- The paper introduces a novel ExpertPrompting method that generates detailed expert identities automatically to guide LLMs for improved response quality.
- The paper demonstrates that ExpertPrompting significantly outperforms traditional vanilla prompting techniques, as validated by GPT-4 based evaluations and benchmark comparisons.
- The paper shows that the approach minimizes manual effort while scaling effectively across diverse tasks, paving the way for more robust and context-aware AI systems.
ExpertPrompting: Instructing LLMs to be Distinguished Experts
Introduction
The paper "ExpertPrompting: Instructing LLMs to be Distinguished Experts" proposes a novel method for enhancing the response quality of LLMs by crafting context-specific expert identities during the prompting process. This approach is designed to invoke the latent potential of LLMs to simulate expert agents and provide superior answers tailored to specific queries.
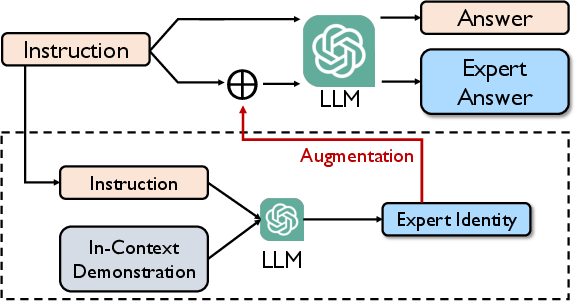
Figure 1: ExpertPrompting framework.
LLMs, such as GPT-3.5, benefit substantially from the power of well-engineered prompts. Prior research has shown various strategies for enhancing LLM performance, often requiring complex reasoning or iterative methods. However, these methods frequently lack general applicability across diverse tasks. ExpertPrompting addresses these limitations by automatically generating expert identities through In-Context Learning, offering a scalable solution to improve responses across a wide range of domains.
Methodology
Framework Overview
ExpertPrompting is characterized by its automatic generation of expert identities based on specific instructions, followed by the elicitation of responses from LLMs conditioned on these identities. The method involves two primary steps:
- Generation of Expert Identity: Utilizing In-Context Learning, the framework drafts detailed and customized expert identities for each instruction. These identities are crafted to be informative, distinguished, and automatic, ensuring that the LLM receives a comprehensive background context for generating responses.
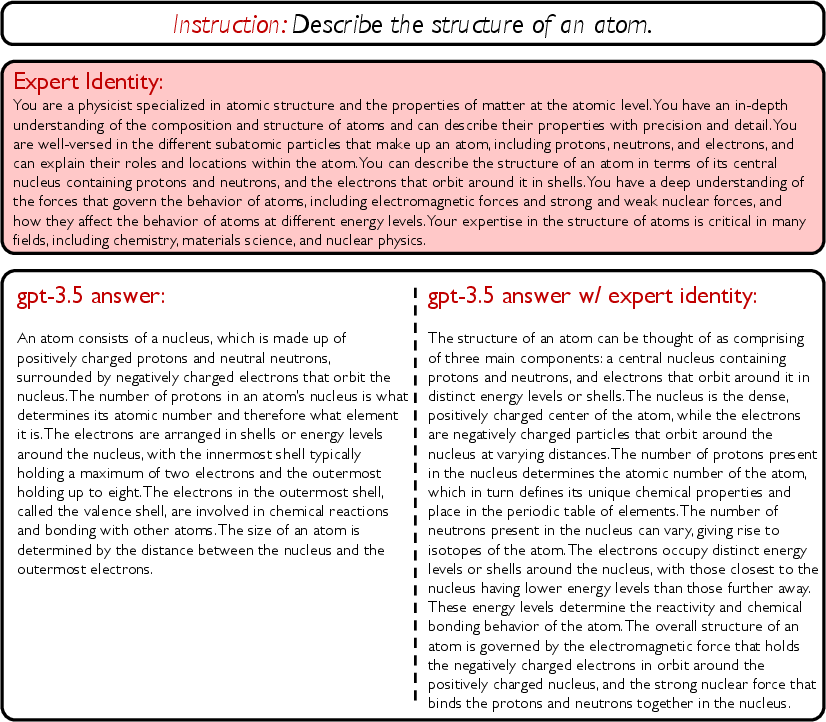
Figure 2: Effects of expert identity augmentation when prompting gpt-3.5-turbo.
