- The paper presents a scalable GraphRAG system that replaces costly LLM-based triple extraction with an online pseudo-alignment method to handle millions of documents.
- It introduces a multi-step retrieval process combining dense and sparse retrieval with Reciprocal Rank Fusion to address complex, multi-hop queries.
- The study shows that while the system maintains accuracy for simple queries, challenges remain in addressing misalignment issues during multi-hop retrieval.
Extending GraphRAG to Handle Millions of Documents
Introduction
The paper "Millions of GeAR-s: Extending GraphRAG to Millions of Documents" presents an exploration into scaling Graph-based Retrieval-augmented Generation (GraphRAG) systems to handle very large datasets. Traditional GraphRAG methodologies have typically demonstrated effective performance on datasets with relatively smaller sizes, usually in the range of hundreds of thousands of documents. This work addresses the challenge of scaling these methodologies to datasets with millions of passages, such as those encountered in the SIGIR 2025 LiveRAG Challenge.
System Architecture and Method Modifications
The core of this work builds upon the GeAR (Graph-enhanced Agent for Retrieval-augmented Generation) framework developed in prior studies [Shen2024]. The revised system architecture is shown in Figure 1, which highlights the new components in blue.
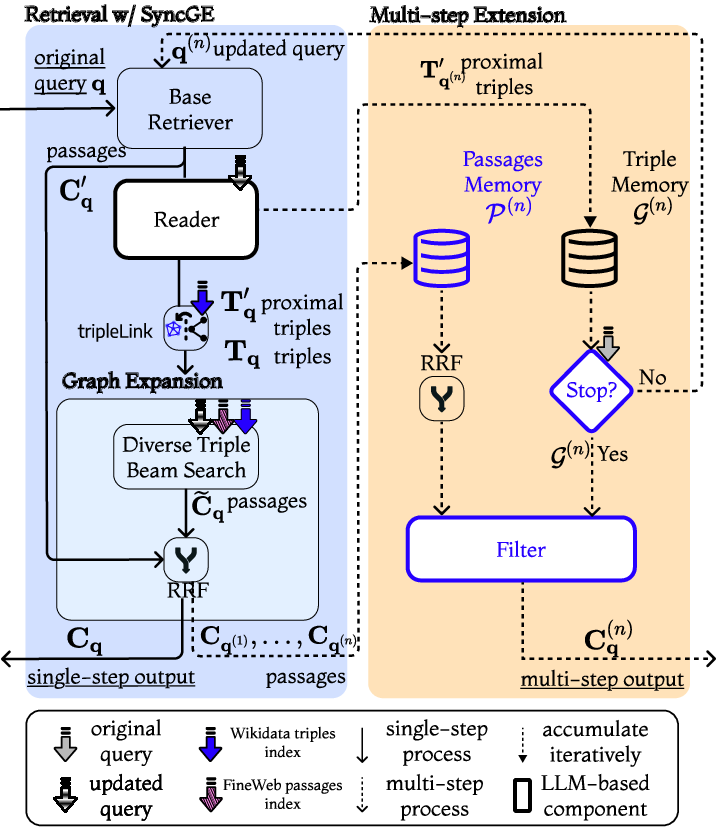
Figure 1: System Architecture. New or modified components in GeAR are highlighted in blue.
In the adapted system, the offline LLM-based triple extraction process is replaced by an online pseudo-alignment of retrieved passages with existing KG (Knowledge Graph) triples sourced from Wikidata. This change is driven by the desire to avoid the prohibitive costs of running large LLMs over extensive datasets required for traditional offline extraction. The alignment process uses basic retrieval strategies, demonstrating surprising efficacy in preliminary evaluations.
Multi-Step Agentic Retrieval
The system employs a multi-step retrieval process optimized for handling complex, multi-hop queries. Initially, a dense retriever identifies relevant passages, followed by a refinement step involving sparse retrieval techniques. Reciprocal Rank Fusion is then used to merge these results effectively. The overall retrieval process iteratively decomposes the original query into simpler sub-queries, facilitating multi-step reasoning.
Incorporating External Knowledge
One of the critical challenges addressed in the study is aligning these retrieved passages with pre-existing triples from an external KG like Wikidata. The paper introduces a mechanism to link proximal triples found in FineWeb Passages with those in Wikidata using simple COTS retrieval strategies. This step allows the system to leverage extensive external knowledge while maintaining relevance to the queried dataset.
Experimental Evaluation
Experiments involve the LiveRAG 2025 dataset and utilize measures of correctness and faithfulness to evaluate performance. The results indicate that while the adapted system maintains accuracy in simple query scenarios without full reliance on graph expansions, multi-hop queries still reveal limitations in scalability using the current method.
Discussion of Misalignment Issues
The study identifies notable challenges in aligning topics across different data repositories, notably the divergence in topic when aligning proximal triples with Wikidata triples. This misalignment can result in decreased accuracy for queries requiring specific contextual knowledge.
Conclusion
The work successfully demonstrates a scalable approach to applying GraphRAG methods over extensive corpus sizes by replacing the costly LLM-based triple extraction with effective online approximation methods. Nonetheless, findings stress the importance of developing advanced semantic models that can bridge the gap between graph data and natural language, offering a comprehensive solution for effectively leveraging vast datasets within GraphRAG frameworks.
In summary, this work marks a crucial step forward in adapting Graph-enhanced RAG systems to the demands of large-scale text corpora, showcasing both the potential and challenges of such adaptations. Future research can focus on refining alignment processes and integrating more sophisticated semantic retrieval models to further enhance system performance.

