SegMASt3R: Geometry Grounded Segment Matching
Abstract: Segment matching is an important intermediate task in computer vision that establishes correspondences between semantically or geometrically coherent regions across images. Unlike keypoint matching, which focuses on localized features, segment matching captures structured regions, offering greater robustness to occlusions, lighting variations, and viewpoint changes. In this paper, we leverage the spatial understanding of 3D foundation models to tackle wide-baseline segment matching, a challenging setting involving extreme viewpoint shifts. We propose an architecture that uses the inductive bias of these 3D foundation models to match segments across image pairs with up to 180 degree view-point change. Extensive experiments show that our approach outperforms state-of-the-art methods, including the SAM2 video propagator and local feature matching methods, by upto 30% on the AUPRC metric, on ScanNet++ and Replica datasets. We further demonstrate benefits of the proposed model on relevant downstream tasks, including 3D instance segmentation and image-goal navigation. Project Page: https://segmast3r.github.io/




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about “segment matching,” which means finding which parts of one picture match the same parts in another picture. A “segment” is just a meaningful region in an image—like a door, a wall, a chair, or a specific object.
The authors introduce a method called SegMASt3R. It uses a powerful 3D vision model to match segments between two photos taken from very different viewpoints—even up to a 180° rotation. This is hard because the same object can look very different from another angle. The paper shows that SegMASt3R is more accurate than other methods and helps with tasks like building 3D maps of objects and guiding a robot toward goals.
Key Objectives
This paper tries to answer three simple questions:
- How can we reliably match the same objects or regions across two images when the camera views are very different?
- Can we use a model that “understands” 3D geometry to do better than models that only focus on 2D appearance?
- Will improved segment matching help real tasks like making 3D maps of objects and robot navigation?
Methods in Everyday Language
Think of each image as a map of regions (segments). The main challenge is recognizing the same region in another image, even if the camera has moved a lot or rotated.
Here’s how SegMASt3R works:
- Start with a 3D-aware model: The system uses a “3D foundation model” called MASt3R. Unlike regular image models that mostly look at colors and textures, MASt3R learns from 3D data, so it understands shape, depth, and how views change when the camera moves. This 3D sense helps it recognize the same object from different angles.
- Build segment features: The model first breaks images into small patches and creates features (like fingerprints) for each patch. A small added “segment-feature head” then collects the features from all patches inside each segment’s mask (the mask marks which pixels belong to that segment). This creates one compact descriptor per segment—like a single ID tag per object.
- Match segments between images: To pair segments from Image A to Image B, the method compares their descriptors. It uses:
- A similarity score (cosine similarity): Higher score means two segments are likely the same.
- A “dustbin”: A special “no match” option for segments that don’t exist in the other image (for example, if a chair is visible in one image but hidden in the other).
- Sinkhorn algorithm: A process that turns all those similarity scores into a clean set of matches where each segment picks at most one counterpart. You can think of it like assigning dance partners, with a rule that everyone gets at most one partner, and some can choose “no partner.”
- Training the matcher: The system is trained with examples of which segments are supposed to match (and which are not). It learns to give high scores to correct matches and low scores to wrong ones. This is similar to how the popular “SuperGlue” matcher is trained.
- Data used: The model is trained and tested on indoor scene datasets (ScanNet++ and Replica), and also checked on a challenging outdoor dataset (MapFree) to see how well it generalizes.
Main Findings and Why They Matter
What did they discover?
