- The paper shows that variations in prompt design significantly affect LLM compliance and accuracy across multiple CSS tasks.
- The study employs a multifactorial experiment with three LLMs and four CSS tasks, revealing notable discrepancies in model performance.
- The findings highlight that concise prompts save costs while explanations and definitions can shift label distributions, necessitating careful prompt configuration.
Introduction
The research presented in "Prompt Design Matters for Computational Social Science Tasks but in Unpredictable Ways" focuses on understanding the influence of prompt design on LLMs tasked with data annotation in computational social science (CSS). This paper systematically investigates how variations in prompt design—specifically, definition inclusion, output type, explanation provisioning, and prompt length—affect LLM compliance and accuracy across multiple CSS tasks.
Methodology
The experiment employed three LLMs—ChatGPT, PaLM2, and Falcon7b—executed over four diverse CSS tasks: toxicity detection, sentiment analysis, rumor stance identification, and news frame classification. A multifactorial framework was applied, generating 16 prompt variations to encompass different permutations of the prompt design dimensions (Figure 1).
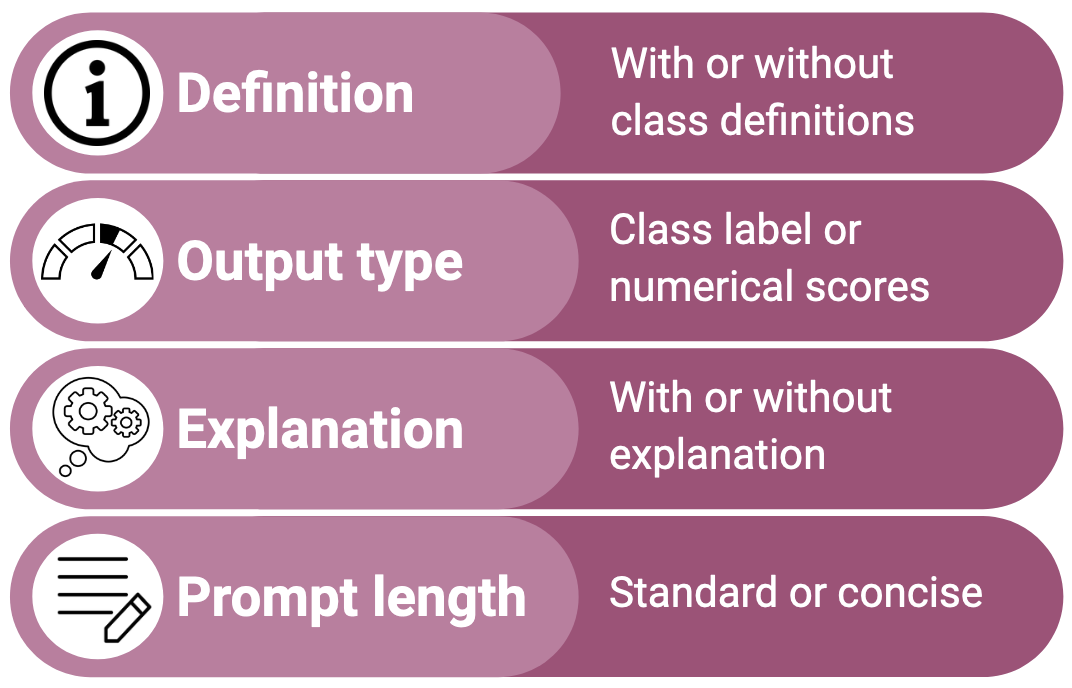
Figure 1: Prompt variations used in our experiments.
The authors utilized datasets typical in CSS research, such as SST5 for sentiment analysis and HOT for toxicity, aiming to characterize the performance metrics—compliance and accuracy—of LLMs under varied prompt conditions.
Key Findings
Compliance and Accuracy Variability
Significant discrepancies in compliance and accuracy were observed across LLMs and prompt designs. Falcon7b showed compliance variations up to 55% on rumor stance tasks, while ChatGPT's accuracy varied by up to 14% across news framing prompts. Notably, numerical output requests degraded both compliance and accuracy. However, providing definitions improved ChatGPT's accuracy while negatively impacting PaLM2 and Falcon7b compliance.
