- The paper introduces SGAligner++ as a novel framework that leverages multimodal data (point clouds, CAD models, text captions, and spatial referrals) to enhance 3D scene graph alignment.
- It employs lightweight unimodal encoders and attention-based fusion techniques to create a unified embedding space, improving node matching accuracy even in noisy, low-overlap conditions.
- Extensive evaluations show SGAligner++ outperforms state-of-the-art methods in both accuracy and computational efficiency, making it suitable for real-time robotics and mixed reality applications.
SGAligner++: Cross-Modal Language-Aided 3D Scene Graph Alignment
Introduction
The convergence of multiple sensory modalities for 3D scene understanding is crucial for applications in robotics, mixed reality, and computer vision. The paper "SGAligner++: Cross-Modal Language-Aided 3D Scene Graph Alignment" introduces SGAligner++, a framework designed to perform 3D scene graph alignment by leveraging a multimodal approach that incorporates point clouds, CAD meshes, text captions, and spatial referrals. This work addresses limitations observed in previous methodologies that were heavily reliant on single-modal data and struggled with noisy or incomplete inputs.

Figure 1: SGAligner++. We address the problem of aligning 3D scene graphs across different modalities, namely, point clouds, CAD meshes, text captions, and spatial referrals, using a joint embedding space. Our approach creates a unified 3D scene graph, ensuring that spatial relationships are accurately preserved. It enables robust 3D scene understanding for visual localization and robot navigation.
Unified Multimodal Representation
SGAligner++ innovatively fuses different types of scene data into a unified representation by using lightweight unimodal encoders coupled with attention-based fusion techniques. Each modality—point clouds, CAD models, textual representations, and spatial context—is encoded through specialized neural methods, contributing to a shared embedding space. This shared representation facilitates the alignment of overlapping 3D scene graphs even when there's sensor noise or partial observations, which is a common challenge in real-world applications.
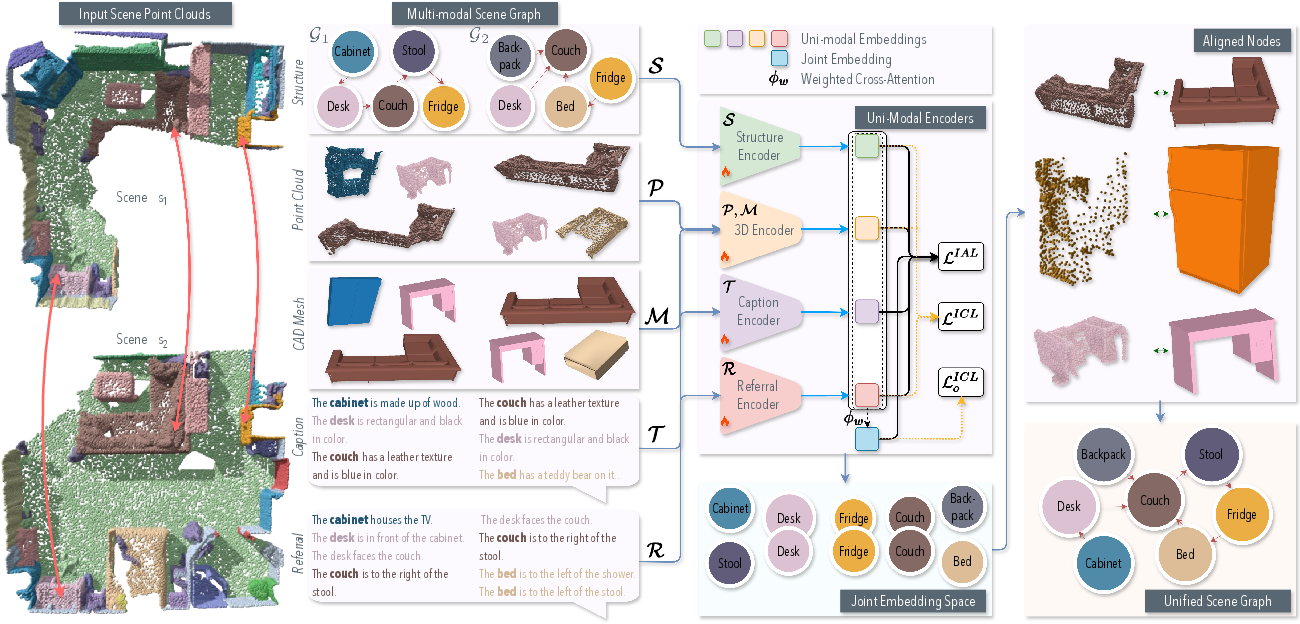
Figure 2: Overview of SGAligner++. Our method takes as input: (a) two scene point clouds with spatially overlapping objects, and (b) their corresponding 3D scene graphs with multi-modal information--point clouds, CAD meshes, text captions, and spatial referrals. (c) We process the data via separate uni-modal encoders and optimize them together in a joint embedding space using trainable attention. (d) Similar nodes are aligned together in the common space and we finally output a unified 3D scene graph, which preserves spatial-semantic consistency and enables multiple downstream tasks.
