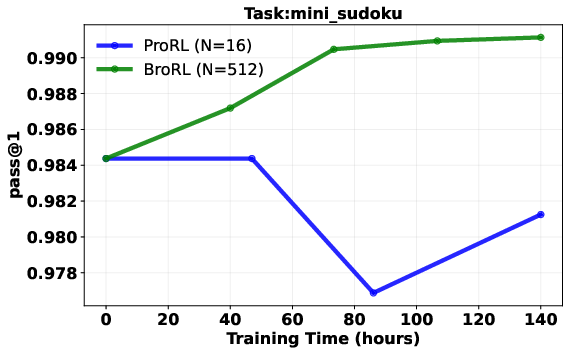
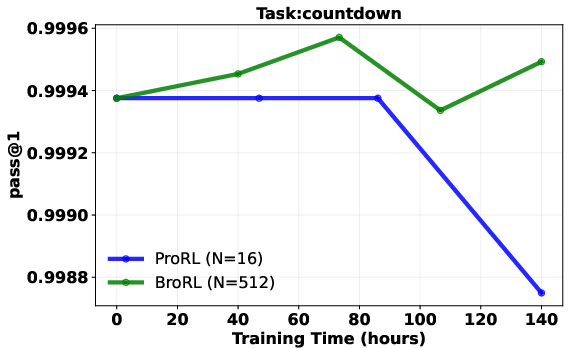
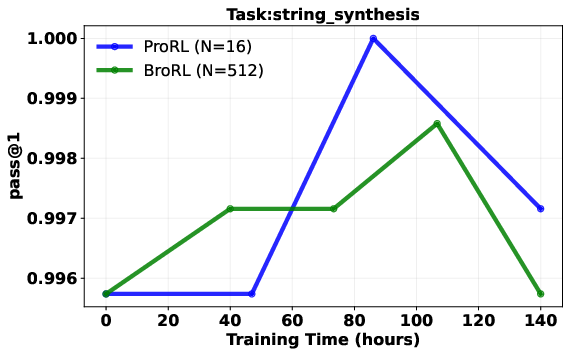
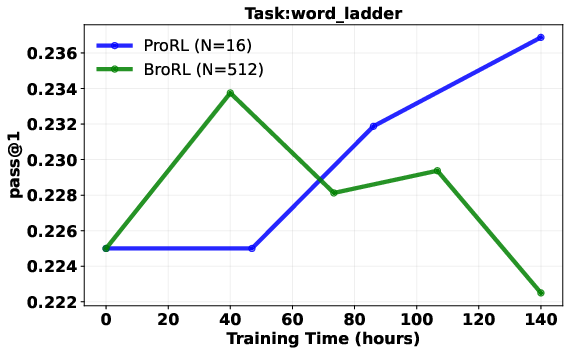
- Result: performance started improving again across math, code, and other reasoning tests—beating the earlier approach.
Main results and why they matter
Here are the most important findings:
- Continuous gains after plateau: Models that stopped improving with step-based scaling (just training longer) started improving again when the number of rollouts per question was increased a lot.
- More reliable updates: With many rollouts, the learning steps are steadier and less “noisy.” The model is less likely to accidentally shift probability away from correct tokens (“knowledge shrinkage”).
- Better real-world efficiency:
- Algorithm-level: Because the model generates many diverse attempts per question, more of them are useful for training (higher “pass rate” after filtering out trivial attempts). That means less waste.
- Hardware-level: Generating many attempts at once uses the GPU more efficiently (it becomes compute-bound rather than memory-bound), roughly doubling throughput in the authors’ setup. In plain terms: it runs faster.
- Stronger test performance: On a wide set of reasoning benchmarks, the 1.5B-parameter model trained with BroRL reached state-of-the-art results for its size, and statistical tests showed the improvements were real and significant.
Why this matters: The field has often tried to improve reasoning by just training longer (more steps). This paper shows another, more effective knob to turn: widen each training step with many more rollouts. That’s a different (and powerful) way to scale RL for reasoning.
What this could change going forward
- Training strategy: Instead of only “more steps,” we should also consider “more tries per question” as a main way to scale reinforcement learning for reasoning.
