A Survey on Diffusion Language Models
Abstract: Diffusion LLMs (DLMs) are rapidly emerging as a powerful and promising alternative to the dominant autoregressive (AR) paradigm. By generating tokens in parallel through an iterative denoising process, DLMs possess inherent advantages in reducing inference latency and capturing bidirectional context, thereby enabling fine-grained control over the generation process. While achieving a several-fold speed-up, recent advancements have allowed DLMs to show performance comparable to their autoregressive counterparts, making them a compelling choice for various natural language processing tasks. In this survey, we provide a holistic overview of the current DLM landscape. We trace its evolution and relationship with other paradigms, such as autoregressive and masked LLMs, and cover both foundational principles and state-of-the-art models. Our work offers an up-to-date, comprehensive taxonomy and an in-depth analysis of current techniques, from pre-training strategies to advanced post-training methods. Another contribution of this survey is a thorough review of DLM inference strategies and optimizations, including improvements in decoding parallelism, caching mechanisms, and generation quality. We also highlight the latest approaches to multimodal extensions of DLMs and delineate their applications across various practical scenarios. Furthermore, our discussion addresses the limitations and challenges of DLMs, including efficiency, long-sequence handling, and infrastructure requirements, while outlining future research directions to sustain progress in this rapidly evolving field. Project GitHub is available at https://github.com/VILA-Lab/Awesome-DLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is a survey, which means it reviews and explains a whole field rather than presenting just one new model. It focuses on Diffusion LLMs (DLMs) — a newer way to make AI write text. Unlike the usual “one word at a time” approach, DLMs create many words in parallel by starting with a messy version of a sentence and cleaning it up step by step. The authors explain how DLMs work, how they’re trained, how they’re used, what makes them fast and controllable, and where they still struggle.
What questions does it try to answer?
To make the topic easy to follow, the paper looks at several simple questions:
- How do DLMs compare to older styles like autoregressive (AR) models (which generate one token at a time) and masked LLMs (which guess missing words)?
- What kinds of DLMs exist, and how are they built? (For example, some work with numbers behind the scenes, others work directly with words.)
- How are DLMs trained and sped up to be practical?
- How well do DLMs perform now, and what can they be used for (text, code, even combining text with images)?
- What are the current challenges and what should researchers work on next?
How did the authors study it?
This is a structured review of the field. Here’s the approach in everyday language:
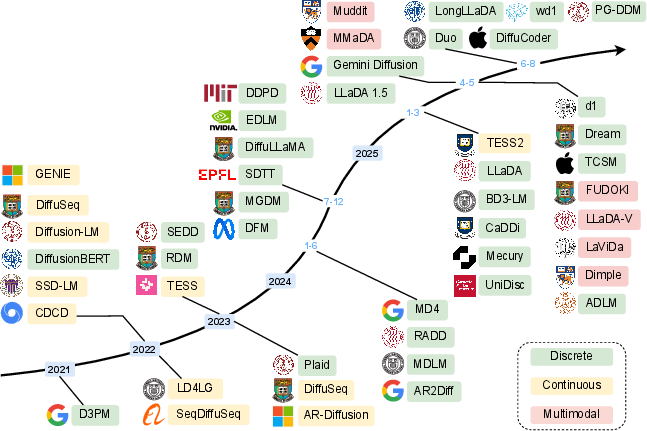
- They map the big picture: The authors organize DLMs into a “taxonomy” (a family tree of methods), charting how the ideas evolved over time, and how DLMs relate to AR models (like GPT) and masked models (like BERT).
