- The paper introduces semantic density for quantifying LLM uncertainty by analyzing confidence within a semantic embedding space.
- It leverages a modified kernel density estimation and natural language inference to assess semantic alignment among generated responses.
- Experimental results demonstrate superior performance and robustness over existing uncertainty measures across various language model settings.
Semantic Density: Uncertainty Quantification for LLMs through Confidence Measurement in Semantic Space
Introduction
The investigation into the automatic estimation of uncertainty in LLMs has gained prominence due to rising demands for reliability and safety in their outputs. The paper introduces the concept of "semantic density" as a novel method for uncertainty quantification, specifically designed to overcome the limitations of prior techniques. These limitations include a focus on lexical differences, task-specific adjustments, and the inability to apply uniformly over varying response types and domains.
Methodological Framework
Semantic Density Framework
The semantic density mechanism provides an "off-the-shelf", response-specific confidence measure in semantic space. This framework is adaptable across different models and tasks without needing additional training. It utilizes probability distributions inherent to the LLM outputs when positioned within a semantic space that reflects the contextual semantic similarities of responses.
Core Components
- Semantic Space Definition: The model leverages an embedding space with euclidean characteristics, where vector distances reflect semantic similarity. This space is defined by a normalized, dimension-invariant structure suitable for diverse problem types.
- Kernel Density Estimation (KDE): Adapting KDE for discrete LLM outputs, the framework utilizes a modified Epanechnikov kernel to estimate the probability densities from samples obtained via diverse beam search. This allows for a practical, sample-efficient approach to density estimation in semantic space.
- Integration with Natural Language Inference (NLI): By employing NLI models, semantic relationships in responses are analyzed to quantify the degree of semantic alignment or divergence. This analysis feeds into the estimation of semantic density, gauging confidence based on the contextual agreement among potential output responses.
Experimental Evaluation
The efficacy of semantic density was tested against several state-of-the-art uncertainty quantification techniques across seven LLMs. These included measures such as semantic entropy and P(True). Semantic density consistently demonstrated superior performance in distinguishing correct from incorrect responses, showing particular robustness when fewer samples or more diverse responses are used.
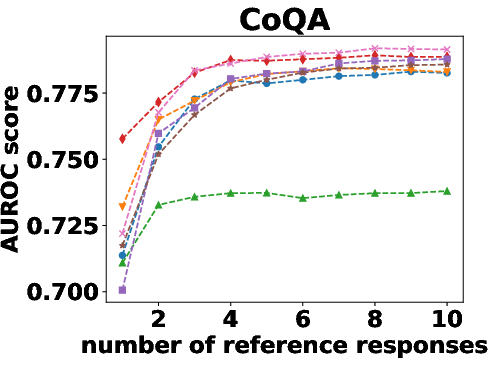
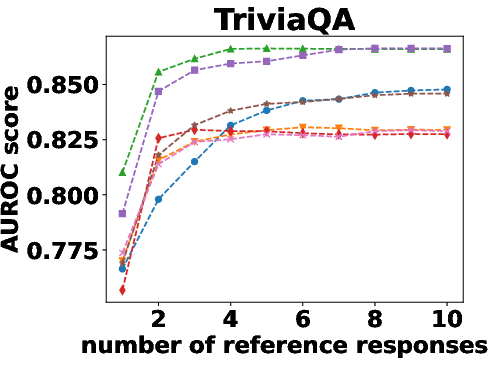
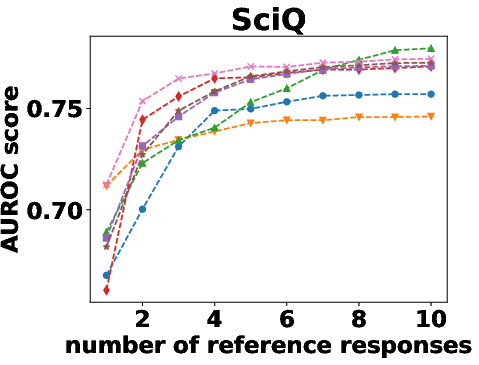
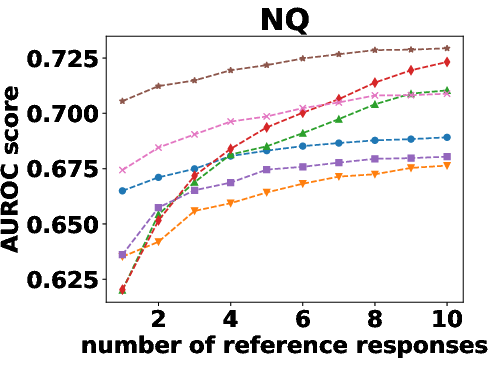
Figure 1: AUROC scores of semantic density with one to 10 reference responses.