- Prompting with Expert Identity: Once an expert identity is established, the LLM leverages this context to produce enhanced responses. The expert identity effectively guides the LLM's decision-making process, facilitating more coherent and expert-like answer generation.
Implementation
The implementation of ExpertPrompting involves minimal manual effort. Initial expert identity descriptions for a few sample instructions are manually created and used as exemplars in a prompt, guiding In-Context Learning to generate identities for other instructions automatically. This automated approach contrasts with conventional manual prompt crafting, offering efficiency and scalability.
Results and Evaluation
The validity of ExpertPrompting is assessed using GPT4-based automatic evaluation, providing empirical evidence for the enhanced quality of responses compared to traditional methods. Evaluation of the produced data and trained models shows that ExpertPrompting generates significantly higher quality answers than vanilla prompting techniques.
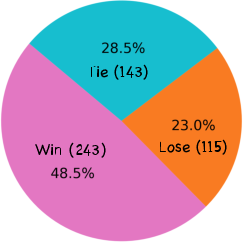
Figure 3: Comparison of answer quality (ExpertPrompting VS Vanilla Prompting). Evaluated by GPT4.
An illustrative model, ExpertLLaMA, is trained on the expert data generated using ExpertPrompting. The model exhibits superior performance across various benchmarks, approaching the capability level of the original ChatGPT, and notably outperforming other open-source chat assistants such as Vicuna and Alpaca.
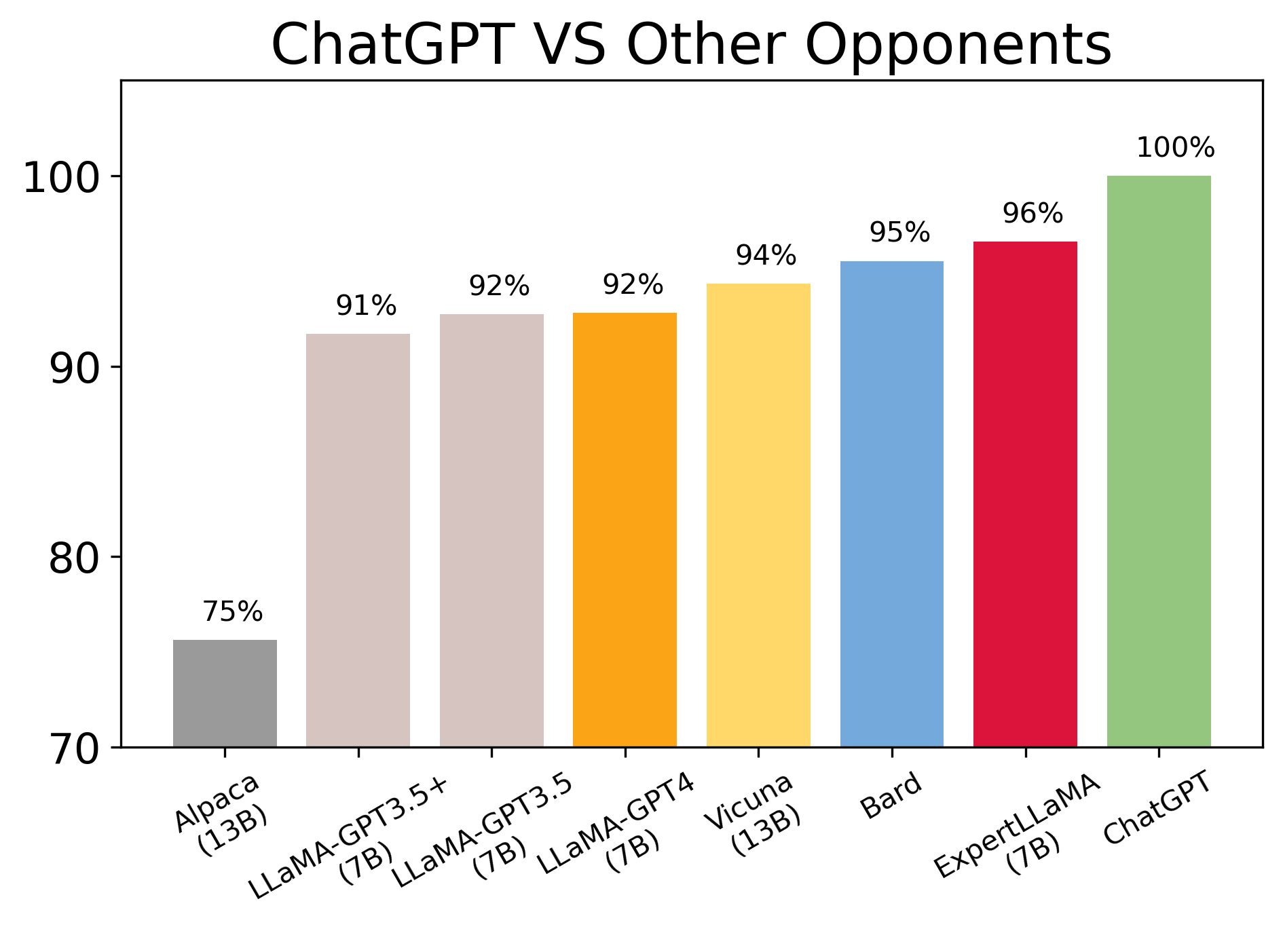
Figure 4: Comparison of popular chat assistants. Scores are aligned to ChatGPT as 100\%.