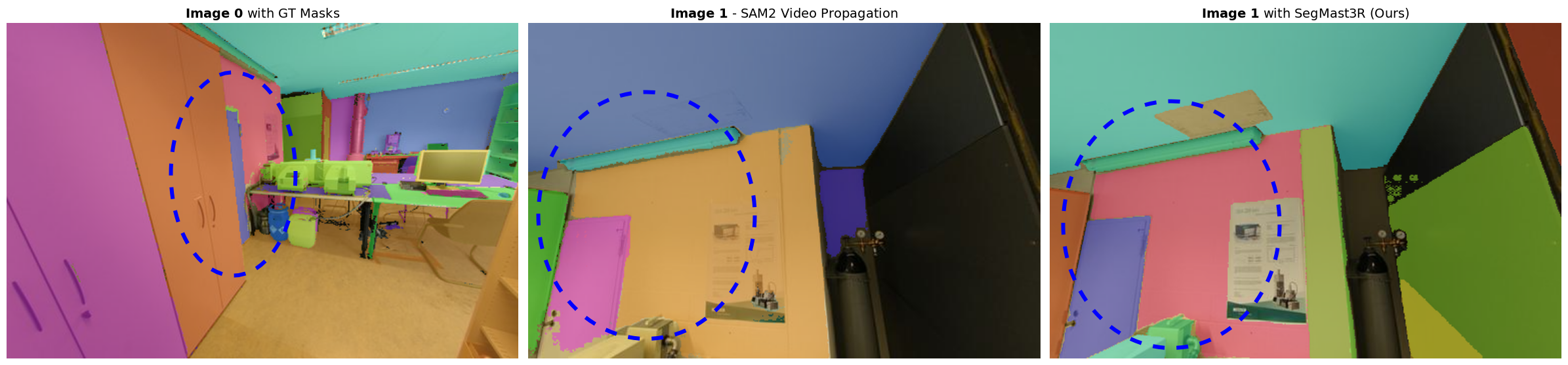
- Much better accuracy under extreme viewpoint changes: On ScanNet++ and Replica, SegMASt3R beat strong baselines (including SAM2 and several local feature matchers) by large margins. In some cases, it improved a key measure (AUPRC) by up to around 30%. This means it found correct matches more consistently and avoided false matches better.
- Robust to rotation and lighting changes: Because it uses a 3D-aware backbone, it can handle big rotations (up to 180°), different lighting, and partial occlusions.
- Works with imperfect segmentations: Even when the input masks are noisy (not perfect), SegMASt3R still performs well. Its geometric understanding helps it ignore misleading visual patterns.
- Helps real tasks:
- 3D instance mapping: It maps object instances (not just classes) in 3D more accurately than previous methods. That means it’s better at telling “this chair” from “that chair” and keeping identities straight over time.
- Robot navigation: When used inside a navigation system, it led to higher success rates, especially when the “map” images were sparse or widely spaced. That’s important for fast, efficient navigation.
Why is this important?
- Segment-level understanding is more interpretable than single points. It matches meaningful parts of a scene, which helps downstream reasoning.
- It reduces “perceptual aliasing” (mixing up different objects that look similar), which is a common problem in robotics and long-term tracking.
- It brings 3D awareness into matching—a big step beyond 2D-only methods.
Implications and Impact
This research suggests that using 3D-aware models for segment matching can greatly improve performance in difficult situations. Potential impacts include:
- More reliable video object tracking, even over long times and changing viewpoints.
- Better scene understanding and 3D maps, which can help robots manipulate and navigate around specific objects.
- Stronger foundations for AR/VR, visual search, and autonomous systems, thanks to fewer false matches and better generalization.
- Practical benefits: Robots and applications can use sparser, lighter maps and still navigate accurately, saving compute and memory.
In simple terms: SegMASt3R makes it easier for computers and robots to recognize the same things across different pictures, even when those pictures are taken from very different places or angles. That opens the door to smarter, more robust vision systems in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete directions that future research could address:
- Domain generalization: The method degrades notably on outdoor MapFree and requires either retraining or manual dustbin calibration. How can we develop principled, training-free adaptation (e.g., per-pair confidence calibration, test-time adaptation, or self-supervised domain alignment) to handle unseen domains and conditions?
- Reliance on segmentation quality: Training and most evaluations assume accurate instance masks; noisy-mask evaluation explicitly avoids penalizing AMG errors. What is the true end-to-end performance with realistic AMGs, and can we jointly train or adapt the segmenter and matcher to be robust to over/under-segmentation and mask noise?