- Stability and memory: Large-rollout training reduces forgetting and makes learning more dependable, which is crucial for building trustworthy reasoning systems.
- Practical adoption: Because BroRL can be faster on real hardware and use data more efficiently, it’s not just a theory—it’s practical for big training runs.
- Future research: This suggests better exploration (trying many different paths) might be the key to unlocking even stronger reasoning—possibly with smarter ways to select, score, and combine those many rollouts.
In short: BroRL shows that broadening exploration—by trying hundreds of answers per question during training—can push reasoning models past their limits, make learning steadier, and even run faster on today’s hardware.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or left unexplored in the paper. Each point is framed to be concrete and actionable for follow-up research.
- Theoretical development is restricted to a one-step RLVR update with binary, token-level rewards; no extension to multi-step PPO-style training with clipping, KL constraints, advantage normalization, truncated importance sampling, or off-policy corrections used in practice.
- No formal mapping from sequence-level verifiable rewards (trajectory outcomes) to the paper’s token-level “correct/incorrect” sets; the token-level correctness assumption is ungrounded for long chain-of-thought reasoning and needs a principled credit-assignment scheme (e.g., per-step or per-span reward decomposition).
- Absence of finite-sample guarantees: the claim that unsampled second moments vanish with larger N is in expectation only; there are no distribution-dependent bounds, variance/concentration inequalities, or minimal-N conditions that guarantee with high probability.
- Unclear applicability to non-binary or noisy rewards: the analysis assumes and exact verifiability; behavior under partial correctness, ambiguous instructions, reward noise/misspecification, and multi-valued or stepwise rewards is unstudied.
- Lack of treatment for sequence structure and dependencies: the theory assumes independent token sampling and softmax over a static vocabulary, not the autoregressive, context-dependent token distributions of LLMs; effects of prefix dynamics and long-context credit assignment are not analyzed.
- Missing characterization of rollout correlation: with many rollouts from the same prompt, samples can be highly correlated (especially under similar decoding settings), potentially reducing effective exploration; no measurement of gradient variance and correlation vs N, nor strategies to decorrelate rollouts (e.g., diverse decoding or perturbations).
- No compute-optimal trade-off analysis between “width” (rollouts per prompt) and “breadth” (number of distinct prompts per step); large N reduces prompts per step and may harm coverage or generalization; a formal cost model and empirical ablation across prompt/rollout allocations are missing.
- No scaling law for performance vs rollout size N: while suggesting that “hundreds or thousands” help, the paper does not quantify diminishing returns, task-specific optimal N, or guidelines for choosing N under compute constraints; problems where N=512 was insufficient are acknowledged but not systematically explored.
- Confounded empirical setup: multiple factors change simultaneously (context window doubled to 16k, prompts per step reduced, learning rate scaled by , Clip-Higher, dynamic sampling, etc.); ablations isolating the effect of N alone are not provided.
- Limited generality in evaluation: results are shown primarily for a single 1.5B model and a short continuation regime (≤ ~200 steps); no evidence for larger models (e.g., 7B–70B), longer training horizons, or whether BroRL itself eventually plateaus.
- SOTA claims for the 1.5B model lack a comprehensive, up-to-date baseline comparison across “diverse benchmarks”; several cited task families (science, IFEval) are mentioned but not fully reported; detailed leaderboards and reproducible benchmarking are missing.
- No empirical measure of “knowledge shrinkage” on real LLMs: the elimination of worst-case probability drops for “correct tokens” is shown only in a toy simulator; metrics for knowledge retention/forgetting on real tasks (e.g., stability across unrelated benchmarks) are not presented.
- Pass@k implications are theoretical, but empirical results focus almost exclusively on Pass@1; evaluation across multiple k values (e.g., k=5,10,20) to validate the predicted geometric gains is not performed.
- Decoding specifics (temperature, top-p, nucleus sampling, repetition penalties, seed control) are under-specified; their impact on rollout diversity, the unsampled coupling term, and dynamic sampling pass rates with large N is unknown.
- Theoretical object (batch “mood”) and advantage normalization are not reconciled: the analysis uses a simple baseline, whereas practice uses REINFORCE++-style decoupled normalization; no proof that the sign/decomposition results hold under the practical normalization scheme.