- They explain two main flavors of DLMs:
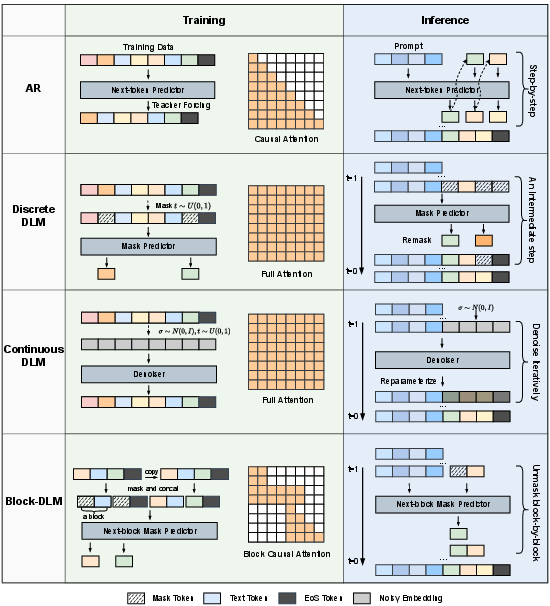
- Continuous DLMs: These turn words into vectors (lists of numbers called embeddings) and “add noise” (like static on a radio) to them. The model learns to remove the noise in steps, ending with clean text.
- Discrete DLMs: These work directly with tokens (words/pieces of words). They often use a special [MASK] token and learn to fill in the blanks, unmasking the most confident words over several rounds.
- They describe training and tuning: How models are trained from scratch, or adapted from existing models (for example, taking a GPT-like model and teaching it to do diffusion), then fine-tuned with supervised examples or improved with reinforcement learning to follow instructions and reason better.
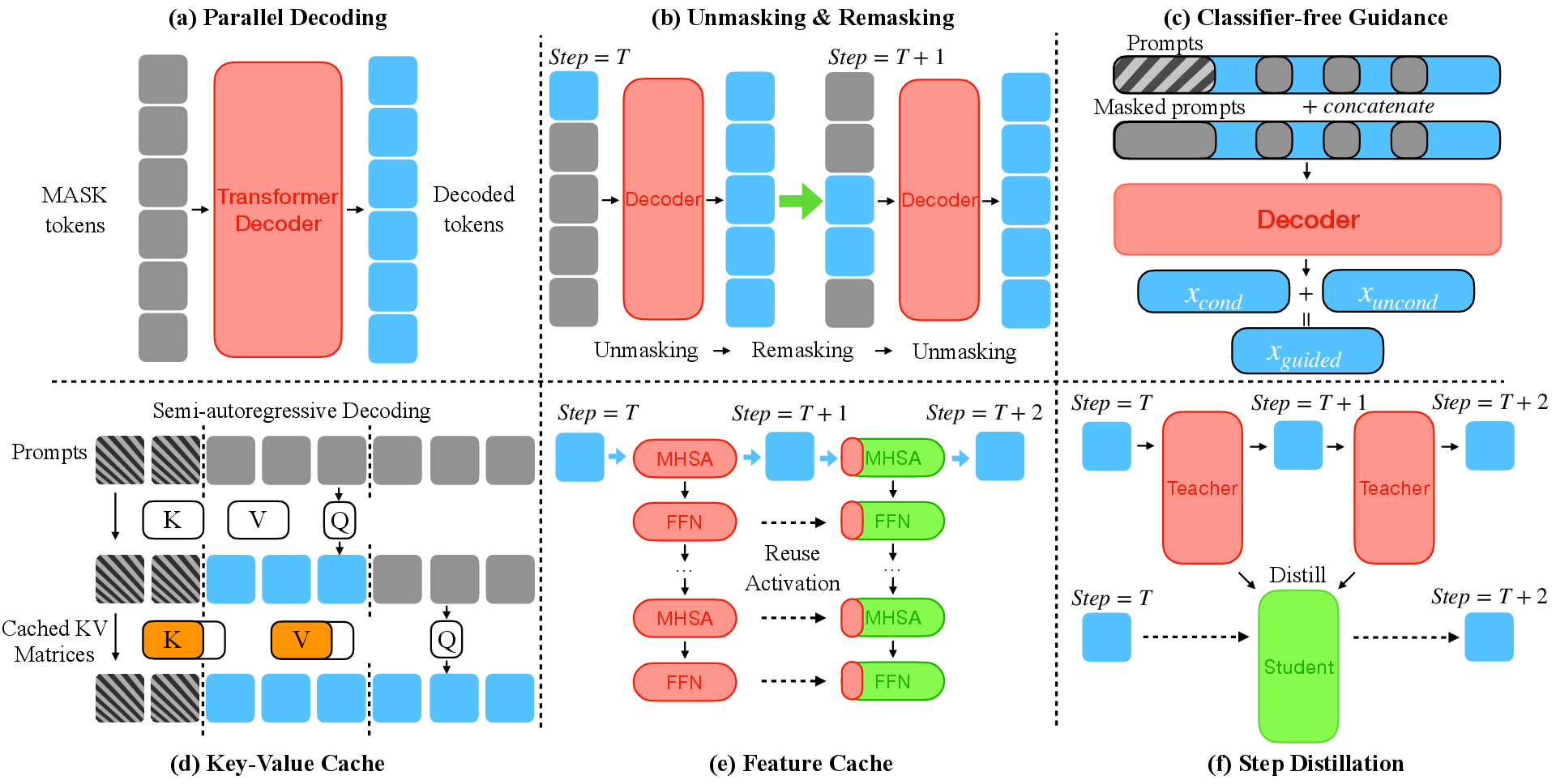
- They cover speed-up tricks for generation (inference):
- Parallel decoding (accept several tokens at once).
