- The paper demonstrates that tool-augmented learning scales factual recall beyond the linear parameter limits of in-weight memorization.
- It rigorously derives theoretical lower bounds for memorization and upper bounds for tool query generation using transformer architectures.
- Controlled experiments with synthetic and pretrained models validate that in-tool learning preserves general capabilities while enhancing training efficiency.
Introduction and Motivation
The paper "Provable Benefits of In-Tool Learning for LLMs" (2508.20755) presents a rigorous theoretical and empirical analysis of the trade-offs between in-weight learning (memorization within model parameters) and in-tool learning (external retrieval via tool use) for factual recall in LLMs. The central thesis is that the capacity of a model to memorize facts in its weights is fundamentally limited by its parameter count, whereas tool-augmented models can, in principle, achieve unbounded factual recall by learning to interface with external databases or APIs. This work formalizes these claims, provides explicit circuit constructions, and validates them through controlled and large-scale experiments.
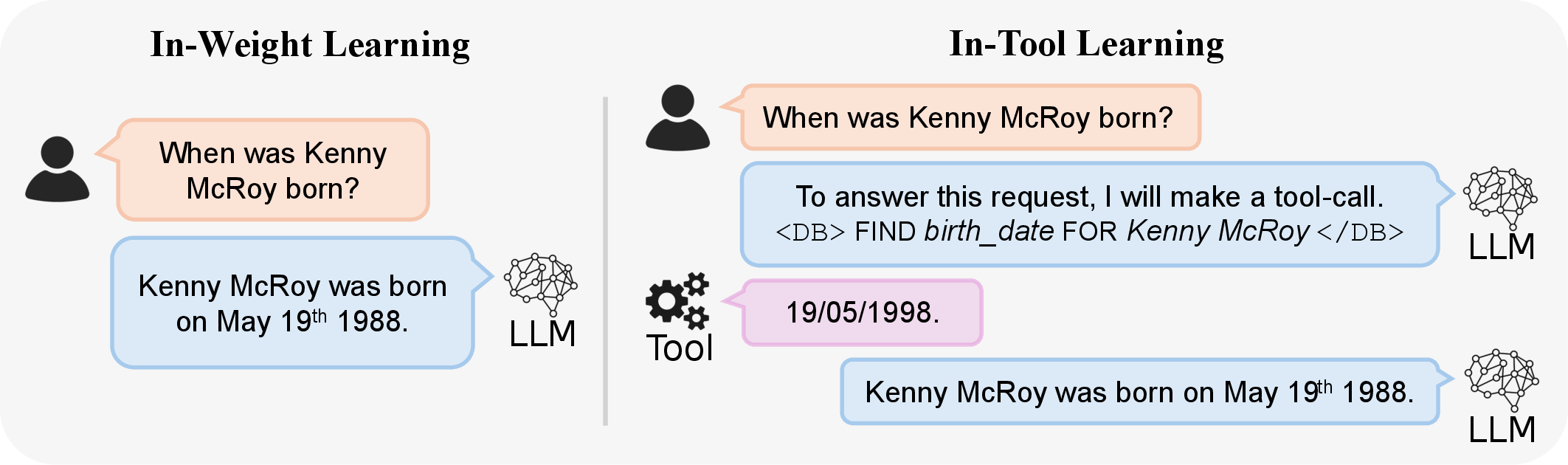
Figure 1: Illustration of the trade-off between in-weight memorization and in-tool learning, highlighting scalable recall and preservation of prior capabilities via tool use.
Theoretical Foundations
Lower Bound on In-Weight Memorization
The authors derive a lower bound on the number of parameters required for a model to memorize a set of facts. For a dataset of N facts, the minimum parameter requirement scales linearly with N, as formalized in Theorem 1. This result is robust to quantization and dataset structure, with empirical studies indicating an effective representational capacity of approximately 2 bits per parameter. The lower bound is tightened when facts are correlated, reducing the number of "effective" facts that must be stored.
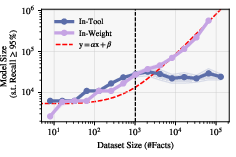
Figure 2: Empirical scaling of parameter requirements for in-weight memorization, confirming the linear trend predicted by theory.
In contrast, the paper proves that a transformer with O(∣A∣2) parameters (where ∣A∣ is the number of attributes) can learn to construct tool queries and retrieve facts from an external database, independent of the number of names or values. The explicit circuit construction leverages attention heads and positional encodings to parse queries, emit tool calls, and format answers. This result demonstrates that tool-augmented models can scale factual recall without increasing model size, provided they master the querying protocol.
Controlled Experimental Validation
The authors conduct controlled experiments using synthetic biographical datasets and small Llama3-style transformers. Two regimes are compared: in-weight learning (direct answer generation) and in-tool learning (structured tool query followed by retrieval). Results show that in-weight models require ever-larger architectures as the number of facts grows, while in-tool models exhibit a sharp phase transition: beyond a critical dataset size, the parameter requirement saturates, and the model generalizes tool-use across databases.