- Fixed segment budget (M=100): The pipeline fixes the number of segments and aggregates features accordingly. How does performance scale with variable and potentially large numbers of segments per image, and can we design adaptive budget allocation (e.g., dynamic M, top-k segment selection, or complexity-aware pruning)?
- One-to-one vs many-to-one associations: Discretization uses row-wise argmax after Sinkhorn, which can break bijectivity and cannot handle over-/under-segmentation (one-to-many or many-to-one) explicitly. Can we incorporate global one-to-one constraints or explicit merge/split reasoning (e.g., hierarchical or set-to-set matching)?
- Underuse of explicit 3D cues: Although the backbone is a 3D FM, the segment features are 2D masked averages of upsampled patches. Would explicitly leveraging predicted depth/point maps, visibility reasoning, or pose-conditioned geometric consistency (e.g., 3D overlap priors during training/inference) reduce false matches?
- Segment feature aggregation design: The current MLP upsampling plus masked averaging (24-dim) is simplistic. What is the impact of feature dimensionality, attention-based masked pooling, multi-scale feature fusion, or geometry-aware pooling (e.g., visibility-weighted aggregation) on small/large/thin segments?
- Hyperparameter and calibration sensitivity: The temperature τ, number of Sinkhorn iterations T, and dustbin logit α are not systematically analyzed; α needed domain-specific recalibration. How sensitive is performance to these parameters, and can we learn or auto-calibrate them per image pair (e.g., via uncertainty estimation or meta-learning)?
- Backbone freezing: The MASt3R backbone is frozen; only the segment-feature head and matcher are trained. Does partial or full fine-tuning of cross-view decoders or deeper layers significantly improve performance, and what are the compute-memory trade-offs?
- Supervision noise and construction: Ground-truth matches rely on dataset poses and 3D annotations; details of occlusion handling, partial visibility, and label noise are deferred to supplementary. How robust is training to pose/mesh noise, and can weaker supervision (e.g., cycle consistency across triplets) replace 3D labels?
- Pairwise-only training and inference: Matching is performed on pairs; multi-view/global consistency (e.g., cycle consistency, graph optimization) is not enforced. Can multi-view training objectives and global association over sequences further reduce drift and identity switches?
- Efficiency and scalability: Inference is ~0.58 s/pair on an A6000 and matching is O(M2). How does the method scale to high segment counts and real-time robotics on edge hardware, and can we adopt sparse OT, candidate pruning, or approximate matching to reduce cost?
- Unmatched detection evaluation: While AUPRC summarizes performance, the paper lacks explicit metrics analyzing unmatched detection quality (e.g., dustbin precision/recall, FPR@fixed-TPR). How well calibrated are non-match probabilities, especially under domain shift?
- Symmetry and aliasing at scale: The approach shows qualitative robustness to perceptual aliasing (e.g., symmetric structures), but there is no controlled, quantitative benchmark isolating symmetry-induced errors. Can we design datasets and metrics that directly measure aliasing robustness?
- Dynamics and non-rigid objects: Training and evaluations are primarily in static indoor scenes. How does the method handle deformable or moving objects, significant occlusion dynamics, and time-varying geometry?
- Segmentation granularity and hierarchy: The method is instance-centric and single-granularity. Can we extend to hierarchical segment graphs (parts↔instances↔stuff), and support matching across granularities and merges/splits over time?
- Cross-modality robustness: The approach is RGB-only. Can we exploit depth, event, thermal, or multi-spectral inputs, potentially via 3D FM priors, to further stabilize matching in challenging conditions (night, glare, motion blur)?
- Integration of geometry checks at match time: 3D geometric filtering (e.g., point-cloud IoU) is used in downstream mapping but not in the core match inference. Would incorporating fast geometric sanity checks into the matcher (or training loss) reduce false positives without large overhead?