- PPO clipping thresholds and KL regularization are used, but the effect of large N on clipping frequency, effective step size, and stability is not analyzed; ablations on Clip-Higher and KL targets vs N are missing.
- Dynamic sampling may bias training by filtering “trivial” trajectories; with large N, pass rate increases, but the bias introduced by filtering on gradient directions and problem difficulty distribution is not assessed.
- Hardware claims are narrow: throughput gains (memory-bound to compute-bound shift) are shown only on NVIDIA H100; no cross-hardware profiling (A100, consumer GPUs), context-length sensitivity analysis, memory footprint/OOM risk, or energy/cost accounting are provided.
- Verification bottleneck is not quantified: RLVR’s reward evaluation (e.g., program execution, equation checking) can dominate runtime as N grows; end-to-end throughput including verifier latency, failure rates, and sandbox overhead (for code) is unreported.
- Potential safety and misuse concerns with large-N exploration (e.g., increased generation of unsafe or policy-violating outputs) are not addressed; no integration or evaluation of safety filters/guardrails during training-time exploration.
- No examination of distribution shift and reward hacking: more exhaustive exploration might find spurious solutions or exploit verifier loopholes; the prevalence of such behaviors as N increases and mitigations (e.g., adversarial verification, anti-cheating checks) are not studied.
- No analysis of how BroRL interacts with instruction following and alignment objectives beyond reasoning tasks; effects on helpfulness/harmlessness (e.g., IFEval or safety benchmarks) are not rigorously evaluated.
- Unclear interaction with off-policy sampling and importance weighting: truncated importance sampling is mentioned but not modeled theoretically; conditions under which positivity of is preserved with off-policy corrections remain open.
- Reproducibility gaps: key appendix proofs are referenced but not present; detailed hyperparameters, training curves, and code release for BroRL-specific components (e.g., verifier configs, sampling settings, system-level pipeline) are needed for independent verification.
Practical Applications
Immediate Applications
The following applications can be deployed today by teams building, training, and operating reasoning-focused LLMs, as well as by organizations that rely on them.
- Software/AI Engineering (LLM Training): Adopt the BroRL recipe to revive plateaued RLHF/RLVR training and improve pass@1 on reasoning tasks.
- Actions: Increase rollout size per prompt to N≈512–1000; keep PPO minibatch count constant; scale learning rate by the square-root of batch increase; enable dynamic sampling; track Q_pos and pass@k.
- Tools/workflows: “BroRL” training config; dynamic sampling; REINFORCE++-style normalization; prefix-cache–friendly large-batch generation; throughput/pass-rate dashboards.
- Assumptions/dependencies: Availability of verifiable rewards (unit tests, compilers, checkers); sufficient GPU memory/compute; stable PPO/GRPO implementations; reliable reward baselines.
- HPC/Cloud Ops: Shift LLM rollout generation from memory-bound to compute-bound regimes to nearly double throughput.
- Actions: Consolidate generation into large-batch inference (e.g., N≥512); optimize prefix caching; co-schedule jobs to maximize arithmetic intensity on GPUs.
- Tools/workflows: Cluster schedulers with N-scaling knobs; caching-aware inference engines (e.g., sglang-like systems); performance telemetry (samples/s, cache hit rates).
- Assumptions/dependencies: Hardware that benefits from large-batch parallelism (e.g., H100s); inference stack supports caching and high throughput; model/context length fit in memory.
- MLOps/Training Analytics: Instrument training to monitor “Exploration Pass Rate” and Q_pos growth for early detection of instability and wasted samples.
- Actions: Track dynamic sampling pass rate, Q_pos, worst-case probability drops among correct tokens, and per-problem pass@1 trajectories.
- Tools/workflows: Exploration monitors; per-benchmark pass@1 tracking at fixed compute; alerting when small-N regimes cause regressions.
- Assumptions/dependencies: Reliable logging/profiling; stable reward attribution; consistent evaluation datasets.
- Academia (RL/LLM Research): Use the mass-balance analysis and token-level simulators to study update dynamics and design more stable RL training for reasoning.
