- The paper introduces DPad which leverages suffix dropout to reduce computational redundancy in diffusion language models while maintaining output accuracy.
- It employs a sliding window and distance-decay dropout strategy, achieving up to 61.4× speedup on benchmarks such as LLaDA-1.5.
- DPad integrates seamlessly with existing architectures without requiring retraining, highlighting its potential for scalable and efficient LLM deployment.
DPad: Efficient Diffusion LLMs with Suffix Dropout
Overview
This paper introduces the Diffusion Scratchpad (DPad), an efficient approach for diffusion-based LLMs (dLLMs) that leverages suffix dropout to reduce computational redundancy. The core premise of DPad is to streamline the denoising process intrinsic to dLLMs by focusing on a limited subset of suffix tokens that act as a "scratchpad," thereby reducing computational overhead without sacrificing model accuracy.
Methodological Insights
Diffusion LLMs (dLLMs)
Unlike conventional autoregressive models, dLLMs eliminate sequential dependencies by framing text generation as a parallel denoising process. While this approach allows for parallel token generation, it incurs high computational costs due to the redundant prediction of suffix tokens that do not contribute significantly to the output.
Scratchpad Mechanism
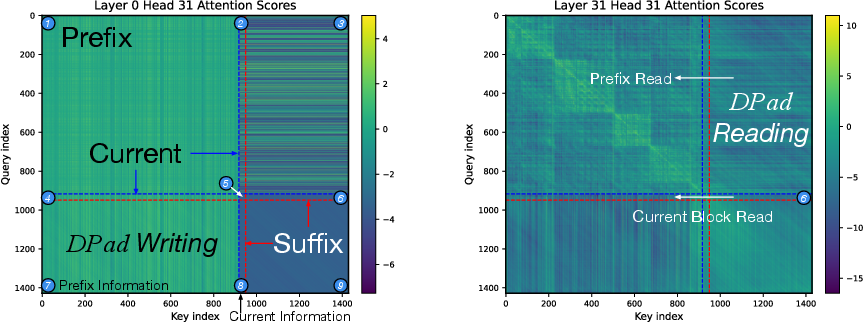
Suffix tokens in dLLMs serve as an information reservoir, collecting signals from prefix tokens. This paper likens the function of these tokens to a "scratchpad," providing contextual cues that assist in generating the current block. The redundancy observed in suffix tokens increases with their distance from the current block.
DPad: Efficiency Enhancements
DPad proposes two strategies to efficiently utilize suffix attention:
- Sliding Window: This maintains a fixed-length suffix window, ensuring only nearby suffix tokens are considered, thus bounding the computational effort required.
- Distance-decay Dropout: This strategically prunes distant suffix tokens using a gaussian sampling process before computing attention scores, thereby reducing unnecessary calculations.
Both strategies complement existing optimization techniques, such as prefix caching, to deliver substantial performance improvements.
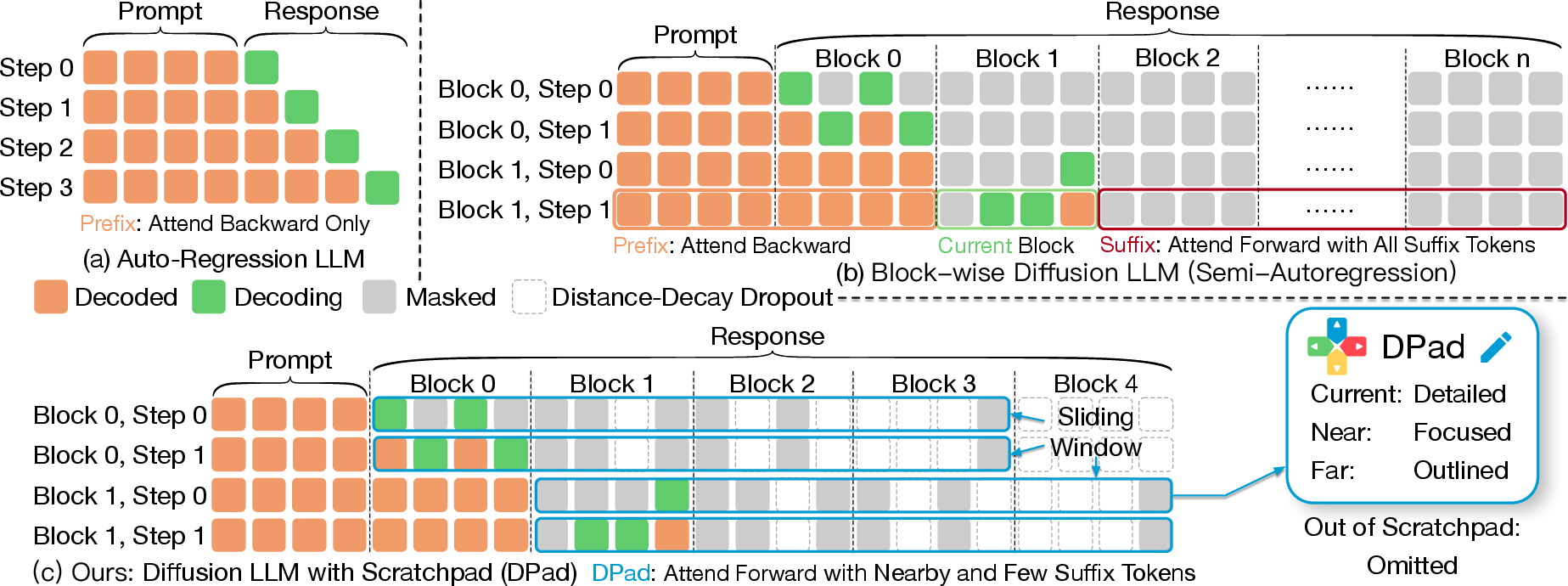
Figure 1: Comparison of (a) autoregressive LLMs, (b) block-wise diffusion LLMs, and (c) our DPad. DPad restricts suffix attention via: (i) Sliding Window.
Evaluative Metrics and Results
The paper evaluates DPad across several benchmarks using models like LLaDA-1.5 and Dream with notable findings:
Implications and Future Directions
The implications of DPad are significant for the scalability and deployment of dLLMs in practical applications. Its compatibility with current optimizations makes it a potent tool for enhancing text generation efficiency. Future research could focus on integrating similar dropout strategies during the training phase to naturally align model training and inference conditions, further enhancing accuracy and efficiency.
In conclusion, DPad contributes a critical component towards efficient, scalable language modeling, mitigating one of the major bottlenecks of diffusion-based approaches by harnessing the redundant nature of suffix tokens. Future work could involve extending these dropout mechanisms to training phases, potentially offering more robust and finely tuned models.