- Navigation evaluation scope: Navigation gains are shown on a single benchmark with limited ablations. How do results vary across environments, seeds, controllers, and resource budgets, and what are the real-time constraints and FPS on representative robot hardware?
- Per-category and condition-stratified analysis: The paper lacks detailed breakdowns (e.g., by segment size, class, occlusion level, pose-bin interactions). Such analyses could reveal specific failure modes and guide targeted improvements.
- Reproducibility gaps: Key procedures (e.g., GT match generation details, LFM vote-based matching algorithm specifics) are relegated to supplementary. Clearer, code-level documentation and standardized evaluation protocols would improve comparability and replication.
Practical Applications
Immediate Applications
Below is a concise set of actionable use cases that can be deployed now, leveraging the paper’s methods and findings. Each item includes sector mapping and feasibility notes.
- Robotics: object-relative navigation and localization
- Sector: robotics, autonomy
- Application: Drop-in replacement of DINOv2-based association in object-topological navigation planners (e.g., RoboHop) to improve SPL/SSPL under sparse submaps and wide-baseline views; integrate as a ROS node that consumes per-frame instance masks and produces segment correspondences via the Sinkhorn layer with a learnable dustbin.
- Tools/workflow: SegMASt3R inference module + AMG (SAM2/FastSAM) + dustbin α calibration for target domain; optional 3D check via point-cloud IoU filtering.
- Assumptions/dependencies: Requires upstream segmentation masks; best performance indoors; simple α calibration (grid-search) recommended for domain shift (e.g., outdoor scenes); GPU recommended for near-real-time (≈0.6 s per pair reported).
- 3D instance mapping for SLAM and digital twins
- Sector: robotics, AEC (architecture/engineering/construction), facilities management
- Application: Use segment matching to maintain instance identities across trajectories; back-project matched segments for per-instance 3D localization and long-term tracking in indoor maps.
- Tools/workflow: SegMASt3R + RGB-D streams + camera poses; geometric filtering of correspondences (point-cloud IoU threshold ≥0.5).
- Assumptions/dependencies: Requires depth/poses for 3D consistency checks; segmentation quality impacts mapping fidelity; indoor scenes are best supported out-of-the-box.
- Video post-production and VFX object tracking under extreme viewpoint changes
- Sector: media/software
- Application: Robust mask-level tracking across cuts or large camera motions where keypoint trackers fail; apply effects/edits to specific instances even after occlusions or rotations.
- Tools/workflow: Integrate SegMASt3R with SAM2 for mask generation and post-process correspondences to carry effect parameters; use dustbin to avoid false matches when objects exit view.
- Assumptions/dependencies: Requires reasonable mask quality; domain calibration may be needed for complex outdoor scenes.
- Multi-camera object association in indoor analytics without facial biometrics
- Sector: retail, security, smart buildings; policy-friendly analytics
- Application: Associate object instances (e.g., carts, packages) across cameras with differing viewpoints to enable occupancy, flow, and inventory analytics while minimizing personal data usage.
- Tools/workflow: SegMASt3R + per-camera AMG + temporal stitching of segment IDs via Sinkhorn correspondences; dustbin rejects unmatched objects across views.
- Assumptions/dependencies: Camera placement may induce extreme baselines; ensure mask segmenters perform adequately; adopt privacy-by-design policies (avoid re-identifying individuals).
- AR object persistence and labeling in indoor environments
- Sector: AR/VR, consumer apps
- Application: Persist labels on appliances/furniture across user movement and wide viewpoint changes; reduce drift when re-entering rooms.
- Tools/workflow: Mobile AMG + SegMASt3R to re-link current view segments to previously labeled segments; lightweight on-device α calibration with a small calibration set.
- Assumptions/dependencies: Mobile compute constraints; segmentation model inference on-device; currently stronger indoors.
- Asset inventory and change tracking in facilities
- Sector: enterprise, AEC, logistics
- Application: Periodically capture rooms from different vantage points and match segments to log additions, removals, or relocations of assets; flag unmatched segments via dustbin as potential change events.
