- The paper introduces the Active Reading framework that uses self-generated learning strategies to substantially improve fact recall in language models.
- It employs a two-stage synthetic data generation pipeline that outperforms traditional methods by boosting factual recall from 16% to 66% on SimpleWikiQA.
- The approach scales effectively with gains in QA accuracy up to 4 billion generated words and demonstrates robust performance across expert domains.
Learning Facts at Scale with Active Reading
The paper "Learning Facts at Scale with Active Reading" explores the deficiencies of current LLMs in reliably learning and recalling factual knowledge and proposes a novel framework named Active Reading to address this issue. This approach leverages self-generated learning strategies to better internalize and recall facts from a closed body of knowledge, thereby enhancing the factual accuracy of models.
Active Reading Framework
Active Reading is introduced as a two-stage synthetic data generation pipeline, conceptualized to mimic human-style active engagement with new information. In the first stage, the model autonomously suggests a set of learning strategies tailored to the specifics of a given document. These strategies encompass paraphrasing, knowledge linking, active recall, and analogical reasoning, among others. Subsequently, these strategies are applied individually, generating diverse and contextually relevant training data.

Figure 1: Active Reading as a two-stage synthetic data generation pipeline. In the first stage, the model comes up with diverse learning strategies specific to the given document. In the second stage, strategies are applied independently to generate the self-training data.
This method diverges from traditional augmentation strategies that depend on fixed templates, enabling more nuanced data synthesis which supports reliable knowledge digestion and improves factual recall.
The efficacy of Active Reading was validated through its application on expert domains such as SimpleWikiQA and FinanceBench. Models trained with Active Reading exhibited substantial gains in factual recall. For instance, on SimpleWikiQA, factual recall improved dramatically from 16% to 66% compared to vanilla finetuning.
Furthermore, the study revealed Active Reading's advantageous scaling behavior. Unlike baseline methods like paraphrasing and synthetic QA generation, which plateau as more synthetic data is generated, Active Reading continues to deliver gains in QA accuracy even at the scale of 4 billion generated words.
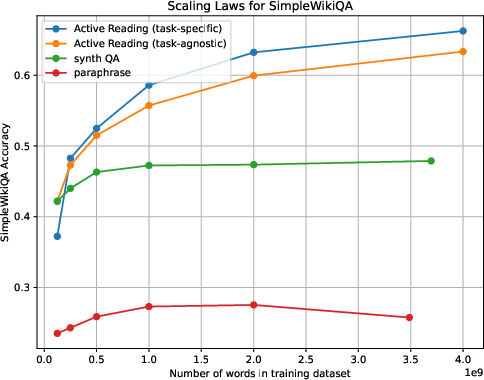
Figure 2: Scaling trends with respect to the number of generated words for each method. While baseline data augmentation strategies like paraphrasing and synthetic QA generation plateau in performance as we scale the amount of synthetic data, Active Reading leads to continued gains in downstream QA accuracy up to 4B generated words.
Applications in Large-Scale Settings
To test the scalability of Active Reading, the method was employed to generate 1 trillion tokens from the entire Wikipedia corpus, which was then used to train Meta WikiExpert. This model outperformed significantly larger models on various factual QA tasks, including outperforming models with up to 671 billion parameters on SimpleQA.
A noteworthy observation during scaling experiments was the critical role of mixing pre-training data to maintain model performance in scaled settings. Increasing the pre-training data mix proportion helped recover performance on both the target task and guardrail tasks, highlighting the potential necessity of diverse pre-training data for robust knowledge retention.
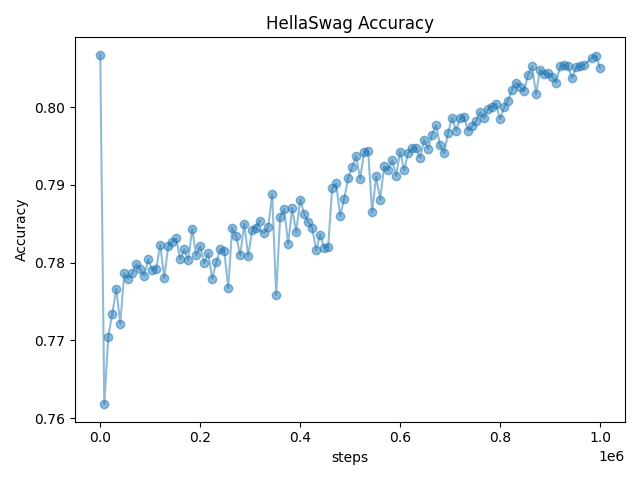
Figure 3: Drop and recovery of performance for guardrail task HellaSwag, mirroring the drop and recovery on NaturalQuestions seen in the scaling behavior.
Implications and Future Directions
The findings suggest that Active Reading could form a cornerstone in the development of more factually robust LLMs. It provides a pathway to integrating vast amounts of knowledge at scale, which is promising for applications requiring comprehensive factual accuracy.
Future research could explore methods to further optimize the synergy between generated learning strategies and diverse pre-training data to enhance learning flexibility. Additionally, the integration of Active Reading strategies with retrieval-augmented generation techniques warrants investigation to bridge the performance gap between parametric models and hybrid systems.
Conclusion
Active Reading emerges as a viable framework for improving the factual accuracy and recall capabilities of LLMs through its human-inspired approach to synthetic data generation. By fostering diverse and context-sensitive learning, it sets a novel precedent for scalable and reliable knowledge acquisition in AI models, driving advancements in the factual consistency of LLMs across a wide range of domains.