Diffusion Language Models Know the Answer Before Decoding
Abstract: Diffusion LLMs (DLMs) have recently emerged as an alternative to autoregressive approaches, offering parallel sequence generation and flexible token orders. However, their inference remains slower than that of autoregressive models, primarily due to the cost of bidirectional attention and the large number of refinement steps required for high quality outputs. In this work, we highlight and leverage an overlooked property of DLMs early answer convergence: in many cases, the correct answer can be internally identified by half steps before the final decoding step, both under semi-autoregressive and random remasking schedules. For example, on GSM8K and MMLU, up to 97% and 99% of instances, respectively, can be decoded correctly using only half of the refinement steps. Building on this observation, we introduce Prophet, a training-free fast decoding paradigm that enables early commit decoding. Specifically, Prophet dynamically decides whether to continue refinement or to go "all-in" (i.e., decode all remaining tokens in one step), using the confidence gap between the top-2 prediction candidates as the criterion. It integrates seamlessly into existing DLM implementations, incurs negligible overhead, and requires no additional training. Empirical evaluations of LLaDA-8B and Dream-7B across multiple tasks show that Prophet reduces the number of decoding steps by up to 3.4x while preserving high generation quality. These results recast DLM decoding as a problem of when to stop sampling, and demonstrate that early decode convergence provides a simple yet powerful mechanism for accelerating DLM inference, complementary to existing speedup techniques. Our code is publicly available at https://github.com/pixeli99/Prophet.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper studies a new kind of text-generating AI called diffusion LLMs (DLMs). The authors notice something surprising: these models often “figure out” the right answer early, before they finish all their usual steps. They then propose a simple way, called Prophet, to stop early and output the answer sooner—making the model much faster without hurting accuracy.
The main questions the paper asks
- Do diffusion LLMs usually know the correct answer before they finish decoding?
- If yes, can we safely stop early and still get the right answer?
- Can we do this without retraining the model, and will it actually speed things up in practice?
How diffusion LLMs work (in simple terms)
Think of writing a sentence like filling in a jigsaw puzzle:
- Autoregressive models (the common kind) place pieces one by one, left to right.
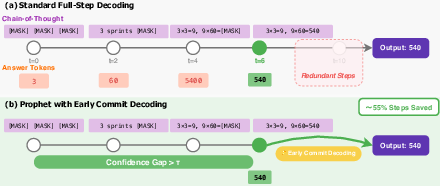
- Diffusion LLMs place and refine many pieces at the same time. They start with a sentence full of “blanks” (masked tokens), then repeatedly guess the missing pieces, keep the confident ones, and try again for the rest. Each “try again” is called a refinement step.
This parallel approach is flexible, but it can be slow because:
- The model looks both left and right (bidirectional), which makes caching tricks harder.
- It usually needs many refinement steps to get very high-quality text.
A key observation: early answer convergence
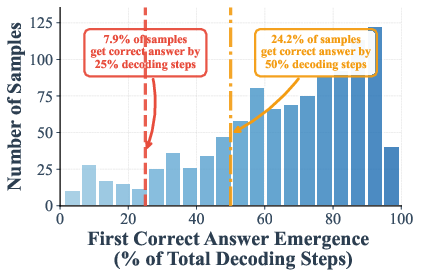
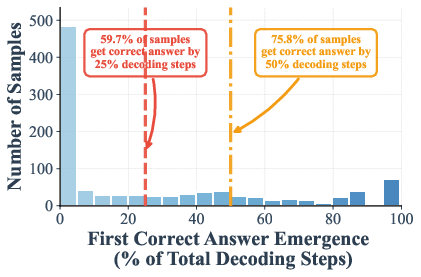
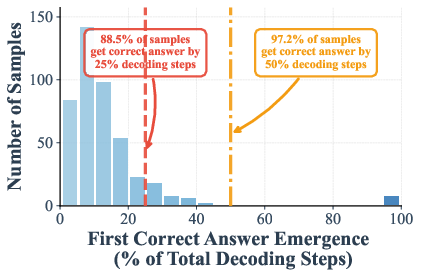
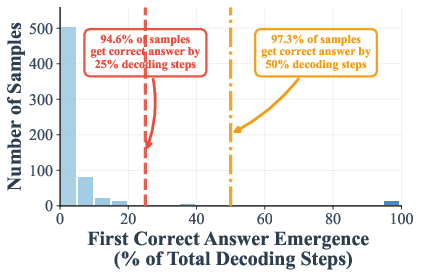
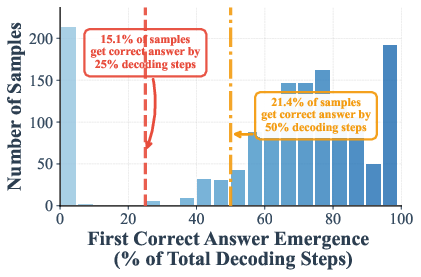
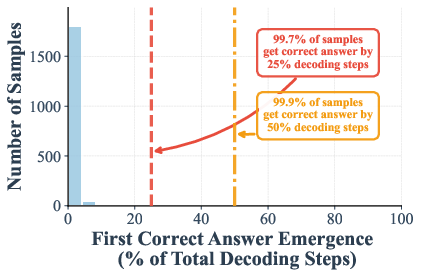
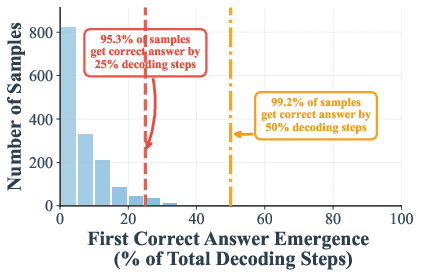
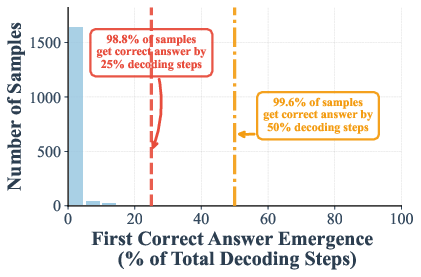