Robustness Testing
Semantic density's robustness was confirmed across varying conditions such as different numbers of reference responses and alternative sampling strategies. Results indicated that performance only slightly diminished with fewer samples, and remained stable across different sampling preferences.
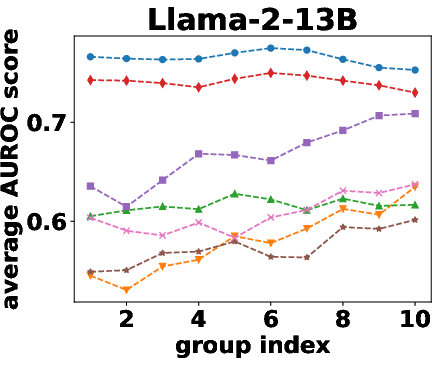
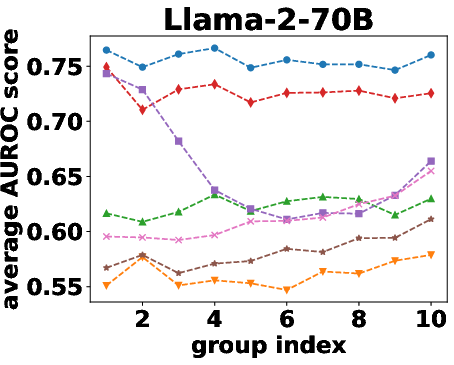
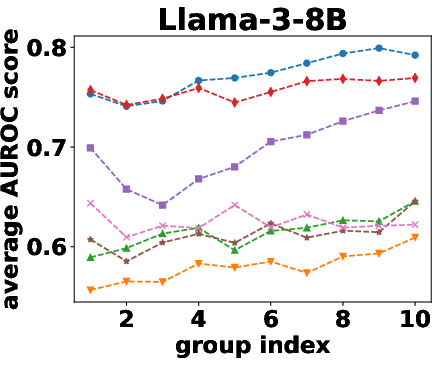
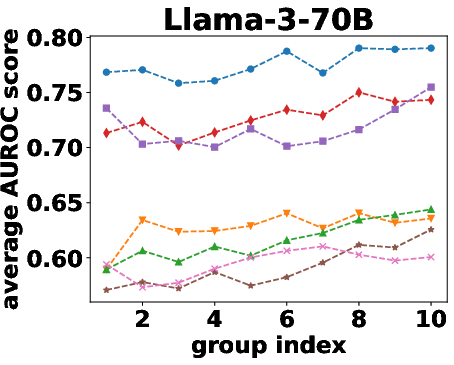