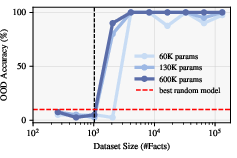
Figure 3: Transition from memorization to retrieval in in-tool models, with stable OOD accuracy post-transition.
The experiments also demonstrate that introducing correlations between facts (e.g., shared attributes among family members) reduces the parameter requirement for in-weight memorization, consistent with the theoretical lower bound.
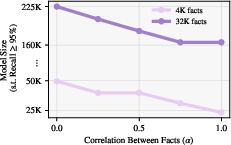
Figure 4: Effect of fact correlation on compressibility and parameter requirements for in-weight memorization.
Large-Scale Experiments with Pretrained LLMs
The study extends its analysis to pretrained models (SmolLM2, Llama3.1/3.2) fine-tuned on factual recall tasks. Key findings include:
- In-weight finetuning degrades general capabilities (e.g., HellaSwag accuracy), especially for smaller models and larger factual loads.
- Tool-augmented learning preserves general capabilities and induces minimal drift in output distributions, as measured by Total Variation (TV) distance.
- Training efficiency: Tool-use is acquired rapidly and is independent of dataset size, whereas in-weight memorization requires more steps as the factual load increases.
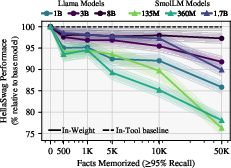
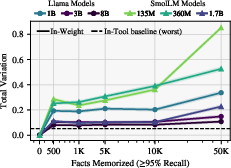
Figure 5: HellaSwag performance versus memorization load, showing degradation for in-weight learning and stability for in-tool learning.
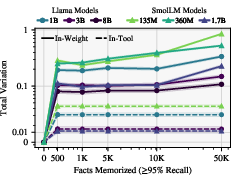
Figure 6: TV distance as a function of memorization load, with in-tool learning exhibiting minimal deviation from base models.
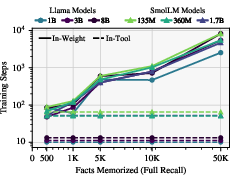
Figure 7: Training steps required for memorization, highlighting the efficiency of tool-use acquisition.
Scaling and Recall Requirements
Further analysis reveals that the parameter requirement for in-weight learning increases steeply with the desired level of factual recall, especially as the number of facts grows. In-tool learning remains robust, making it preferable for high-recall, large-database applications.
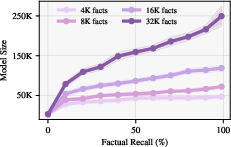
Figure 8: Scaling of parameter requirements with factual recall, emphasizing the benefits of in-tool learning for large databases.
Training Dynamics and Capability Preservation
The training dynamics indicate that most capability loss and distributional shift occur early during in-weight finetuning, while tool-use mastery is achieved quickly and preserves prior skills. This supports the argument for modular, tool-augmented architectures in LLM development.
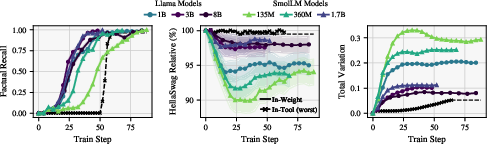
Figure 9: Metrics throughout training, showing full recall and high capability retention for tool-use models.
Implications and Future Directions
Practical Implications
- Scalability: Tool-augmented LLMs can scale factual recall without increasing model size, making them suitable for knowledge-intensive applications.
- Preservation of Prior Capabilities: Externalizing factual storage via tool use prevents interference and forgetting, maintaining general language abilities.
- Training Efficiency: Tool-use protocols are learned rapidly, reducing compute requirements for knowledge integration.
Theoretical Implications
- Capacity Bottleneck: The linear scaling of parameter requirements for in-weight memorization imposes a hard ceiling on monolithic model design.
- Phase Transition in Learning: The shift from memorization to rule-based querying in tool-augmented models mirrors phenomena such as grokking and compositional generalization.
Future Developments
- Extension to Richer Tool Use: Analysis of tool-augmented reasoning, multi-step workflows, and integration with learnable memory modules.
- Optimization Dynamics: Investigation of training stability and optimization difficulty in real-world tool-use scenarios.
- Generalization to Unstructured Knowledge: Application of these principles to domains with ambiguous fact-rule boundaries, such as mathematics and commonsense reasoning.
Conclusion
This work establishes a rigorous foundation for the superiority of in-tool learning over in-weight memorization in LLMs. By combining theoretical bounds, explicit constructions, and empirical validation, the authors demonstrate that tool-augmented workflows offer scalable, efficient, and robust solutions for factual recall. The results advocate for a paradigm shift in LLM design, prioritizing modular architectures capable of querying and orchestrating external resources rather than internalizing ever more information. This has significant implications for the future of AI systems, particularly in knowledge-intensive and agentic applications.