- Tools/workflow: Photo capture workflow + batch SegMASt3R matching + IoU-based change validation; dashboard for asset deltas.
- Assumptions/dependencies: Requires a baseline inventory and consistent mask generation; lighting and occlusions handled better than keypoints, but calibration improves robustness outdoors.
- Academic benchmarking for wide-baseline segment matching
- Sector: academia
- Application: Use the paper’s evaluation recipe (AUPRC, R@k across pose bins) on ScanNet++ and Replica for fair comparisons; adopt the differentiable Sinkhorn layer with a learnable dustbin to enable end-to-end training.
- Tools/workflow: SegMASt3R codebase + standardized pose bins + EarthMatch for local-feature baselines; reproducible training settings (AdamW, cosine LR).
- Assumptions/dependencies: Availability of datasets with instance masks; consistent mask downsampling/aggregation to segment descriptors.
- Quality assurance for segmentation pipelines
- Sector: software QA, MLOps
- Application: Use segment matching consistency across views as a proxy metric to detect drift or regression in upstream segmenters (AMGs), highlighting unstable masks in production.
- Tools/workflow: Periodic cross-view matching; track dustbin rates and AUPRC trends; alert on anomalies.
- Assumptions/dependencies: Requires access to view pairs and baseline statistics; domain shifts must be accounted for.
Long-Term Applications
The following use cases likely require further research, domain scaling, or additional integration to become production-ready.
- Outdoor autonomy: cross-view segment matching for ADAS and mobile robotics
- Sector: automotive, robotics
- Application: Associate road furniture, signage, and dynamic objects across drastically different viewpoints and sensors (dashcams, roadside cameras) to improve localization and scene understanding.
- Tools/workflow: Multi-sensor AMG + SegMASt3R retrained or adapted on outdoor datasets; robust α calibration; safety monitoring for false positives.
- Assumptions/dependencies: Significant domain shift from indoor training; strong weather/lighting variation; real-time constraints and safety certification.
- Cross-modal segment matching (RGB–Depth–LiDAR fusion)
- Sector: robotics, AR/VR, industrial inspection
- Application: Fuse geometric priors with LiDAR/depth to match segments across modalities and viewpoints, improving reliability on texture-poor or repetitive scenes.
- Tools/workflow: Extend segment-feature head to multi-modal descriptors; train with 2D+3D supervision; OT matching across modalities.
- Assumptions/dependencies: Synchronized multi-modal data; new training pipelines and datasets.
- Instance-level scene graphs for embodied AI
- Sector: robotics, AI research
- Application: Build persistent, instance-centric scene graphs with reliable cross-view association, enabling planning, manipulation, and object-focused policies.
- Tools/workflow: SegMASt3R-driven association + graph construction + task-level policies; integration with planners and memory architectures.
- Assumptions/dependencies: Stable upstream segmentation; long-horizon data association; handling of object state changes.
- Per-instance NeRFs and asset libraries from casual capture
- Sector: media, AEC, ecommerce
- Application: Automatically cluster per-instance segments across captures to build instance-specific 3D radiance fields or meshes for catalogs and digital twins.
- Tools/workflow: SegMASt3R + NeRF/mesh reconstruction per matched instance; asset management pipeline.
- Assumptions/dependencies: Requires sufficient multi-view coverage and good masks; scale-out storage/compute.
- Privacy-preserving multi-camera analytics standards
- Sector: policy, compliance
- Application: Develop guidelines and tooling that use geometry-grounded segment association (objects, not people) to enable useful analytics while limiting personal data processing; codify dustbin rejection as a safety layer to avoid forced matches.
- Tools/workflow: Policy frameworks + SDKs that anonymize human segments and prefer object-centric analytics; audits on false match rates.
- Assumptions/dependencies: Stakeholder buy-in; careful risk analysis on re-identification potential in edge cases.