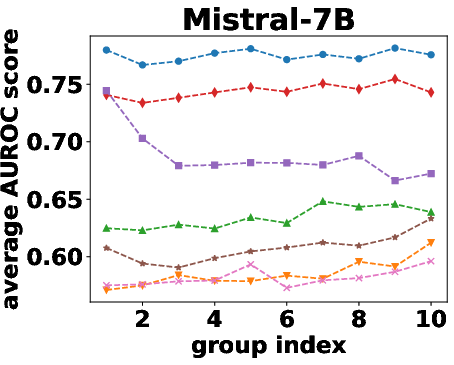
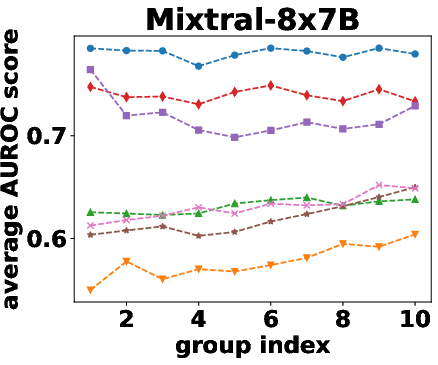
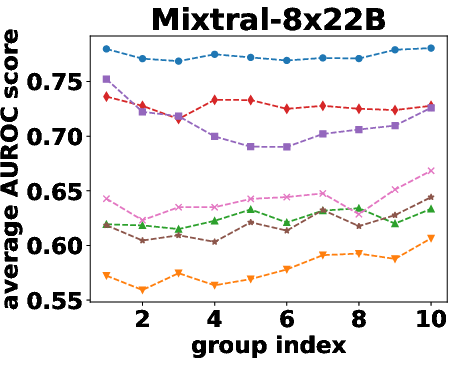

Figure 2: AUROC scores over the different beam groups.
Discussion and Future Developments
The implementation of semantic density addresses critical shortcomings in current uncertainty measures, particularly in capturing semantic, rather than merely lexical, variances. Future improvements may focus on refining the semantic space embeddings and exploring advanced kernel functions tailored to semantic relationships.
