- The paper introduces Kernel Language Entropy (KLE), a novel method that quantifies semantic uncertainty in LLM outputs by employing semantic similarity kernels.
- It applies von Neumann entropy to semantic kernels computed from NLI-based graphs, outperforming previous methods in AUROC and AUARC metrics.
- KLE’s robust performance across datasets like TriviaQA, SQuAD, and BioASQ demonstrates its potential to enhance the reliability of language models in critical applications.
Kernel Language Entropy: Fine-grained Uncertainty Quantification for LLMs from Semantic Similarities
The paper "Kernel Language Entropy: Fine-grained Uncertainty Quantification for LLMs from Semantic Similarities" proposes a novel method for uncertainty estimation in LLMs by introducing Kernel Language Entropy (KLE). This approach addresses the challenge of quantifying semantic uncertainty in language outputs, which is critical for applications where safety and reliability are paramount.
Kernel Language Entropy Overview
KLE defines positive semidefinite kernels that encode semantic similarities among LLM outputs. This approach allows for a more nuanced capture of uncertainty compared to previous methods, which often rely on hard clustering of outputs into semantically equivalent groups. The key innovation in KLE is the use of the von Neumann entropy to quantify uncertainty, informed by semantic similarities.
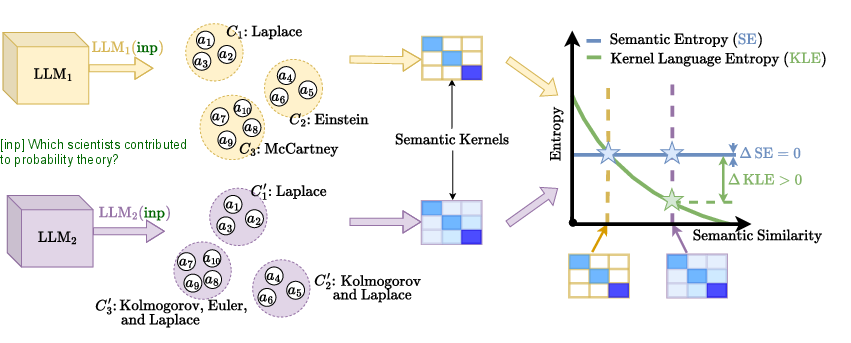
Figure 1: An illustration of KLE using KLE-c on semantic clusters, demonstrating finer uncertainty quantification compared to hard clustering methods.
Motivation and Theoretical Foundations
Limitations of Previous Methods
Semantic Entropy (SE) was introduced to estimate uncertainty based on clusters of semantic equivalence. However, SE lacks the capability to capture the continuum of semantic similarity—it treats all semantically different answers as equally distinct, which is a significant limitation. KLE addresses this by encoding a distance metric within the semantic space, adding precision to uncertainty estimation.
Kernel and Entropy
KLE utilizes a kernel-based approach to represent semantic similarity. The von Neumann entropy, calculated over these kernels, serves as the uncertainty measure. This entropy accounts for the semantic overlap between answers, allowing KLE to better distinguish between outputs with similar meanings.
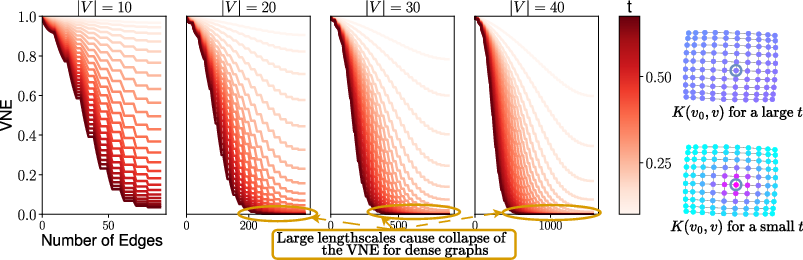
Figure 2: Entropy Convergence Plots for heat kernels across graphs of various node counts, illustrating the rapid convergence of VNE to zero without needing validation sets.