The authors measured when the correct answer shows up during these steps. On math and knowledge tests (GSM8K and MMLU), they found that in many cases the right answer appears—and stays stable—by halfway through the steps. In some settings:
- Up to 97% (GSM8K) and 99% (MMLU) of examples are already correct at just half the steps.
- Adding a simple suffix prompt like “Answer:” helps the model settle even earlier.
The Prophet idea (how they speed things up)
Prophet is a training-free add-on that watches the model’s confidence as it refines. It uses a very simple signal:
- At each position (each word/token), the model has a top choice and a second choice.
- The difference between them (the “confidence gap”) tells how sure the model is.
- When the average gap is big enough, Prophet “goes all-in”: it fills in all remaining blanks at once and stops.
To lower risk, Prophet is stricter early on (it requires a larger gap to stop) and more relaxed later (a smaller gap is enough), since by then the model’s guesses have stabilized.
What the researchers did (methods, in everyday terms)
- They tested two strong diffusion LLMs (LLaDA-8B and Dream-7B) on a mix of benchmarks:
- General knowledge and reasoning (like MMLU, HellaSwag)
- Math and science (GSM8K, GPQA)
- Logic/planning puzzles (Sudoku, Countdown)
- They compared three decoding strategies:
- Full: use all steps (the slow baseline).
- Half: always use half the steps (a simple but risky shortcut).
- Prophet: stop early only when confidence says it’s safe, and then fill in everything.
- They also studied how adding “Answer:” to the prompt affects how quickly answers stabilize (it helps a lot).
Analogy: Imagine spelling a word with fading hints. If your top guess is “CAT” and the second guess is “CAR,” the gap between CAT and CAR tells how confident you are. If the gap is large across the whole answer, you probably don’t need more hints—you can lock it in.
What they found and why it matters
- Early correctness is common: the right answer often appears well before the last step and doesn’t change afterwards.
- Prophet makes models much faster: up to 3.4× fewer decoding steps, typically around 1.7–2.6× speed-ups across tasks.
- Quality is preserved: accuracy stays almost the same as the full (slow) method, and sometimes even improves because the model avoids “overthinking” and changing a correct answer late in the process.
- It’s easy to use: no extra training, tiny overhead, and it plugs into existing diffusion LLM code.
Example results:
- On HellaSwag (commonsense reasoning), Prophet slightly improved accuracy while running faster.
- On GSM8K (math), accuracy stayed almost unchanged while speeding up.
- On GPQA (science Q&A), the “half steps” shortcut lost accuracy, but Prophet matched or beat the full method—showing it’s a safer way to accelerate.
What this could change
- Faster AI responses: By stopping as soon as the answer stabilizes, DLMs become more practical for apps that need quick replies.
- Lower costs and energy use: Fewer steps mean less compute and power.
- Works with other speedups: Prophet complements caching and other optimization tricks; it’s about knowing when to stop, not how to compute each step.
- A new mindset: Instead of always running a fixed number of steps, treat decoding as “stop when you’re sure.” This could inspire better, smarter decoders in the future.
One-sentence takeaway
Diffusion LLMs often know the right answer early; Prophet notices that confidence and ends decoding sooner, making generation much faster while keeping answers correct.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, formulated to guide actionable future work.
