- The paper introduces a hybrid semantic alphabet size estimator that integrates Good-Turing and spectral methods to improve uncertainty quantification.
- It employs a coverage-adjusted discrete semantic entropy metric to reduce bias in LLM response uncertainty measurements.
- Empirical evaluations on models like Gemma-2-9B and Llama-3.1-8B demonstrate enhanced incorrectness detection with lower mean-squared error.
Estimating Semantic Alphabet Size for LLM Uncertainty Quantification
Introduction
This essay explores a method for estimating the semantic alphabet size of responses generated by LLMs to improve uncertainty quantification (UQ) techniques. Semantic entropy, a sample-based metric used to determine LLM uncertainty, underpins the research focus. Through a modified semantic alphabet size estimator, the paper investigates how coverage-adjusted discrete semantic entropy estimates minimize bias and enhance the precision of LLM inaccuracy classification.
Background
Semantic Entropy
Semantic entropy quantifies the inherent uncertainty of a system, formulated by integrating semantic clustering with traditional information entropy concepts. Lexically distinct sequences that share meaning fall under semantic equivalence classes, which are utilized to determine semantic entropy. The canonical approach to measuring discrete semantic entropy is often biased, underestimating the true semantic entropy for practical sample sizes of LLM responses, suggesting a need for an enhanced estimator.
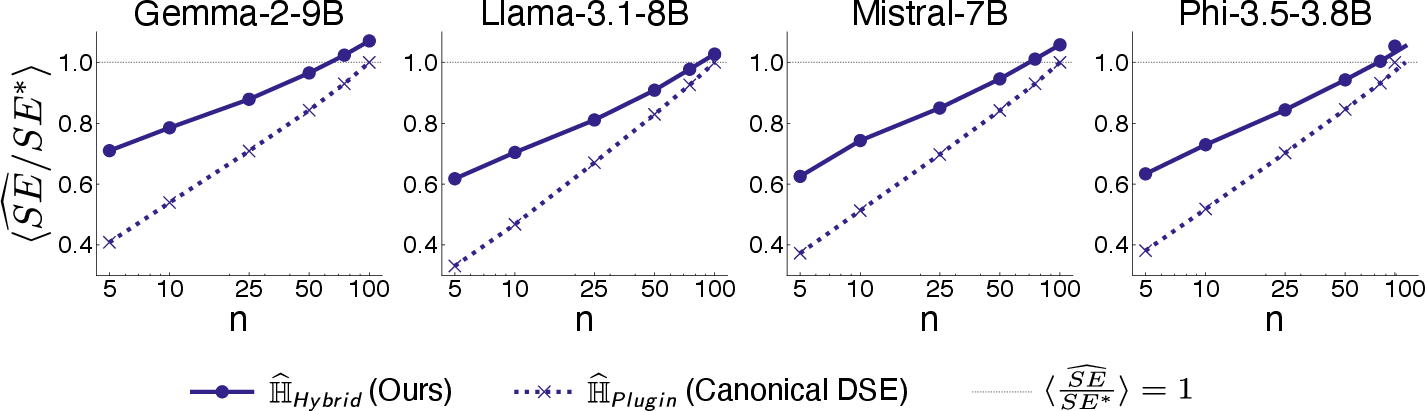
Figure 1: Illustrating underestimation in discrete semantic entropy calculation with typical sample sizes. The estimation is consistently below the white-box semantic entropy for n≤100.
Proposed Method
Semantic Alphabet Size Estimation
The paper extends upon classical estimation techniques from population ecology to address the underestimated cardinality of semantic equivalence classes. This is accomplished through the introduction of a hybrid semantic alphabet size estimator that adapts established methods like Good-Turing and spectral methods, balancing limitations inherent to each.
Coverage-Adjusted Entropy
Incorporating a semantic alphabet size estimator into the discrete semantic entropy calculation, the research proposes a coverage-adjusted estimator, blending traditional entropy formulations with the newly proposed estimator for improved accuracy.
Experiments and Results
Empirical Evaluations
Experimental evaluations utilize LLMs, including Gemma-2-9B and Llama-3.1-8B, over question-answering datasets like SQuAD 2.0, to validate estimator performance. Metrics such as mean-squared error (MSE) and AUROC are employed, showcasing the hybrid estimator's superior accuracy in replicating white-box conditions.
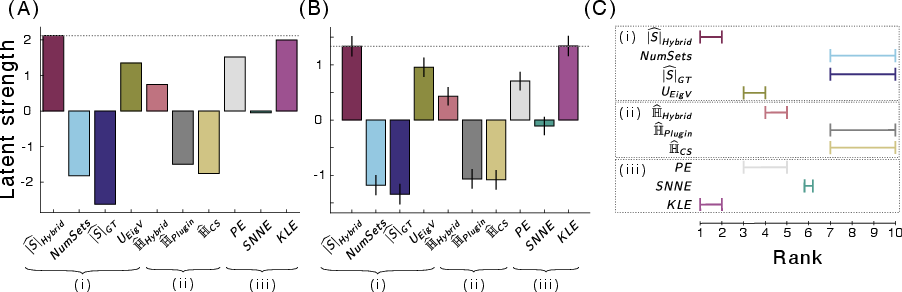
Figure 2: Establishing overall performance of ten UQ methods on incorrectness detection. Showcases improved estimator rankings when adjusting for estimation uncertainty.
Incorrectness Detection
The newly proposed estimator demonstrates enhanced capability in classifying incorrect LLM responses, predominantly outperforming conventional UQ methods. The augmented performance underscores the critical role of accurate semantic alphabet size estimation in LLM applications.
Discussion
Implications
The work suggests that semantic alphabet size estimation could extend beyond its initial scope within uncertainty estimation, potentially influencing broader applications in eliciting unobserved knowledge from LLMs.
Limitations
Despite achieving accuracy, limitations persist regarding the use of models beyond 9 billion parameters, and potential bias stemming from clustering strategies in semantic equivalence classification.
Conclusion
This research offers significant strides in refining UQ for LLMs by improving semantic entropy estimates through innovative estimators. The approach not only surpasses other UQ methods in hallucination detection but also remains computationally viable, paving the way for future exploration in robust AI system development.