Node Matching and Cross-Modal Alignment
The paper demonstrates that SGAligner++ substantially surpasses prior methods such as SGAligner and SG-PGM in terms of node matching and overall alignment accuracy. Notably, SGAligner++ adapts well to low-overlap conditions, showing resilience where other methods falter, particularly with predicted noisy data. This robust performance stems from the system’s ability to integrate and reason over multiple data modalities, achieving enhanced semantic consistency.
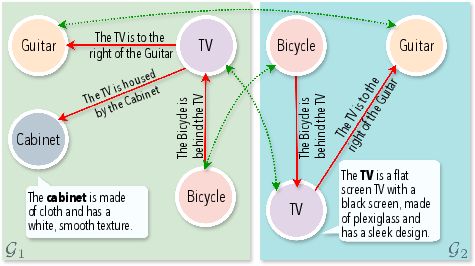
Figure 3: Example of context-aware LLM-generated scene graphs. Overlapping pairs are in green and non-overlapping are in red.
Extensive evaluations on both ScanNet and 3RScan datasets revealed that SGAligner++ achieves remarkable improvements in node matching metrics, outperforming state-of-the-art methods by significant margins, particularly in cases involving predicted data with inherent noise and imbalance. The success of SGAligner++ highlights the effectiveness of using a cross-modal embedding space fused through a multi-task learning framework to handle the inherent complexity of real-world inputs.
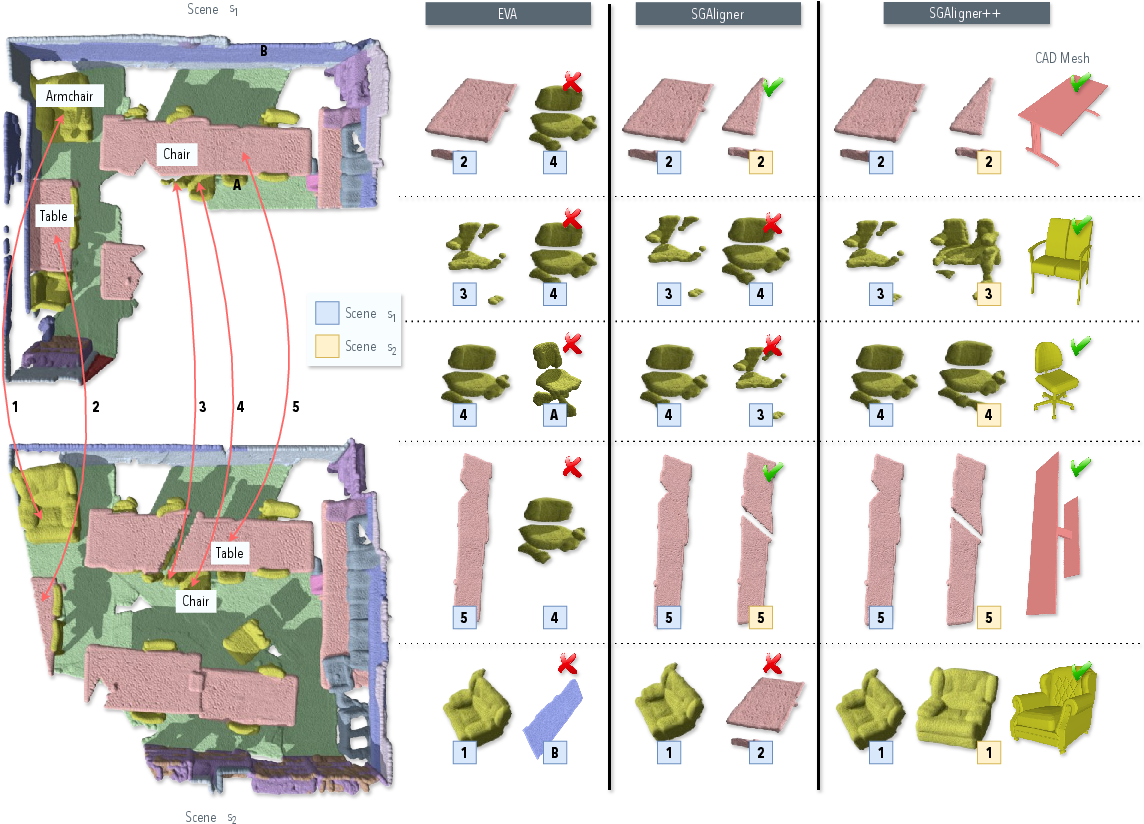
Figure 4: Qualitative Results on Node Matching. Given two partially overlapping observations of the same scene, EVA is unable to identify any correct matches, aligning objects within the same scene and SGAligner cannot handle intra-class instances (e.g. two chairs). In contrast, SGAligner++ correctly identifies all point cloud matches, as well as CAD ones. Numbers indicate common objects across the two overlapping scenes.