- Actions: Replicate the TRPO-style surrogate experiments; vary rollout sizes to quantify unsampled coupling; benchmark pass@k vs Q_pos improvements.
- Tools/workflows: Token-level simulators; theorem-proving of update signs; ablations on reward baselines and concentration terms (A2, B2, U_pos,2, U_neg,2).
- Assumptions/dependencies: Access to code/data; ability to reproduce PPO-style setups; tasks with verifiable outcomes.
- Education (Math/CS Tutoring): Deploy improved small reasoning models (≈1.5B) fine-tuned with BroRL to deliver more reliable step-by-step solutions in math and coding exercises.
- Actions: Integrate BroRL-trained checkpoints into tutoring apps; evaluate pass@1 and correctness under standardized tasks.
- Tools/products: Lightweight reasoning assistants; curriculum-aligned evaluation harnesses.
- Assumptions/dependencies: Verifiable tasks (answers/test cases); domain-specific guardrails; alignment/safety policies.
- Finance/Enterprise IT: Apply BroRL to domain-specific RLVR where verifiable rewards exist (e.g., code gen with unit tests, policy/compliance rule engines).
- Actions: Build reward pipelines (tests, constraints, rule checkers) and scale N to stabilize updates; measure throughput and pass rate gains.
- Tools/workflows: Automated test generators; compliance validators; exploration-aware schedulers.
- Assumptions/dependencies: High-quality, deterministic verifiers; secure CI/CD integration; governance over model changes.
- Internal Policy/Procurement: Update training guidelines to prefer large-N exploration for efficiency and stability.
- Actions: Set minimum rollout sizes for RLVR; budget for compute consistent with large-batch generation; track model energy-per-sample metrics.
- Tools/workflows: Compute-efficiency scorecards; training SLAs that include pass rate and throughput.
- Assumptions/dependencies: Organizational buy-in; transparent reporting; hardware/software readiness.
- Daily Life (General Assistants): Users benefit from more reliable math/code reasoning in assistants once providers adopt BroRL-trained models.
- Actions: Swap in BroRL-finetuned reasoning backends; expose “verified answer” indicators based on reward checks.
- Tools/products: Assistant integrations; result verification badges.
- Assumptions/dependencies: Provider adoption; latency constraints acceptable; access to verifiers for routine tasks.
Long-Term Applications
These opportunities require further research, domain adaptation, or scaling. They extend BroRL’s broadened exploration paradigm beyond token-level RLVR and into broader sectors.
- Robotics/Autonomy: Adapt BroRL’s broadened exploration to classic RL with verifiable simulators (rewarded by safety/completion metrics) to stabilize learning and reduce catastrophic forgetting.
- Potential products/workflows: Batch rollout generators in simulators; exploration-width schedulers; safety-verified policy updates.
- Assumptions/dependencies: Fast simulators; reliable task-verification signals; algorithmic extensions beyond token-level updates; sim-to-real transfer strategies.
- Safety/Alignment Preservation: Use large-N exploration to minimize knowledge shrinkage during RL fine-tuning, preserving previously acquired capabilities.
- Potential tools: “Capability Preservation” monitors tracking worst-case probability drops; curriculum-based rollout scaling.
- Assumptions/dependencies: High-fidelity reward models; robust evaluation suites detecting regressions; policies for safe deployment.
- Healthcare (Clinical Reasoning): Train domain LLMs with verifiable clinical rewards (guideline adherence, dose calculations, structured checklists) using BroRL for stable updates and improved reliability.
- Potential products: Clinical decision support with verified reasoning chains; audit logs linking decisions to verifiers.
- Assumptions/dependencies: Regulated data access; validated medical verifiers; stringent safety and privacy controls; regulatory clearance.
- Energy/Compute Policy: Establish organizational and industry standards that incentivize algorithmic efficiency (e.g., report dynamic sampling pass rate and compute-bound utilization).
- Potential tools/workflows: Efficiency benchmarks; carbon-per-sample metrics; procurement policies favoring efficiency-aware training.
- Assumptions/dependencies: Consensus on metrics; collaboration across vendors; independent audits.
