- The paper introduces EraRAG, which efficiently integrates dynamic updates in retrieval-augmented generation systems through hyperplane-based LSH.
- It constructs a multi-layered retrieval graph to minimize token usage and rebuild time, achieving up to 57.6% and 77.5% reductions over traditional methods.
- The method supports high-accuracy question answering by balancing detailed semantic retrieval with efficient localized re-partitioning.
EraRAG: Efficient and Incremental Retrieval Augmented Generation for Growing Corpora
The paper introduces EraRAG, an innovative framework for Retrieval-Augmented Generation (RAG) designed to efficiently handle dynamic updates in continuously evolving corpora. This approach addresses the challenges that current Graph-RAG systems face, especially their inefficiency in dealing with incremental data updates. EraRAG offers a scalable solution by structuring retrieval over an external corpus with a multi-layered graph architecture capable of fast, localized updates.
Motivation and Background
Existing RAG methods enhance LLMs by integrating external knowledge, thereby improving their ability to handle domain-specific queries, multi-hop reasoning, and deep contextual understanding. However, these systems often operate with static corpora, which necessitate expensive full-graph reconstruction when new documents are introduced. This limitation significantly restricts scalability in real-world applications where data grows continuously.
EraRAG addresses this issue by leveraging hyperplane-based Locality-Sensitive Hashing (LSH) to organize and manage data updates. This design eliminates the need for costly retraining or global graph recomputation while maintaining high retrieval accuracy and low latency, making it a practical approach for dynamic environments.
Implementation Details
Graph Construction
EraRAG constructs a hierarchical retrieval graph by organizing the input corpus into a multi-layered structure. The process involves partitioning corpus chunks into groups using LSH-based segmentation, designed to ensure semantic coherence while allowing for efficient updates. Each chunk is encoded into an embedding vector and hashed using a set of hyperplanes to determine its grouping, facilitating efficient semantic clustering.
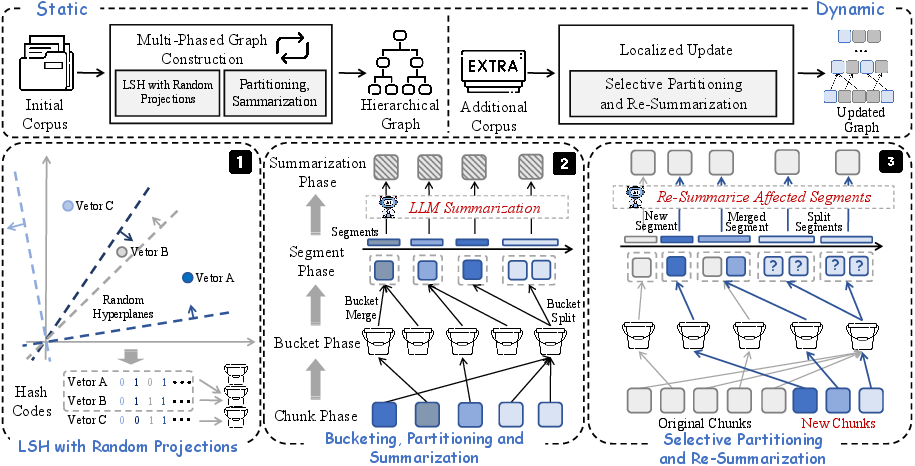