While currently robust, the need for output probability access poses a restriction for models where such details are proprietary. Nonetheless, initial empirical results across varied language tasks hint at broad adaptability, warranting further exploration into extended applications such as handling longer text sequences or integrated real-time deployment in dynamic environments.
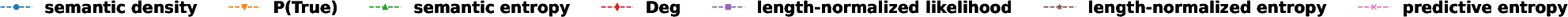
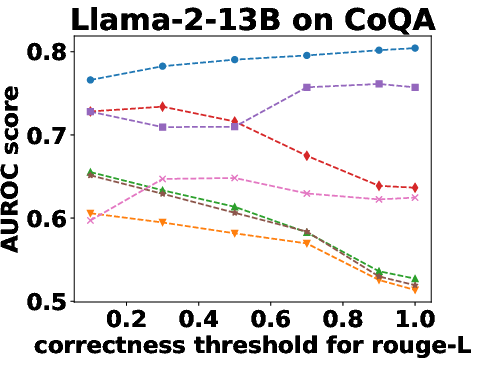
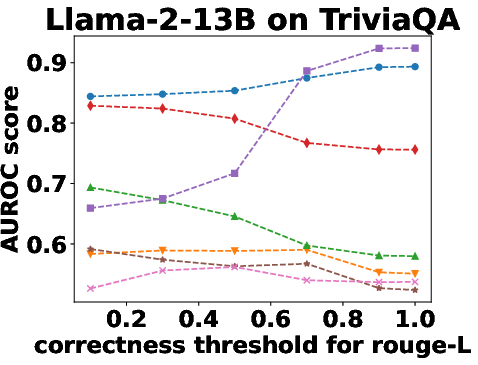
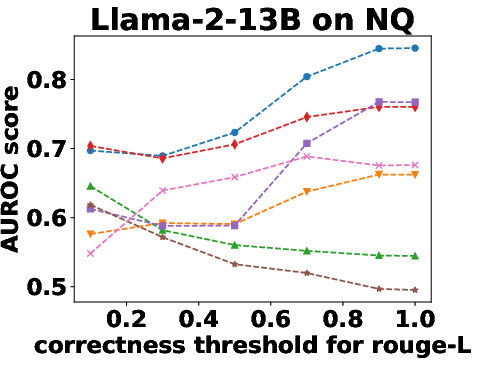
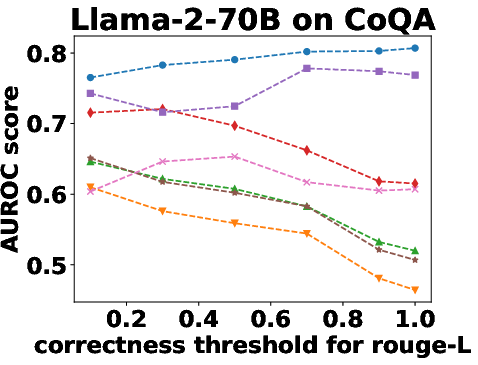
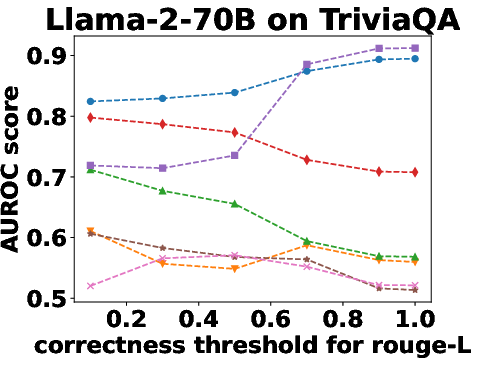
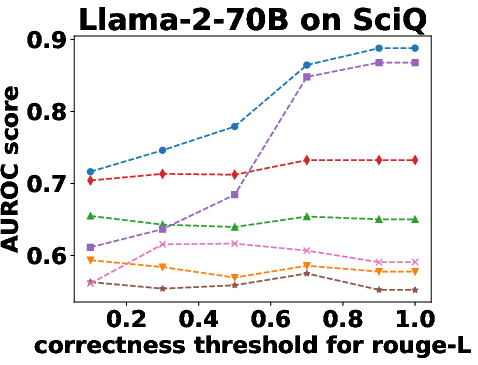
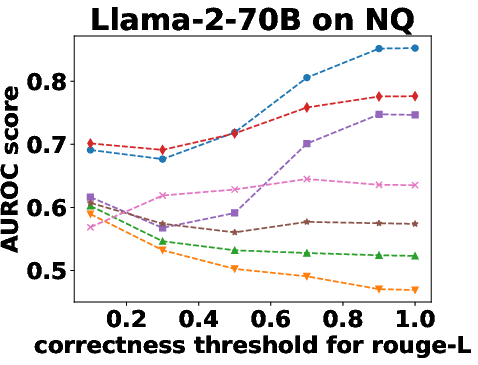
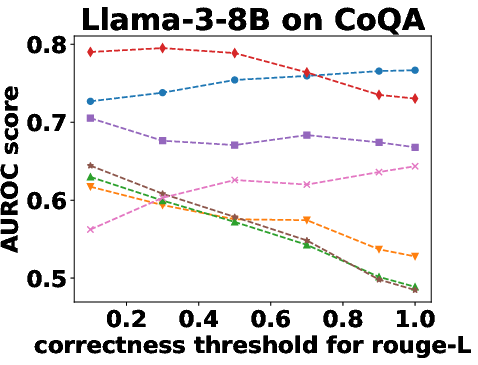
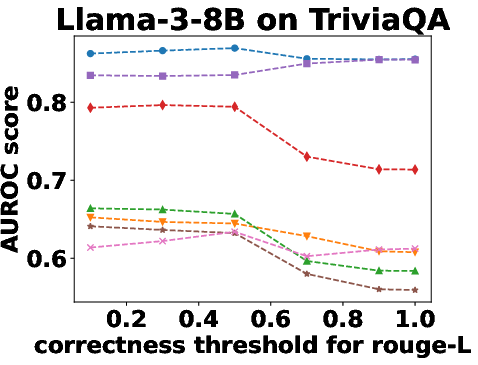
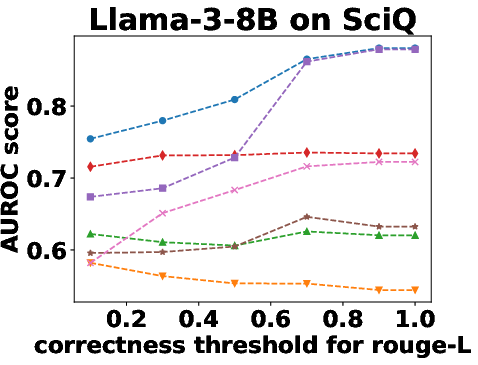
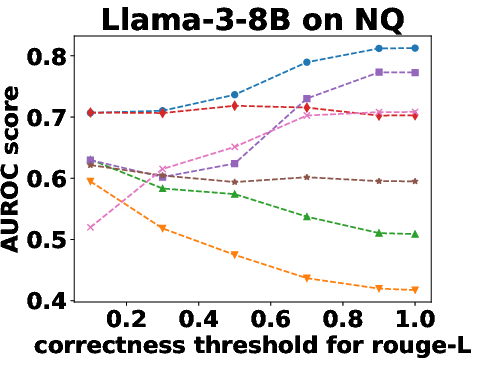
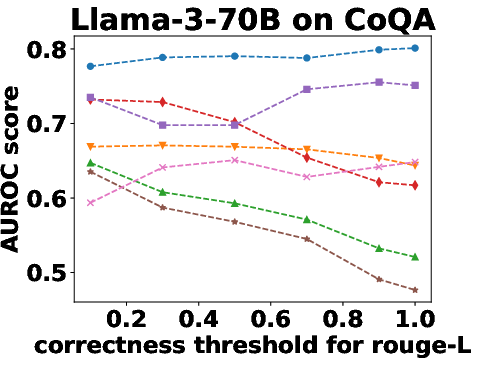
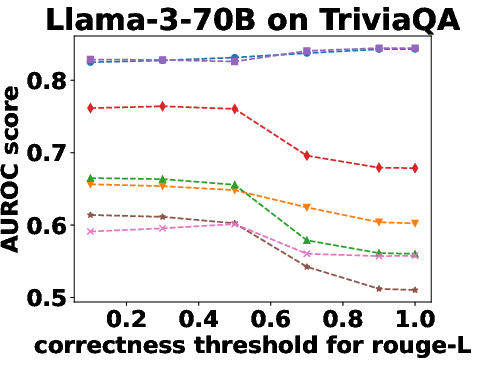