- Training Platforms and Services: Build “BroRL Trainer” and “Adaptive N Scheduler” as turnkey services/plugins for RLHF/RLVR stacks (veRL, OpenRLHF).
- Potential products: Exploration-Budget Optimizer; Q_pos and pass@k monitors; Dynamic Sampling Service; Prefix Cache Optimizer.
- Assumptions/dependencies: Broad compatibility across frameworks; managed infrastructure for large-batch inference; enterprise integrations.
- Education (STEM Discovery/Theorem Proving): Scale exploration-driven RL for formal proof assistants and hard problem-solving (e.g., theorem synthesis with verifiable checkers).
- Potential workflows: Broad search with verification loops; adaptive N for problem difficulty; curriculum learning with verifiers.
- Assumptions/dependencies: Formal proof verifiers; curated datasets; compute budgets for breadth-first exploration.
- Benchmarking/Governance: Establish RL scaling laws along the “width” axis (rollout size N) and standardize new metrics (mass balance terms, Q_pos trajectories).
- Potential tools: Open benchmark suites capturing width-scaling behavior; shared methodologies for batch mood (S_R) analysis.
- Assumptions/dependencies: Community collaboration; reproducible pipelines; transparent reporting.
- Inference-Time Reliability: Use breadth at test time—sample many candidate chains-of-thought, verify, and select—to improve answer reliability in high-stakes settings.
- Potential products/workflows: “Verify-then-Select” inference; adaptive N based on difficulty/uncertainty; cost-aware verification policies.
- Assumptions/dependencies: Fast verifiers; acceptable latency/cost trade-offs; robust selection policies that avoid biasing toward spurious solutions.
Glossary
- AdamW: An optimizer that decouples weight decay from the gradient-based update for improved training stability. "and update with AdamW (learning rate ) for steps."
- Advantage: In policy-gradient RL, the relative value of an action compared to a baseline (e.g., a value function or mean return). "where is the probability ratio and is the advantage."
- Advantage normalization (decoupled): A technique that normalizes advantages separately from other statistics to stabilize training. "A key feature is its REINFORCE++-style decoupled advantage normalization \citep{Hu2025REINFORCEpp}."
- Arithmetic intensity: Ratio of compute operations to memory operations; higher values typically improve GPU utilization. "increasing arithmetic intensity and leading to higher sustained computing utilization."
- Baseline (batch baseline): A batch-level average reward used to reduce variance in policy gradient estimates. "center rewards with the batch baseline "
- BroRL: A scaling strategy that increases the number of rollouts per prompt to broaden exploration in RLVR. "BroRL is predicated on the principled scaling of the rollout size per prompt "
- Clip‑Higher: An asymmetric PPO clipping setting with a larger upper clip bound to encourage exploration. "exploration enhancements via ClipâHigher ()"
- Compute-bound: A regime where performance is limited by compute throughput rather than memory bandwidth. "shift generation from memory-bound to compute-bound at the hardware level"
- Dynamic Sampling: An algorithmic filter that removes trivial all-correct or all-incorrect trajectories to focus on informative samples. "Dynamic Sampling \citep{Yu2025DAPO}, which filters out trivial trajectories that are either entirely correct or entirely incorrect"
- GRPO: An RLHF-style algorithm variant used for training reasoning models. "has popularized algorithms such as GRPO \citep{Shao2024DeepSeekMath}, RLOO \citep{Ahmadian2024RevisitingREINFORCE}, REINFORCE++ \citep{Hu2025REINFORCEpp} and DAPO \citep{Yu2025DAPO}."
- i.i.d.: Independent and identically distributed; a common sampling assumption in analysis. "When drawing i.i.d.\ samples, the per-task success probability for input is"
- Importance sampling (truncated): A correction method for distribution mismatch that caps weights to reduce variance. "and truncated importance sampling \citep{yao2025offpolicy} to correct off-policy mismatch between the inference engine and the training engine."
