- The paper introduces DiffuCoder, a masked diffusion model trained on 130B tokens that significantly improves code generation accuracy.
- It employs a novel reinforcement learning technique, coupled-GRPO, to reduce variance in token log-likelihood estimation during decoding.
- Results indicate that higher sampling temperatures diversify token choices and adjust generation order, offering enhanced model flexibility.
DiffuCoder: Understanding and Improving Masked Diffusion Models for Code Generation
Introduction
"DiffuCoder: Understanding and Improving Masked Diffusion Models for Code Generation" explores the use of masked diffusion models for code generation tasks. It investigates the decoding behavior of diffusion LLMs (dLLMs) and introduces DiffuCoder, a model trained on 130B tokens of code. The central focus is on the differences between dLLMs and autoregressive (AR) models, specifically in terms of decoding sequence flexibility, sampling temperature effects, and reinforcement learning (RL) methodologies, notably coupled-GRPO.
Masked Diffusion Models for Code
dLLMs offer a compelling alternative to AR models by leveraging global planning and iterative sequence refinement capabilities, which align well with the iterative nature of code development. The study reveals that dLLMs can adjust the causality of token generation, diverging from the AR paradigm of strict left-to-right generation. Figure 1 demonstrates an example of DiffuCoder-Instruct's decoding process and the impact of different sampling strategies on model performance.
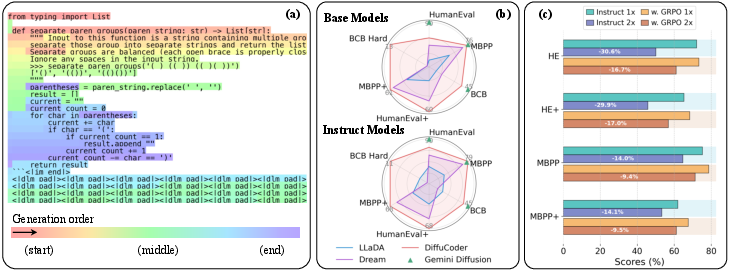
Figure 1: A real example of DiffuCoder-Instruct's decoding process with sampling temperature 1.2.
Training and Decoding Analysis
DiffuCoder employs a multi-stage training pipeline, depicted in Figure 2, including adaptation pre-training, mid-training, instruction tuning, and a novel RL post-training stage using coupled-GRPO. This method aims to enhance performance by maintaining efficiency in Monte Carlo estimations and reducing variance through coupled sampling mechanisms.

Figure 2: Pipeline of DiffuCoder training stages and an illustration of the coupled-GRPO algorithm.
Coupled-GRPO offers a variance-reduced approach for estimating token log-likelihoods. The analysis shows that dLLMs exhibit both local and global AR-ness across different data modalities and stages of training, as illustrated in Figure 3. Local AR-ness reflects consecutive next-token predictions, whereas global AR-ness assesses the order of unmasking positions.
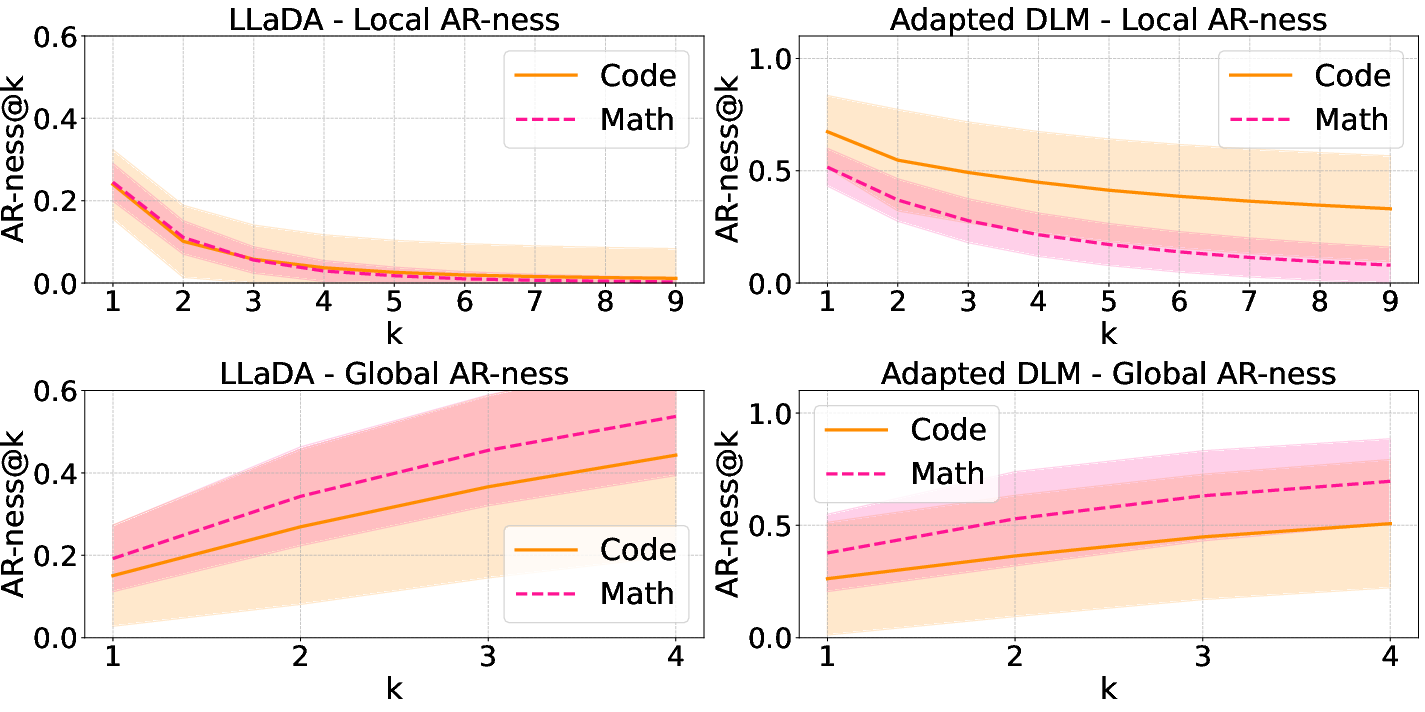
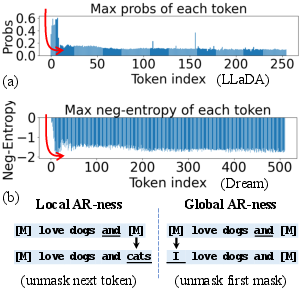
Figure 3: Local and global AR-ness across different models and data modalities.