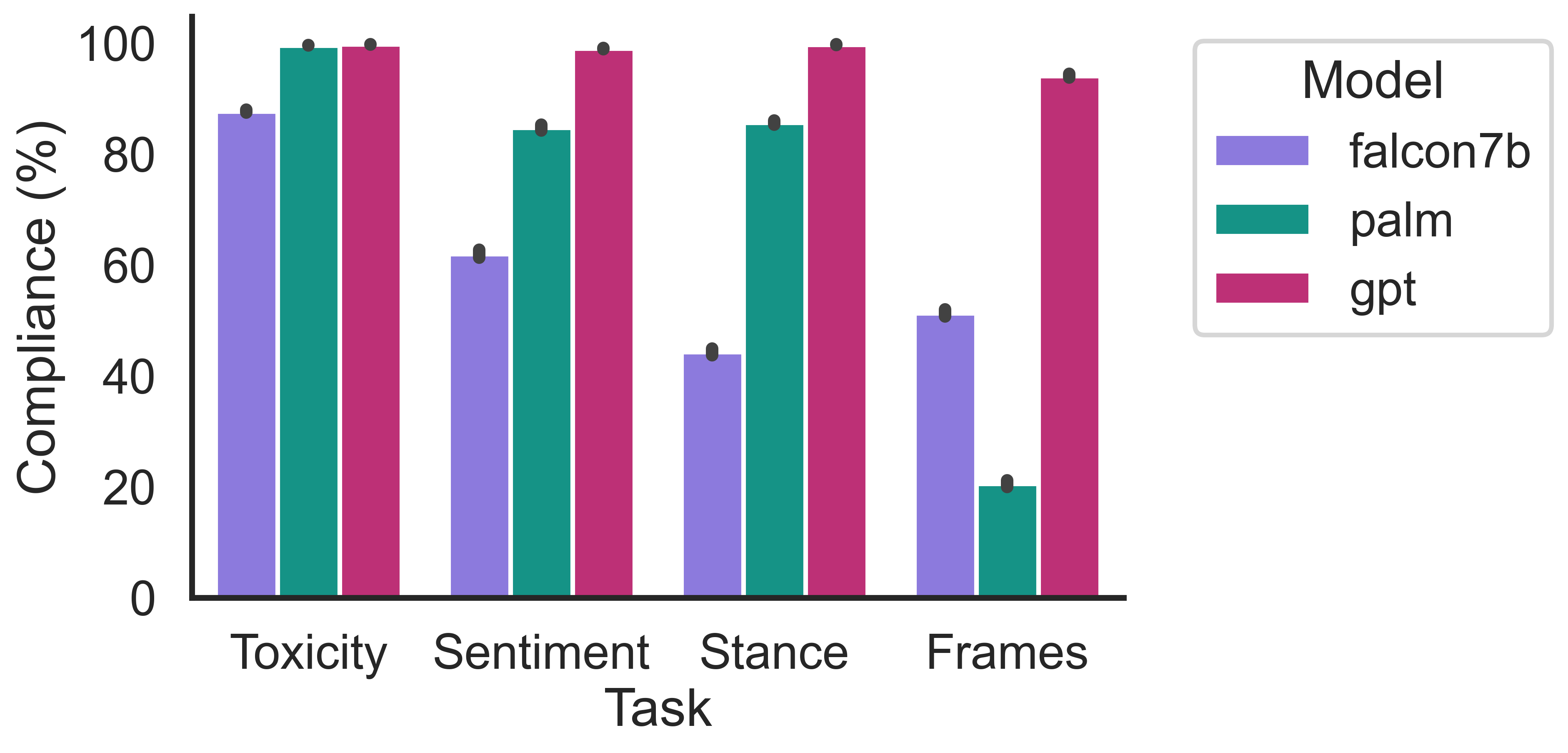
Figure 2: Percentage compliance for different tasks and LLMs.
Explanation and Distribution Shifts
While explanations increased compliance, they also altered label distributions significantly, exemplified by ChatGPT annotating 34% more content as neutral when explanations were requested, which can bias research conclusions.

Figure 3: Examples demonstrating LLM noncompliance.
Cost-Effectiveness and Prompt Length
Concise prompts, while reducing input token costs, impacted compliance inconsistently. ChatGPT maintained compliance with concise prompts, offering a cost advantage, contrasting with other models that showed declines in compliance or accuracy.

Figure 4: Falcon7b's response on the same data when prompted with/without explanation.
Discussion
This study illustrates the complex influence of prompt design on LLM performance for CSS tasks, emphasizing the need for careful prompt selection based on task specificity and underlying model characteristics. The findings suggest that researchers should tailor prompts to balance between cost and annotation quality, using empirical evidence as guidance rather than relying solely on conventional best practices.
Understanding these variables is vital, particularly within fields where LLM-driven annotations impact social science research outcomes, potentially affecting public policy or societal interpretations.
Conclusion
The research provides critical insights into configuring LLM prompts for optimal performance in CSS applications. The variability and unpredictability observed necessitate adaptive strategies, where multiple prompt configurations may enhance robustness and reliability in annotated datasets. Future work could explore alternative prompting methods more suited to varying model capabilities and task complexities, advancing the integration of LLMs in CSS research.

