- The paper establishes that adaptive prompting strategies improve robustness and factual accuracy across diverse multimodal tasks.
- The paper evaluates seven prompting methods on 13 models with varying scales from small (<4B) to large (>10B) using tasks in reasoning and code generation.
- The paper demonstrates that Few-Shot prompting can achieve up to 96.88% accuracy for structured tasks, illustrating effective trade-offs in prompt engineering.
Introduction
The integration of multimodal inputs within LLMs has led to the evolution of Multimodal LLMs (MLLMs), enabling sophisticated multimodal reasoning abilities. While traditional LLMs have primarily focused on text-based data, MLLMs absorb a variety of inputs, such as text, images, and potentially audio, expanding their application range significantly. Effective utilization of these models is highly contingent upon the implementation of prompt engineering techniques. This paper presents an evaluation of seven distinct prompt methodologies applied across 13 open-source MLLMs, meticulously categorizing results by parameter count (Small <4B, Medium 4B–10B, and Large >10B) and employing tasks across reasoning, compositionality, and more.
MLLM Architecture and Applications
MLLM architectures inherently require more complex integration than traditional LLMs due to the diverse data types they process. The typical MLLM includes modality encoders, transformation layers, and an LLM backbone, tasked with merging encoded features into coherent outputs.
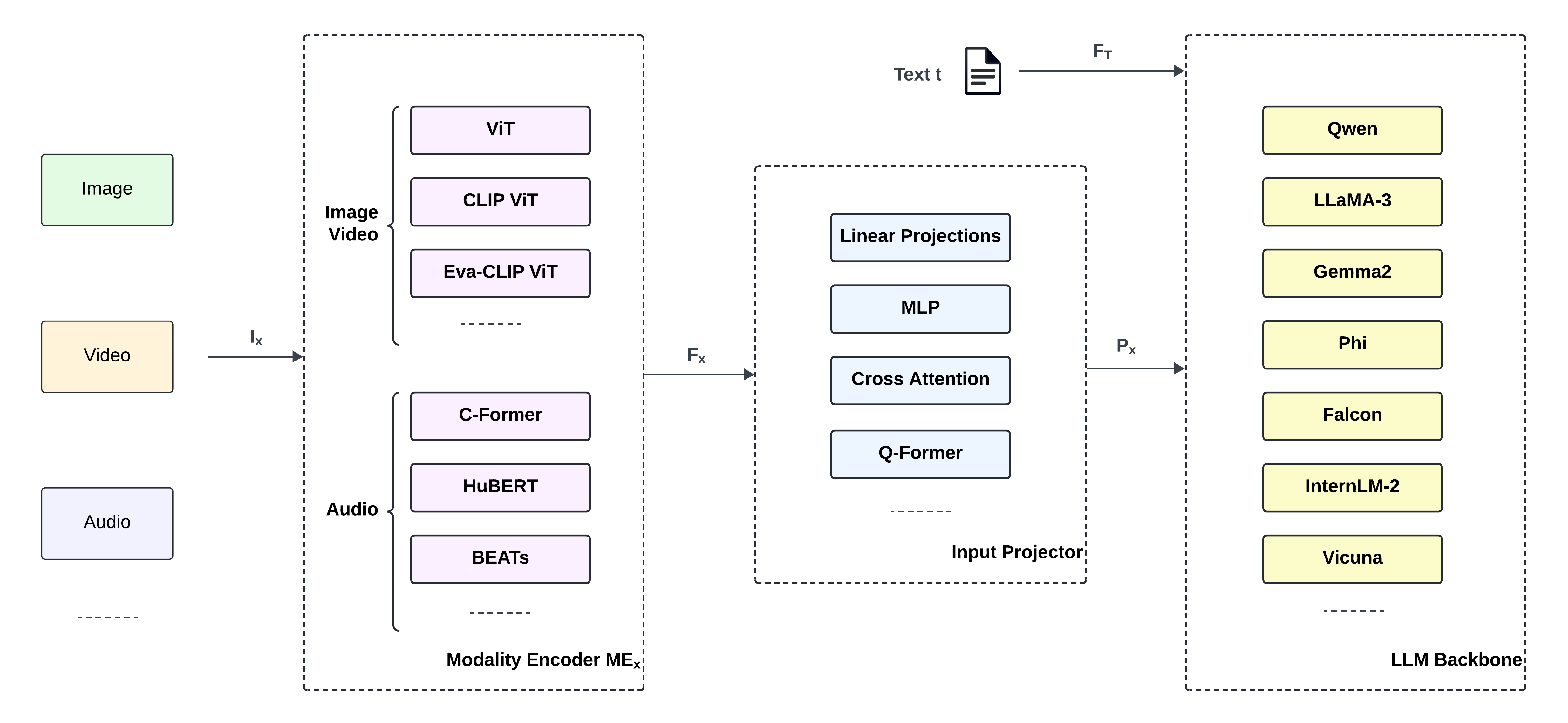
Figure 1: A high-level overview of a typical MLLM pipeline. Multiple input modalities are first processed by dedicated encoders, followed by feature transformation and finalized by a backbone integrating these multimodal features.
Notably, this paper highlights the rapid development of MLLMs that specialize in integrating multiple modalities, with specific architectures like ViT and CLIP playing key roles in feature extraction. Current proprietary and open-source models exhibit vast differences in flexibility, scalability, and performance across diverse tasks, demonstrating varying levels of instruction-following abilities.
Methods
The researchers implemented a multi-staged framework to evaluate the impact of prompt engineering techniques on various task performances, using different metrics related to task dimensions and model scales. The experimental setup comprised of the following stages:
- Defining Core Evaluation Aspects: Four key dimensions were selected, spanning reasoning and compositionality to multimodal understanding and complex code generation.
- Model Selection: Thirteen open-source MLLM models were chosen, representing a diverse set of architectural designs and parameter scales.
- Prompt Engineering Methods: Seven prompting methods—including Zero-Shot, One-Shot, Few-Shot, and Chain-of-Thought—were rigorously applied.
- Evaluation Framework: Implementation considerations focused on task efficacy and computational resource management, with careful attention given to reducing hallucination rates and improving factual accuracy.
Results
The paper showcases distinct outcomes for each model category and prompting method, highlighting trade-offs between computational efficiency and output quality. Large models frequently excelled in structured tasks such as code generation, achieving up to 96.88% accuracy with Few-Shot prompting. Conversely, tasks requiring complex reasoning demonstrated notable challenges, with hallucination rates as high as 75% in smaller models during structured reasoning prompts (e.g., Tree-of-Thought).
Discussion
Adaptive prompting strategies were highlighted as necessary, given that no single method uniformly optimized all task types. Instead, strategies that combine example-based approaches with selective structured reasoning significantly enhance performance reliability and accuracy. This reflects the theoretical and practical implications of the research, positioning adaptive strategies as superior for deploying MLLMs in real-world applications like AI-assisted coding or knowledge retrieval.
Conclusion
The study represents a comprehensive evaluation across diverse MLLM architectures and task types, underscoring the intricate balance required in prompt engineering to optimize model performance. Fueled by adaptive strategies, MLLMs promise improved robustness and factual accuracy, bolstering their potential for real-world application across various domains. Future work will likely elaborate on these strategies, aiming to push the boundaries of MLLM capabilities further.