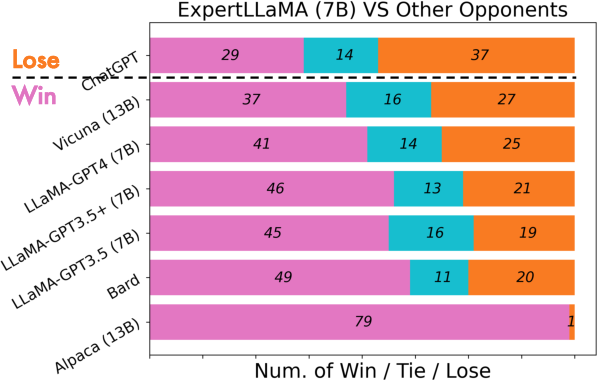
Figure 5: Comparison of popular chat assistants. Number of win, tie and losses are counted.
Implications and Future Directions
The introduction of ExpertPrompting signifies a practical advancement in the field of prompting strategies for LLMs. By systematically enhancing the precision and context of prompts, it paves the way for developing more reliable and contextually aware AI systems. The implications for future research include exploring the scalability of ExpertPrompting to larger datasets and further validating its efficacy across varied LLMs and instructions.
Given the proven efficacy of ExpertPrompting in producing high-caliber responses, future work could explore adaptive mechanisms to refine expert identities dynamically or extend the approach to different modalities and multilingual contexts. Moreover, the integration of this method into existing AI-based assistant platforms could potentially revolutionize conversational AI by enabling contextually robust interactions.
Conclusion
ExpertPrompting represents a methodological leap in prompting practices for LLMs, demonstrating significant improvements in answer quality and model efficacy through automated expert identity generation. This approach not only enhances the instructional alignment of LLMs but also contributes to the development of competitive models like ExpertLLaMA, capable of substantial performance improvements over existing solutions. Continued exploration and expansion of ExpertPrompting offer promising avenues for advancing AI capabilities and applications in diverse domains.