- Education: curricula and benchmarks for geometry-grounded perception
- Sector: education, academia
- Application: Courses and labs showcasing the difference between 2D-only and geometry-aware models on wide-baseline association; open benchmarks emphasizing AUPRC under pose bins.
- Tools/workflow: Teaching kits with code, datasets, and evaluation scripts; challenge leaderboards.
- Assumptions/dependencies: Sustainable dataset licensing and compute access for students.
- Industrial inspection across revisits (plants, wind turbines, bridges)
- Sector: energy, infrastructure
- Application: Match segmented components across revisits from varied vantage points to track wear, corrosion, or defects and schedule maintenance.
- Tools/workflow: Periodic capture + SegMASt3R association + change detection; incident management integration.
- Assumptions/dependencies: Outdoor domain adaptation; segmentation of fine structures; safety and access constraints.
- E-commerce visual product matching from user photos
- Sector: retail/e-commerce
- Application: Robust instance-level matching across wide-view user photos for product identification, returns processing, or AR try-on persistence.
- Tools/workflow: AMG + SegMASt3R + catalog association; dustbin to prevent overcommitment on unmatched items.
- Assumptions/dependencies: Domain differences (lighting, backgrounds) require fine-tuning; privacy and consent management for user images.
Glossary
- 3D foundation model (3DFM): Large-scale vision model trained to learn geometry-aware scene representations (depth, shape, pose) from 2D/3D supervision. "3D Foundation Models (3DFMs) are large-scale vision models trained to capture spatial and structural properties of scenes, such as depth, shape, and pose."
- AdamW optimizer: An adaptive optimizer with decoupled weight decay for training deep networks. "The model is trained using AdamW optimizer with an initial learning rate of 1e-4"
- Area Under the Precision–Recall Curve (AUPRC): Threshold-independent metric summarizing precision-recall performance, robust under class imbalance. "Area Under the Precision--Recall Curve (AUPRC) integrates precision over the entire recall axis"
- argmax: Operation that selects the index of the maximal value; used to discretize soft assignments. "a row-wise argmax yielding the final segmentation."
- batched matrix multiplication: Vectorized matrix product applied across a batch dimension for efficiency. "a single batched matrix multiplication aggregates the pixel descriptors inside each mask:"
- bi-stochastic matrix: A matrix whose rows and columns sum to one; output of Sinkhorn for soft assignments. "The output of the Sinkhorn algorithm is a soft bi-stochastic matrix"
- class-agnostic segmentation models: Segmenters that produce object masks without requiring class labels. "Large-scale class-agnostic segmentation models have begun to close this gap."
- contrastive objective: Loss that pulls positive pairs together and pushes negatives apart in feature space. "The head is trained with a contrastive objective patterned after SuperGlue"
- cosine annealing learning rate schedule: LR scheduler that decays the learning rate following a cosine curve. "a cosine annealing learning rate schedule without restarts"
- cosine similarity: A similarity measure based on the angle between vectors, often used for feature matching. "cosine similarity between all source–target descriptors yields a match matrix"
- CroCo: A cross-view completion transformer used to enable cross-image reasoning. "a pair of CroCo~\cite{weinzaepfel2022croco, weinzaepfel2023croco} style intertwined transformer decoders"
- cross-entropy loss: Standard classification loss used here for match and non-match (dustbin) supervision. "We adopt the SuperGlue cross-entropy loss"
- cross-view transformer decoder: Decoder that alternates self- and cross-attention to fuse two images’ features. "Cross-view transformer decoder:"
- DINOv2: A large vision transformer model producing strong generic image features. "features from pre-trained encoders like DINOv2"
- differentiable optimal transport: Trainable matching mechanism based on OT that supports gradient flow. "matched via a differentiable optimal transport and a row-wise argmax"
- differentiable segment matching layer: Neural layer that computes soft and discrete correspondences between segments. "The goal of the differentiable segment matching layer is to establish permutation-style correspondences"
- dustbin: Extra row/column in the affinity matrix to absorb unmatched segments. "Learnable dustbin."