Reinforcement Learning with Diffusion Models
The study extends reinforcement learning applications to dLLMs by integrating GRPO tailored for diffusion models. The coupled-GRPO method introduces a novel sampling scheme, creating paired complementary mask noise during training, significantly improving performance on benchmarks such as EvalPlus. Figure 4 showcases the reward curves during GRPO training, highlighting the effectiveness of coupled-GRPO compared to baseline methods.
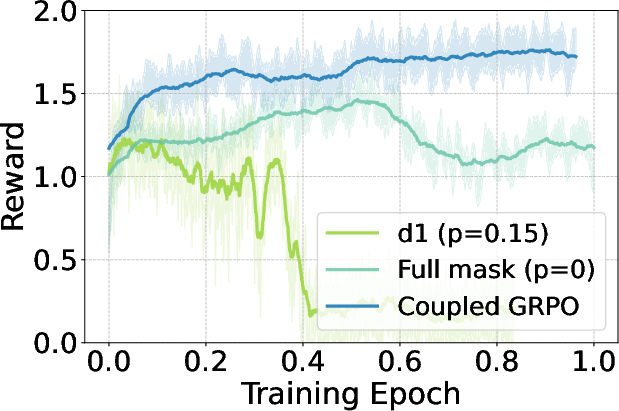
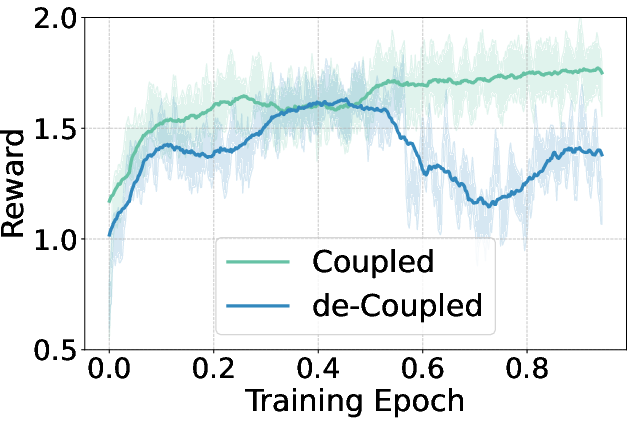
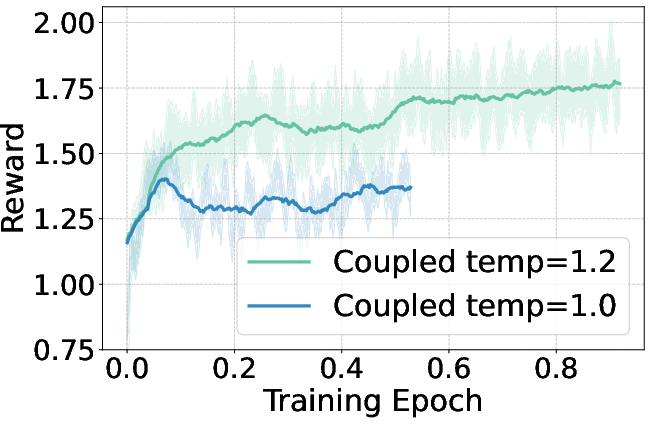
Figure 4: Reward curves during GRPO training, comparing coupled-GRPO with d1 baselines.
Practical Implications and Future Directions
The findings indicate that leveraging higher sampling temperatures not only diversifies token choices but also alters generation order, enhancing model flexibility. This diversity allows for richer RL rollout spaces, thus optimizing model capacity and performance. Moreover, the paper's results indicate potential avenues for diffusion models in complex reasoning and code generation tasks, suggesting further exploration into long-chain reasoning and multi-lingual code generation.
Conclusion
The exploration of DiffuCoder provides significant insights into the behavior of masked diffusion models in code generation. It establishes a foundation for diffusion-native RL methodologies, achieving marked improvements over traditional approaches. Coupled-GRPO emerges as a promising tool for training dLLMs, paving the way for future advancements in AI-driven code generation and related fields.