Computational Efficiency
While outperforming existing methods in alignment accuracy, SGAligner++ is also efficient regarding computational resources. Its runtime complexity is significantly lower than graph matching baselines like SG-PGM, making it a practical choice for deployment in real-time robotics applications. The framework’s scalability ensures that it can be extended to include additional modalities such as surface normals or additional semantic data without substantial increases in computational demand.
Conclusion
SGAligner++ introduces a compelling solution for aligning 3D scene graphs across diverse modalities. By leveraging a comprehensive multimodal embedding strategy that includes geometric, textual, and spatial information, it addresses key challenges in 3D scene graph alignment, such as handling sensor noise and data sparsity. The framework's clear advantages in scalability, multimodal integration, and precision in alignment position it as a powerful tool for future developments in robotic navigation, semantics-based scene understanding, and mixed reality applications.
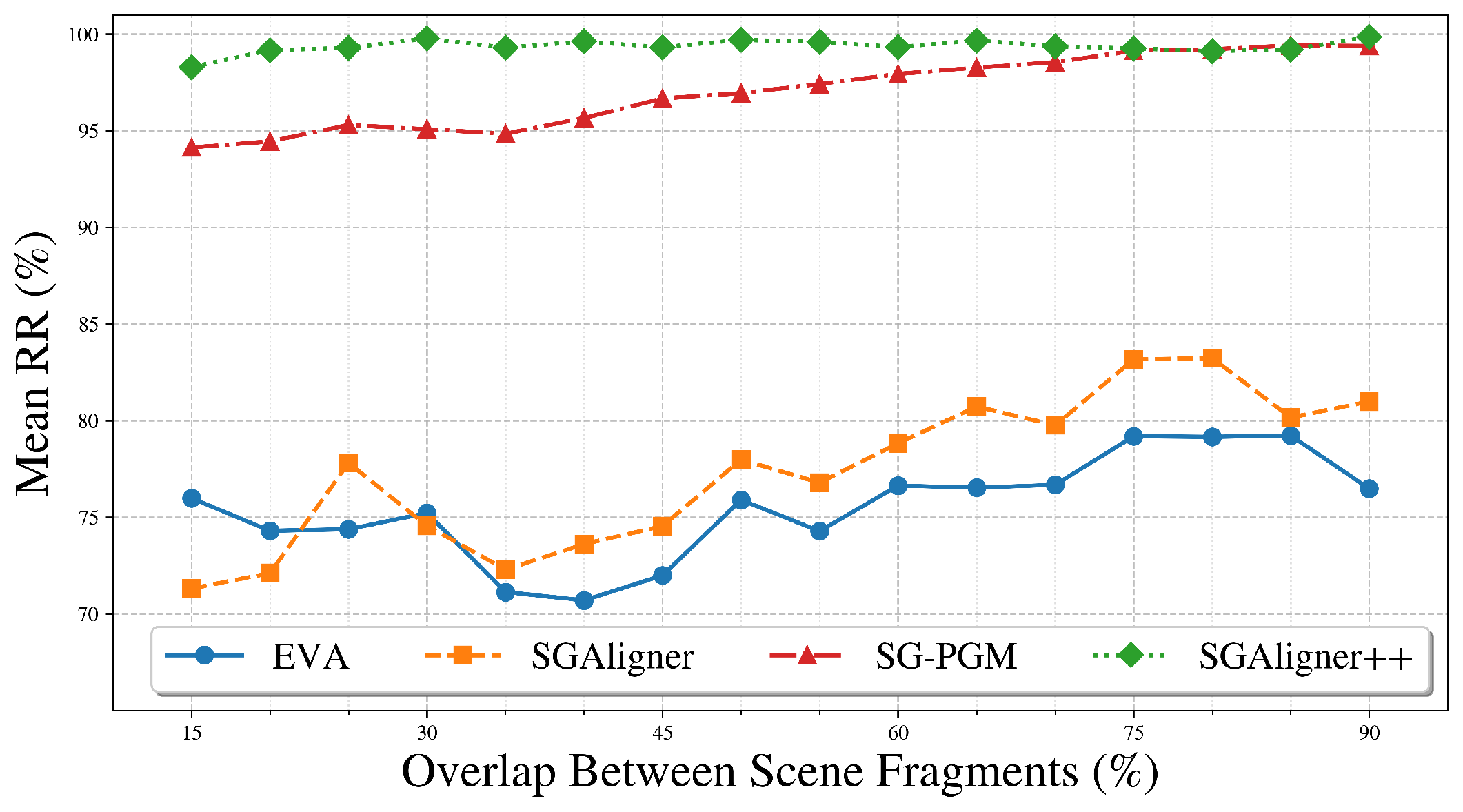
Figure 5: Node Matching Mean RR vs. Overlap Range, on 3RScan. SGAligner++ generalizes across overlap thresholds and performs robustly even in low-overlap cases.