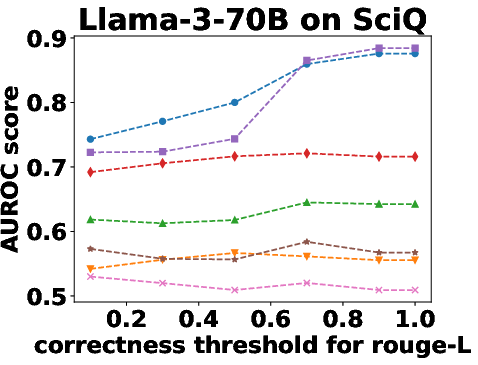
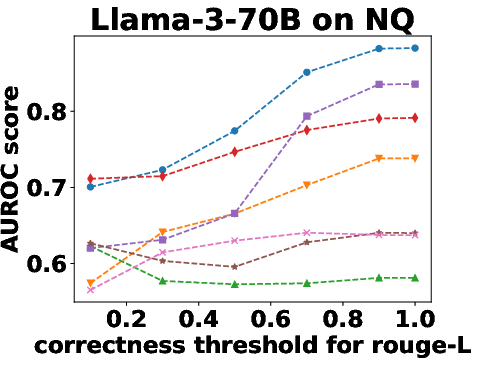
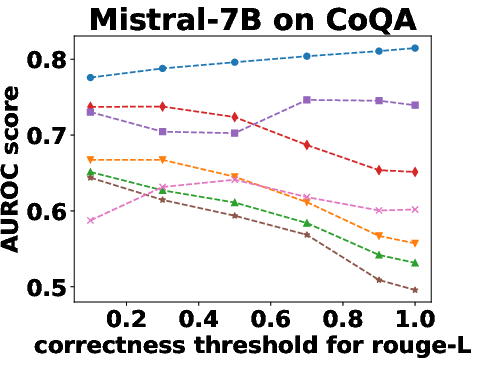
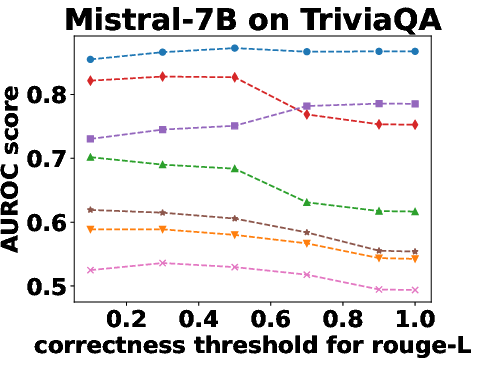
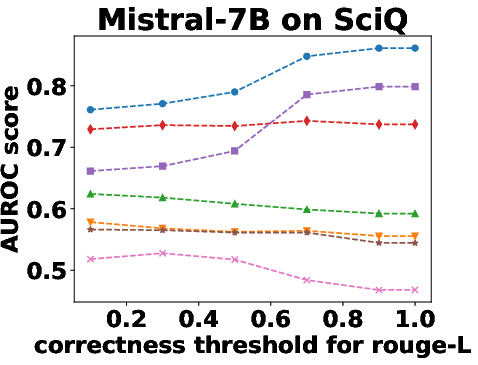
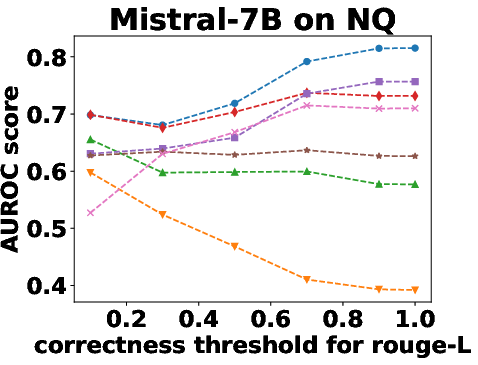
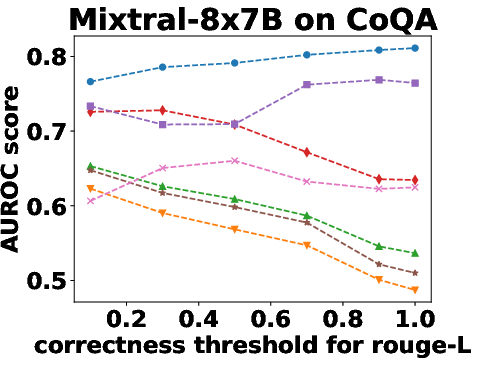
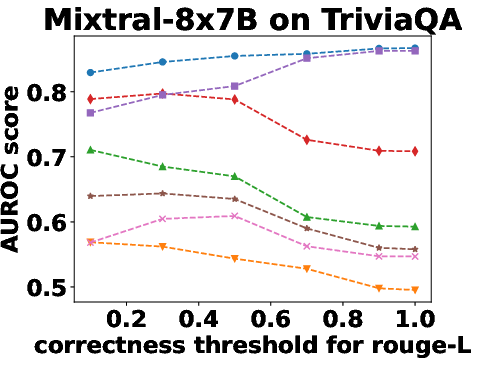
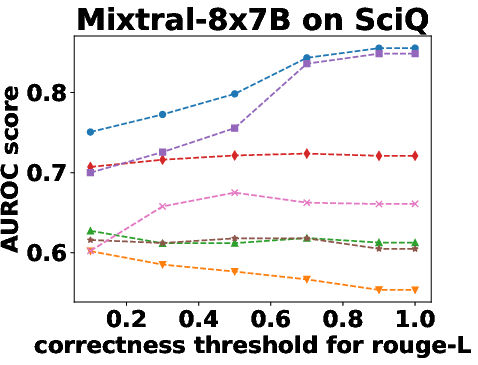
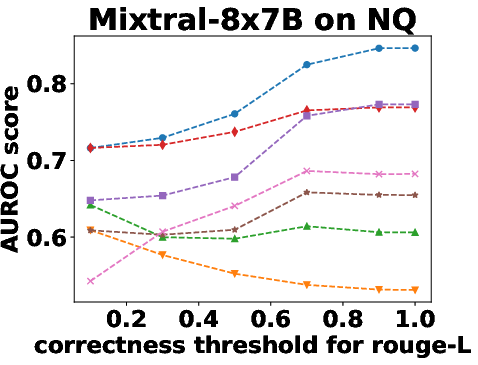
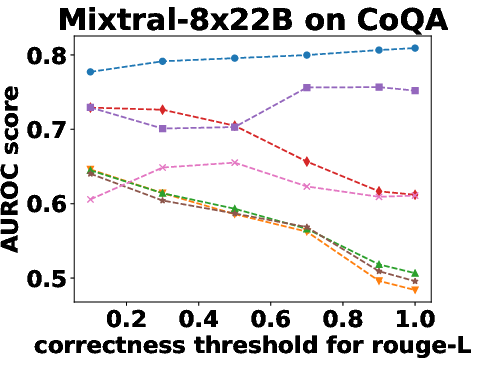
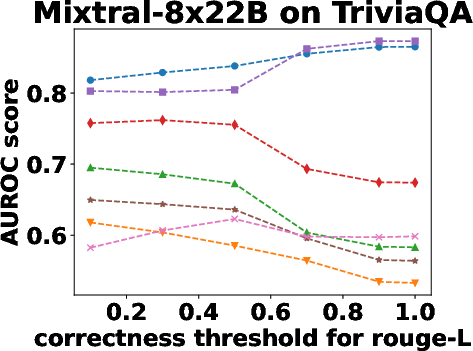
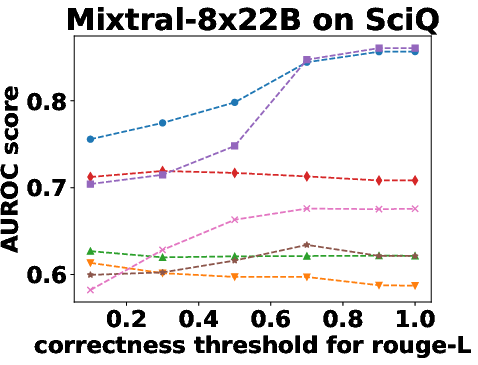
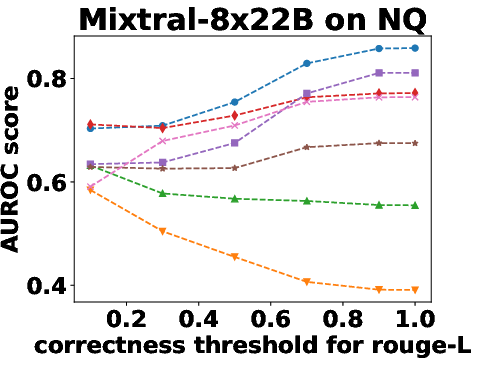
Figure 3: Performance Evaluation over Different Correctness Checking Criteria.
Conclusion
Semantically-informed uncertainty measures like semantic density represent a pivotal evolution towards safer, more trustworthy AI models. By offering an adaptable, precise metric for response confidence, this method paves the way for enhanced reliance on LLMs, particularly in safety-critical applications where the consequences of errors are severe.