- Knowledge shrinkage: The unintended reduction in probability assigned to correct tokens during training. "guarantees an increase in the probability mass of all correct tokens and eliminates knowledge shrinkage \citep{Wu2025TheIL}"
- Learning rate scaling: Adjusting the learning rate based on batch size to maintain stable update magnitudes. "Specifically, the learning rate was scaled proportionally to the square root of the increase in the batch size"
- Logit: The unnormalized score for a class before softmax; analysis is sometimes done directly in logit space. "Our analysis is performed in the logit domain,"
- Mass balance equation analysis: A token-mass accounting approach to characterize how probability mass shifts between correct and incorrect tokens under RL updates. "motivated by a mass balance equation analysis"
- Memory-bound: A regime where performance is limited by memory bandwidth rather than compute throughput. "With small batches (), the generation process is often memory-bound;"
- Off-policy mismatch: Discrepancy between the data-generating policy and the training policy that requires correction. "to correct off-policy mismatch between the inference engine and the training engine."
- Pass@1: The probability of solving a task with a single sample; commonly used to evaluate reasoning performance. "Pass@1 comparison of BroRL vs. ProRL, normalized by training compute."
- Pass@k: The probability of solving a task using up to k independent samples. "When drawing i.i.d.\ samples, the per-task success probability for input is"
- PPO (Proximal Policy Optimization): A policy-gradient algorithm that uses clipped probability ratios to stabilize updates. "We adopt the prolonged reinforcement learning (RL) framework from ProRLv2 \citep{HuEtAl2025_ProRLv2}. This approach is centered around a clipped Proximal Policy Optimization (PPO) algorithm,"
- Prefix cache hit rate: The proportion of generation steps that reuse cached key-value states for faster decoding. "and also leads to a higher prefix cache hit rate \citep{zheng2024sglang}."
- Probability ratio: In PPO, the ratio of the new policy probability to the old policy probability for a trajectory. "where is the probability ratio and is the advantage."
- ProRL: A training regime that scales RL by increasing the number of training steps for prolonged optimization. "Recent work ProRL \citep{liu2025prorl} has demonstrated the potential of scaling RL by increasing the number of training steps."
- REINFORCE++: An RLHF variant emphasizing robust, decoupled advantage normalization. "A key feature is its REINFORCE++-style decoupled advantage normalization \citep{Hu2025REINFORCEpp}."
- RLHF (Reinforcement Learning from Human Feedback): A family of methods aligning models to human preferences using RL. "The RLVR paradigm, which adapts RLHF techniques \citep{christiano2017deep, ouyang2022training},"
- RLVR (Reinforcement Learning with Verifiable Rewards): An RL framework where rewards are deterministically checked (e.g., by verifiers) for reasoning tasks. "Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a key ingredient for unlocking complex reasoning capabilities in LLMs."
- RLOO: A REINFORCE-style optimization method that uses leave-one-out baselines for variance reduction. "has popularized algorithms such as GRPO \citep{Shao2024DeepSeekMath}, RLOO \citep{Ahmadian2024RevisitingREINFORCE}, REINFORCE++ \citep{Hu2025REINFORCEpp} and DAPO \citep{Yu2025DAPO}."
- Rollout size : The number of sampled completions per prompt used in each RL update. "rollout size , the number of rollouts () sampled per prompt in each update step."
- Surrogate objective: An approximate objective optimized in place of the true objective (e.g., TRPO/PPO surrogates). "using a TRPO-style linear surrogate objective \citep{schulman2015trust, zhu2025surprisingeffectivenessnegativereinforcement}."
- TRPO (Trust Region Policy Optimization): A policy-gradient method that constrains policy updates within a trust region for stability. "We build a token-level simulator reflecting the per-token update analysis in Theorem~\ref{thm:sign}, using a TRPO-style linear surrogate objective"
- Unsampled coupling term: A component of the update attributable to tokens not sampled in the batch that can hinder learning if dominant. "the ``unsampled coupling'' term, $S_R \big( Q_{\mathrm{pos} U_{\mathrm{neg},2} - Q_{\mathrm{neg} U_{\mathrm{pos},2} \big)$, which can introduce instability and counteract policy improvement."
- veRL framework: A system/framework used to run large-scale RL training for LLMs. "with 64 NVIDIA H100 GPUs and the veRL famework \citep{sheng2025hybridflow}."
Collections
Sign up for free to add this paper to one or more collections.