- Unmasking/remasking (reveal confident words, keep uncertain parts hidden, then try again).
- Caching (save earlier computations so you don’t redo them).
- Guidance (steer the style or correctness of the output).
- Few-step samplers and distillation (generate high quality text with fewer steps).
- They survey multimodal extensions: Models that use both text and images using the same diffusion idea.
- They summarize applications and limitations across many papers and benchmarks.
Think of it like reviewing many puzzle-solving strategies: AR models fill in the crossword one square at a time from left to right; DLMs fill lots of squares at once, check, then refine the tricky parts over a few rounds.
What did they find, and why does it matter?
Here are the main takeaways, explained simply:
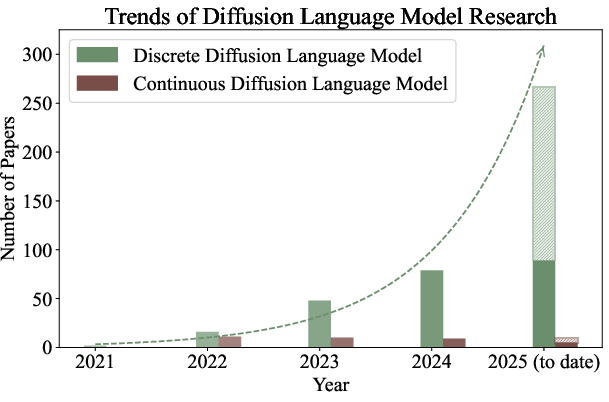
- DLMs can be fast: Because they can generate multiple tokens in parallel, DLMs can be several times faster than the classic “one token at a time” approach. Some industry reports even show thousands of tokens per second.
- They use both left and right context: DLMs naturally look at words before and after a blank. This “bidirectional” view can lead to more coherent and controllable text, especially for tasks like filling gaps or following structure.
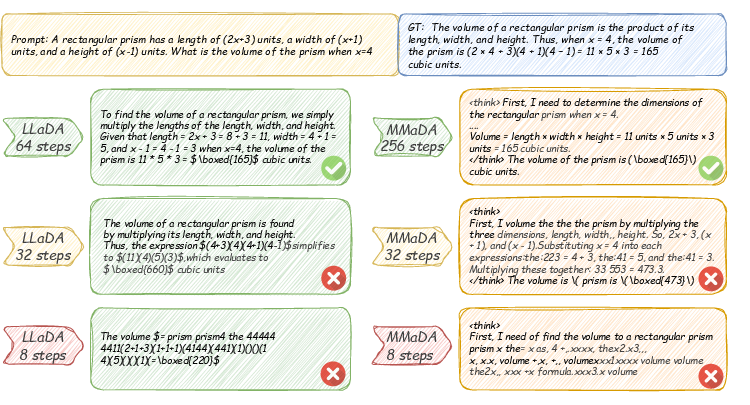
- Iterative refinement helps quality: DLMs don’t have to be perfect in one shot. They guess, lock in the confident parts, and keep improving the uncertain parts. This often produces clearer, more consistent text.