Figure 1: Overview of EraRAG. The framework constructs a hierarchical retrieval graph, with efficient update mechanisms via selective re-partitioning and summarization.
Dynamic Updates
EraRAG introduces a localized update strategy to handle dynamic data efficiently. New data is inserted by selectively re-partitioning and re-summarizing only the affected graph segments, which minimizes computational overhead. This strategy ensures that updates remain efficient without disrupting existing graph topology, significantly reducing token consumption and rebuilding time.
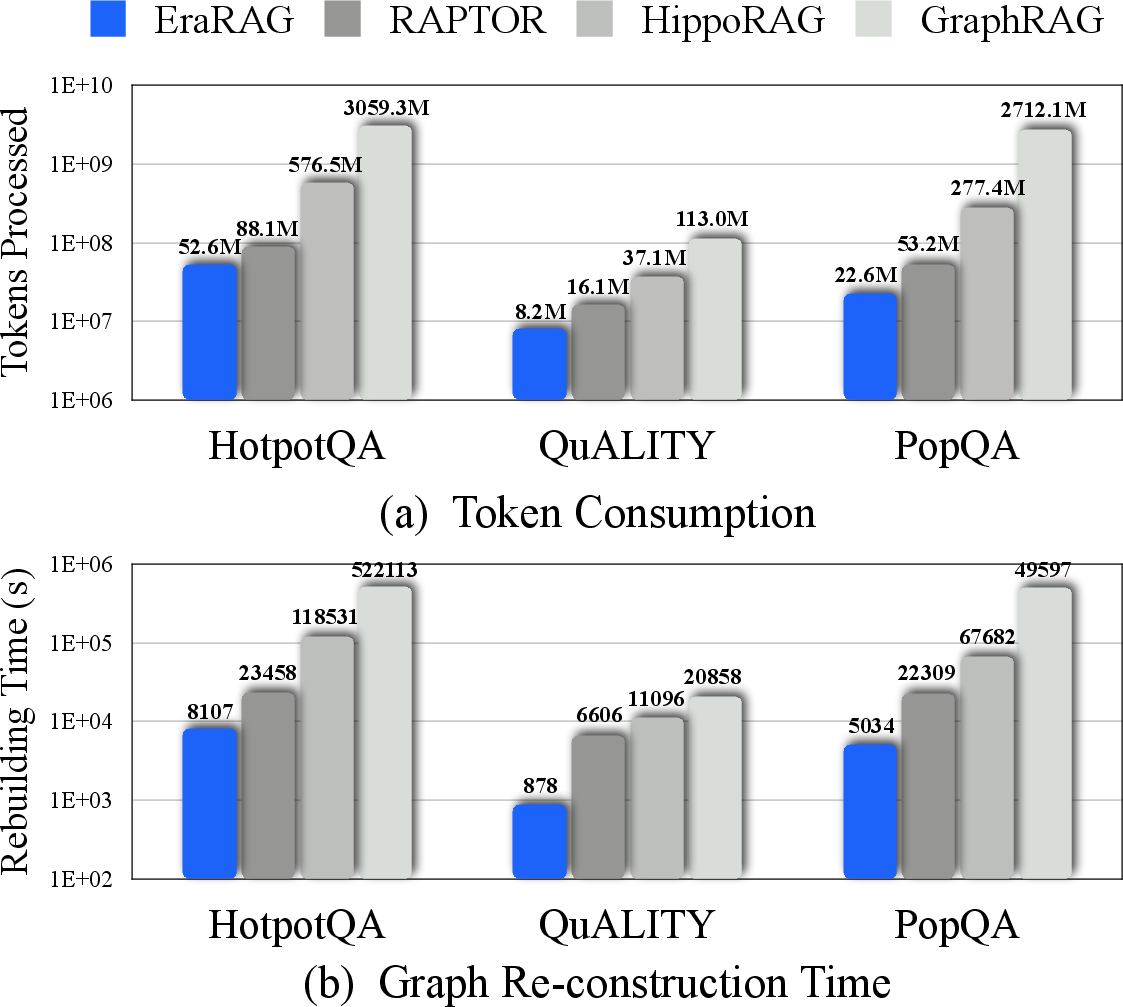
Figure 2: Token cost and graph rebuild time throughout insertions.
Query Processing
During query processing, EraRAG employs a collapsed graph search strategy to integrate both detailed leaf node information and high-level semantic abstractions encoded in the summary nodes. This approach allows for flexible responses to various query types, maintaining a balance between retrieval granularity and efficiency.
EraRAG demonstrates superior performance over existing Graph-RAG systems on multiple QA benchmarks. It achieves notable improvements in Accuracy and Recall, particularly excelling in datasets requiring deep reading comprehension and multi-hop reasoning. These gains are largely attributed to its balanced graph segmentation and efficient summarization strategies.
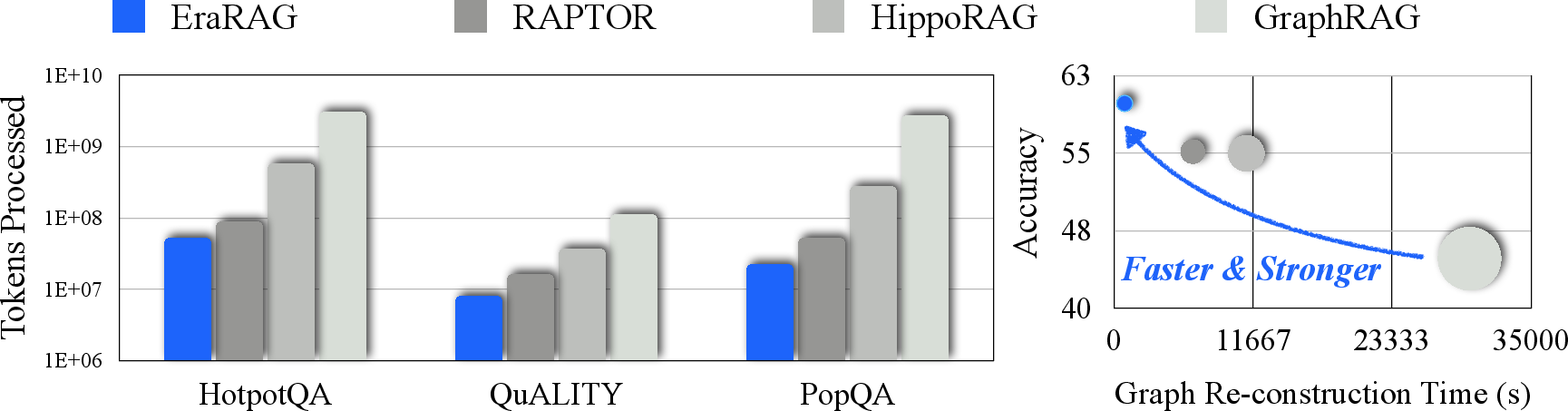
Figure 3: Token processed (left) of EraRAG and baselines via initial graph construction and consecutive insertions. Detailed performance (right) of EraRAG and baselines on QuALITY.
Dynamic Insertion Efficiency
EraRAG's dynamic update mechanism showcases a significant reduction in both token usage and graph construction time, achieving up to 57.6% and 77.5% reductions compared to existing solutions, respectively. This efficiency highlights the framework's suitability for real-world applications with rapidly evolving corpora.
Conclusion
EraRAG provides a scalable, efficient system for retrieval-augmented generation, enabling real-time adaptation to growing datasets without compromising retrieval performance. Its innovative use of LSH for dynamic partitioning and targeted re-summarization offers significant computational savings and robustness, offering a clear path forward for practical RAG implementations in dynamic information environments.