- EarthMatch toolkit: Toolkit to run and compare local feature matchers in a standardized way. "via the EarthMatch toolkit~\cite{Berton_2024_EarthMatch} to obtain segment correspondences."
- Feat2Seg Adapter: Module that maps patch-level features to segment-level features. "introducing a Feat2Seg Adapter that maps the patch-level features"
- geodesic distance: Shortest-path distance on a manifold; here, rotation distance between camera orientations. "defined by the rotational geodesic distance between camera orientations."
- inductive bias: Built-in assumptions guiding a model toward certain solutions; here, geometric reasoning. "leverage the strong spatial inductive bias of a 3D foundation model"
- Instance-level SLAM: Simultaneous localization and mapping that tracks distinct object instances. "and instance-level SLAM~\cite{liang2023dig,xu2019mid}."
- Intersection over Union (IoU): Overlap metric between predicted and ground-truth regions or 3D sets. "point-cloud IoU falls below 0.5"
- LoFTR: A semi-dense local feature matcher producing pixel-level correspondences. "semi-dense LoFTR~\cite{sun2021loftr}"
- MASt3R: A 3D-aware matching model that outputs dense point maps and correspondences. "We adapt MASt3R for segment matching by appending a lightweight segment-feature head"
- MapFree Visual Re-localization Dataset: A challenging outdoor dataset for relative pose and matching under severe changes. "MapFree Visual Re-localization Dataset~\cite{arnold2022mapfree.}"
- metric depth estimation: Predicting absolute scene depth in metric units from images. "used for tasks such as metric depth estimation and camera‑pose prediction."
- MicKey: A 3D matching baseline relying on DINOv2 features. "such as MicKey~\cite{barroso2024matching}"
- optimal transport: A framework for matching distributions under a cost, used for assignment with constraints. "via a differentiable optimal transport and a row-wise argmax"
- perceptual instance aliasing: Confusion between visually similar instances of the same category. "perceptual instance aliasing (i.e., different instances of the same object category in an image potentially lead to mismatches)."
- pseudo-ground truth: Automatically generated supervision used when true labels are unavailable. "generate a pseudo-ground truth for evaluation."
- Recall@k (R@k): Fraction of queries whose correct match appears among the top-k candidates. "Recall@ () denotes the fraction of query segments"
- RoboHop: A topological navigation method leveraging object-centric matching. "an object topology-based mapping and navigation method, RoboHop~\cite{RoboHop}"
- SAM (Segment Anything Model): A foundation model for class-agnostic segmentation. "The Segment Anything Model (SAM)~\cite{kirillov2023segment}"
- SAM2 video propagator: Module in SAM2 that associates masks across video frames. "including the SAM2 video propagator"
- ScanNet++: A large indoor dataset with registered RGB-D, masks, and poses. "Our network is trained on scenes from ScanNet++"
- segment-feature head: Head that aggregates pixel features within masks into segment descriptors. "We denote this Feature-to-Segment head as the segment-feature head."
- Siamese manner: Processing two inputs with shared weights to produce comparable features. "The two images and are processed in a Siamese manner"
- Sinkhorn normalisation: Iterative procedure to produce a (approximately) doubly-stochastic matrix. "by iterations of the Sinkhorn normalisation"
- soft assignment matrix: Probabilistic correspondence matrix before discretization. "transformed into a soft assignment matrix"
- SuperGlue: A graph neural network matcher and its training loss used for correspondence. "We adopt the SuperGlue cross-entropy loss"
- Topological Navigation: Navigation using a graph of places/objects rather than metric maps. "such as 3D Instance Mapping and Topological Navigation."
- Vision Transformer (ViT) encoder: Transformer-based image encoder producing tokenized patch embeddings. "by a weight‑sharing ViT encoder~\cite{dosovitskiy2020image}"
- wide-baseline segment matching: Matching segments across images with large viewpoint changes and rotations. "wide-baseline segment matching"
Collections
Sign up for free to add this paper to one or more collections.