Implementation Details
Semantic Graph Kernels
To practically apply KLE, semantic graphs are constructed wherein nodes represent LLM outputs and edges reflect semantic similarity. This is achieved via Natural Language Inference (NLI) models, such as DeBERTa, to determine entailment probabilities. Graph kernels like heat and Matérn kernels are then applied to these graphs to produce the semantic kernels necessary for KLE.
Algorithm for KLE
- Sample n answers from an LLM given an input.
- Construct semantic graphs based on NLI-model predictions.
- Calculate semantic kernels over the graph.
- Compute the von Neumann entropy of the kernel to estimate uncertainty.
This method can be applied both in white- and black-box scenarios, broadening its applicability.
Comparison and Experimental Results
KLE's effectiveness was validated across multiple datasets, including TriviaQA, SQuAD, and BioASQ, using the Area under the Receiver Operating Curve (AUROC) and the Area Under the Accuracy-Rejection Curve (AUARC) as metrics.
KLE significantly outperformed baselines such as semantic entropy and token predictive entropy, particularly for instruction-tuned models in scenarios involving nuanced language generation.
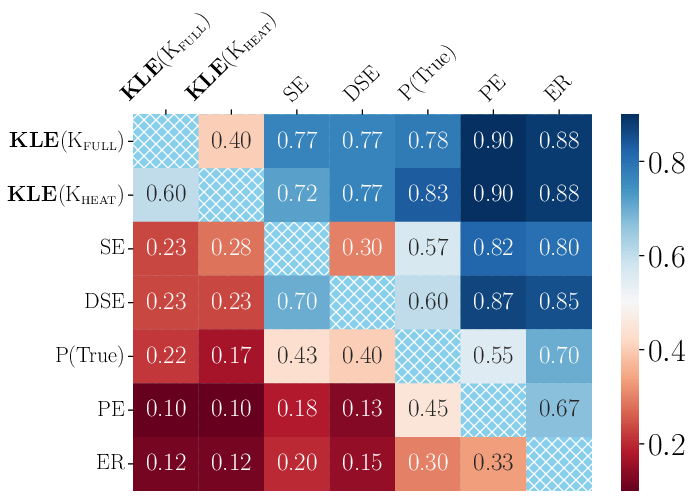
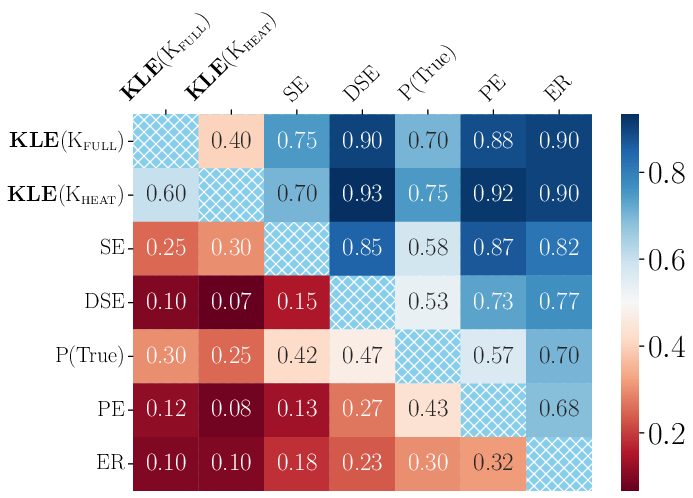
Figure 3: Win rate measured with AUROC across various experimental scenarios, showing KLE’s superiority over baseline methods.
Conclusion
Kernel Language Entropy presents a significant advancement in quantifying semantic uncertainty in LLMs. By integrating fine-grained semantic similarities into the uncertainty estimation process, KLE provides a more reliable measure that can predict model errors and hallucinations more accurately. The approach opens possibilities for further research into semantic kernels and their applications across various domains of natural language generation.
KLE's flexibility and robust performance make it a promising tool for enhancing the trustworthiness of AI applications, especially in critical areas where the cost of semantic errors is high. Future work can explore other forms of semantic or syntactic kernels to broaden the scope of KLE's applicability.