- Calibration and universality of the confidence-gap criterion
- Lack of analysis on whether the top-2 logit margin is calibrated across models, datasets, and decoding temperatures; margin values are not temperature-invariant and may be incomparable across steps.
- No theoretical link between gap magnitude and error probability; no guarantees on risk vs. speed trade-offs (e.g., PAC-style bounds or conformal thresholds).
- Threshold design and sensitivity
- The staged thresholds (τhigh, τmid, τlow) and progress cut points are hand-tuned; no systematic sensitivity analysis, per-task adaptation, or learning-based policy (e.g., bandits/RL/meta-learning).
- No ablations comparing different aggregation rules for multi-token decisions (average vs. min/quantile/variance of gaps), which could greatly affect premature commits.
- Dependence on knowing the “answer region” A
- Prophet assumes known answer-token positions; generalization to free-form generations where answer spans are not explicitly delimited is unclear.
- Reliance on suffix prompting (“Answer:”) to define A raises questions about applicability to tasks without such constrained formatting and to multi-turn/dialogue settings.
- Scope of evaluation and generalization
- Evaluated only on 7B–8B DLMs; scalability to larger models (e.g., 30B–70B+) and to smaller models is untested.
- Tasks are primarily English, short-form, and benchmark-style; open-ended, long-form, multilingual, and code generation scenarios (with sampling) are not evaluated.
- Results are reported under greedy decoding; impact under stochastic decoding (temperature, nucleus) remains unknown, as sampling alters the relevance of argmax-based gaps.
- Metrics and speed claims
- Speedups reported in “step count” rather than wall-clock latency, throughput, or energy metrics; no hardware-level profiling or memory/batch-size sensitivity to validate practical gains.
- The overhead of computing top-2 margins (and any additional masking bookkeeping) is claimed negligible but not quantified on real systems.
- Baselines and integration with existing accelerations
- Missing comparisons with stronger dynamic early-exit baselines (e.g., entropy thresholds, confidence-based token gating used in prior DLM works, or time-ensemble methods from concurrent work).
- No experiments on compatibility and cumulative gains when Prophet is combined with KV-cache methods, semi-/block-autoregressive restructuring, or speculative decoding.
- Early answer convergence analysis bias
- The “early emergence” statistics condition on instances where the final output is correct, potentially inflating early convergence rates; no analysis of false-commit risk on ultimately incorrect samples.
- No precision–recall or ROC analysis of the stopping rule to quantify trade-offs between early gains and miscommit errors.
- Failure modes and safety mechanisms
- No characterization of worst-case behaviors where early commit locks in erroneous outputs; absence of rollback/verification or abstention mechanisms (e.g., verifier-guided stopping).
- Lack of robustness tests to adversarial prompts, distribution shift, or noisy inputs that could miscalibrate confidence gaps.
- Interaction with chain-of-thought and structured outputs
- The method computes the stop signal on answer tokens but commits “all remaining tokens”; risks to rationale/format stability are not analyzed (e.g., degraded CoT quality or formatting errors).
- No evaluation on constrained decoding or structured output tasks (e.g., JSON, code, formal languages) where premature finalization can violate constraints.
- Remasking schedules and dynamics
- While observations cover low-confidence and random remasking, Prophet’s robustness across other schedules (semi-/block-AR, guided diffusion, cache-refreshing) is not systematically studied.
- No exploration of token-wise early commit (finalizing only stabilized tokens) versus the paper’s “go all-in” policy, which may be unnecessarily risky.
- Theoretical understanding of early convergence
- The paper frames decoding as optimal stopping but does not derive an optimal policy or analyze diffusion time-dynamics explaining why/when answers stabilize.
- Missing analysis of token-wise temporal stability distributions and their predictive power for correctness across tasks.
- Length handling and termination
- Prophet assumes a pre-specified generation length; handling of variable-length outputs and early length termination criteria is not addressed.
- Sensitivity to mis-specified “Answer length” and “Block length” hyperparameters is not studied.
- Statistical rigor and reproducibility
- No confidence intervals or significance tests for small performance differences; unclear if reported improvements are statistically robust.
- Code availability is stated, but reproducibility details (seeds, exact datasets/splits, hardware) and ablation scripts are not fully described in the main text.
- Broader impacts and fairness
- No analysis of whether early stopping disproportionately affects minority-language, domain-specific, or atypical inputs due to calibration shifts.
- No study of hallucination rates or factuality trade-offs when committing early.
- Extensions and open design questions
- Could a learned or verifier-guided stopping policy outperform fixed thresholds while preserving guarantees?
- Can time-ensemble predictions (from concurrent work) be fused with early commit for both accuracy and speed?
- Is it beneficial to regularize training for better temporal calibration (e.g., margin shaping) to increase safe early commits?
Collections
Sign up for free to add this paper to one or more collections.