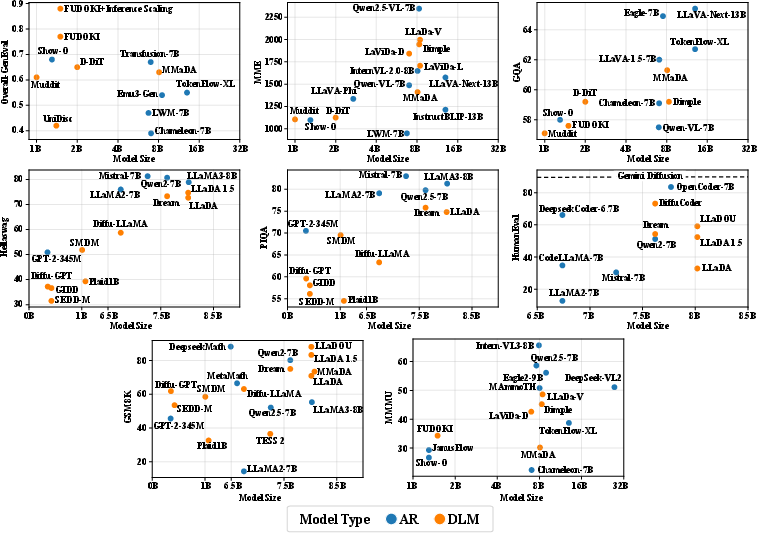
- They are getting competitive with big AR models: Recent large DLMs (like LLaDA-8B, Dream-7B, DiffuLLaMA) are now close to or on par with strong autoregressive models of similar size for many tasks, while offering speed and control advantages.
- They work well beyond plain text: The same diffusion idea that powers image models (like Stable Diffusion) also helps DLMs connect text and images. New “multimodal” DLMs can understand and generate across both.
- Training recipes are maturing: You can train DLMs from scratch, adapt from existing AR models, or even borrow ideas from image diffusion models. Post-training with supervised data and reinforcement learning improves instruction-following and reasoning.
- Practical optimizations matter a lot: Techniques like parallel decoding, smart unmasking/remasking, and caching make a big difference in speed and quality, making DLMs more usable in real systems.
Why it matters: If you want chatbots, code assistants, or multimodal tools that are faster, more controllable, and able to refine their answers, DLMs are a promising path forward.
What challenges remain?
While DLMs are exciting, the survey also highlights hurdles:
- Efficiency and infrastructure: Even with parallelism, DLMs can need careful engineering (special caches, clever schedules) and strong hardware to run at their best.
- Long documents and memory: Handling very long inputs is still hard, though early results (like LongLLaDA) look promising with smart position tricks.
- Reasoning and planning: Getting DLMs to plan multi-step answers (like math proofs or long explanations) is improving but not solved; new training and decoding methods help.
- Generation steps: Diffusion is iterative by nature. Reducing the number of steps without hurting quality is a key goal.
- Dynamic lengths and discrete choices: Working directly with tokens makes some parts (like deciding length or revising past tokens) tricky—new designs are addressing this.
Why does this research matter in the big picture?
- Faster, more responsive AI: DLMs can cut the wait time for text generation, which is crucial for real-time apps (chat, coding, search).
- Better control and editing: Because DLMs refine text in rounds and can “look both ways,” they’re naturally good at filling gaps, editing, and following structure or style.
- One framework for text and images: A shared diffusion idea across text and vision could lead to simpler, more unified AI systems that understand and generate in several modalities.
- New frontiers: The survey points to many applications—writing, coding, information extraction, dialog, and even biology (like designing proteins)—where DLMs are already being tested.
In short, this paper maps the fast-growing world of Diffusion LLMs. It shows that DLMs are moving from a cool idea to practical systems: they’re faster, more flexible, increasingly powerful, and ready to be used alongside (and sometimes instead of) traditional models. The field is advancing quickly, and this survey acts like a guidebook for anyone who wants to understand where DLMs are now and where they’re headed next.
Collections
Sign up for free to add this paper to one or more collections.

