- The paper demonstrates that persona prompting can enhance task performance through an Expertise Advantage while also exposing robustness challenges.
- It introduces quantitative metrics such as Expertise Advantage Gap, Robustness Metric, and Fidelity Rank Correlation to systematically assess persona effects.
- Mitigation strategies like explicit instruction and iterative refinement improve performance in larger models, though fidelity inconsistencies persist.
Introduction
"Principled Personas: Defining and Measuring the Intended Effects of Persona Prompting on Task Performance" investigates the use of persona prompting in improving task performance of LLMs by defining and measuring three key desiderata: Expertise Advantage, Robustness, and Fidelity. The study evaluates various persona characteristics and proposes strategies to mitigate unintended effects observed with persona prompts.
Desiderata Definitions and Methodology
The authors identify three normative claims related to persona prompting:
- Expertise Advantage: Personas with domain-specific expertise should perform as well or better than without a persona.
- Robustness: Task-irrelevant persona attributes should not affect model performance.
- Fidelity: Models should reflect performance changes consistent with persona attributes like specialization and education level.
To evaluate these claims, the study benchmarks nine LLMs using 27 tasks, introducing metrics such as Expertise Advantage Gap, Robustness Metric, and Fidelity Rank Correlation to quantify these effects.

Figure 1: We define three desiderata for persona prompting: Task experts should perform on par or better than the no-persona model (Expertise Advantage).
Expertise Advantage
Testing revealed that expert personas generally maintain or enhance performance, with variations in magnitude across model families and task types. Although expert personas can negatively impact performance due to misalignment with task demands, Llama-3.1-70B showed consistent improvements with dynamic expert personas, achieving up to 100% in some evaluations.
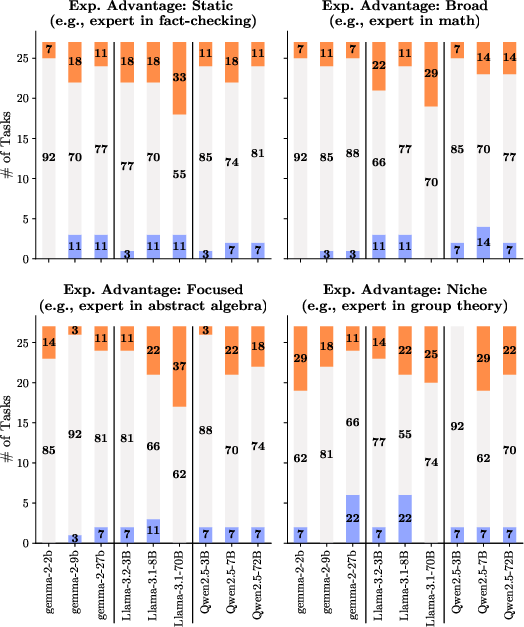
Figure 2: Expertise Advantage, categorized against task baselines, demonstrating significant performance increases with dynamic expert personas.
Robustness
The study highlights a lack of robustness, evidenced by significant performance reductions when irrelevant persona attributes like names or favorite colors are introduced. Surprisingly, models occasionally show improved performance under irrelevant attributes, suggesting latent biases in model training.
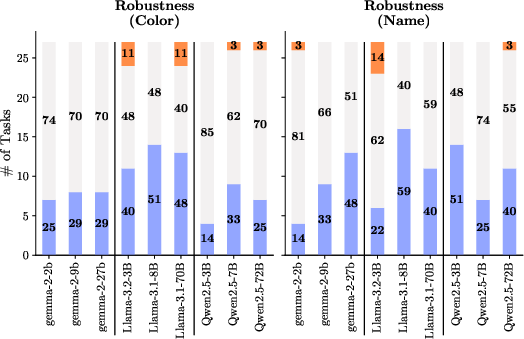
Figure 3: Robustness. Irrelevant persona attributes severely degrade task performance across all model families.
Fidelity
Fidelity evaluations indicated inconsistencies in how models reflect expected performance changes based on persona attributes. High fidelity was observed in aligning performance with educational levels, but specialization levels showed weaker consistency. This indicates an intrinsic challenge in translating nuanced persona attributes into meaningful model behavior changes.
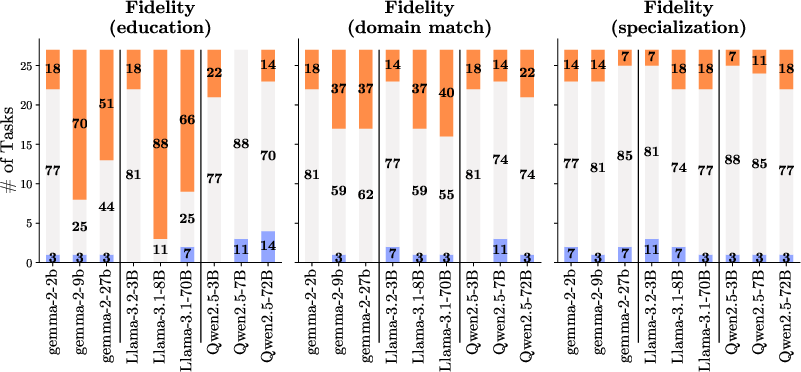
Figure 4: Fidelity metrics showing partial alignment with educational hierarchy, contrasting with inconsistent specialization-level performance.
Mitigation Strategies
To address observed issues, the paper explores three mitigation techniques:
- Instruction: Incorporates explicit behavioral constraints into prompts.
- Refine: Employs iterative refinement of responses, initially without personas.
- Refine + Instruction: Combines both approaches for stronger mitigation effects.
While generally ineffective for smaller models, these strategies significantly enhance robustness and maintain expertise advantage in larger models, though limitations in improving Fidelity were noted due to potential anchoring effects.
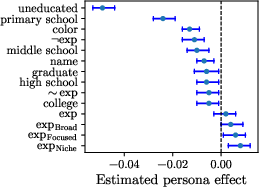
Figure 5: Persona effect on model performance, showcasing variance introduced by different mitigation strategies.
Conclusion
This comprehensive study highlights that persona prompting requires careful design to avoid unintended model behaviors. The proposed desiderata and metrics serve as frameworks for evaluating and refining persona-based interactions in LLMs. Future work should address extending these findings into unstructured or open-ended task domains and exploring dynamic multi-persona strategies. These advances hold promise for enhancing AI alignment with user expectations and improving task-specific interactions.
In conclusion, the research underscores the necessity for principled persona design, aiming to foster robust, context-sensitive AI applications while highlighting the complexities inherent in persona-driven LLMs.