- The paper presents a novel DoTA-RAG pipeline that integrates dynamic routing and hybrid retrieval to optimize high-throughput search processes.
- It combines dense search, BM25 filtering, and cross-encoder reranking to significantly enhance retrieval correctness and reduce latency.
- Experimental results indicate a correctness score of 0.929, emphasizing efficiency improvements despite challenges in maintaining faithfulness due to output constraints.
DoTA-RAG: Dynamic of Thought Aggregation RAG
The paper "DoTA-RAG: Dynamic of Thought Aggregation RAG" presents a novel approach to Retrieval-Augmented Generation (RAG), named DoTA-RAG. This approach is tailored for scenarios involving high-throughput and large-scale web knowledge indexes, addressing common challenges such as high latency and limited accuracy across diverse datasets.
The ability of LLMs to excel in numerous NLP tasks is widely acknowledged; however, their limitations regarding up-to-date or niche-specific knowledge often lead to hallucinations. RAG frameworks help mitigate these issues by granting LLMs access to external documents. DoTA-RAG aims to enhance traditional RAG pipelines which suffer from inefficiencies over sizable and varied datasets. Traditional methods incorporate query rewriting and dynamic routing to optimize retrieval processes.
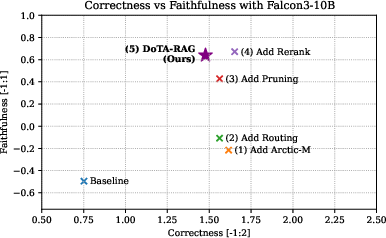
Figure 1: RAG Correctness and Faithfulness in the internal test set for different retrieval-augmented generation approaches. We use the Falcon3-10B-Instruct as the base LLM.
The foundation of DoTA-RAG includes dynamic routing and hybrid retrieval techniques. Dynamic routing optimizes retrieval paths by leveraging query semantics and metadata, while hybrid retrieval merges dense expansion with sparse filtering and reranking.
DoTA-RAG Pipeline
The DoTA-RAG stack consists of a five-stage pipeline:
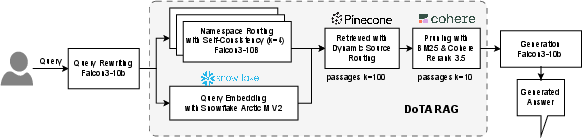
Figure 2: Diagram illustrating the components and workflow of DoTA-RAG.
- Query Rewriting: Although initially excluded, query rewriting was reintroduced to address issues with specific terms and misspellings during live challenges.
- Dynamic Namespace Routing: Utilizes an ensemble-based classification to dynamically select relevant sub-indexes, significantly reducing search space and latency.
- Hybrid Retrieval: Comprises three steps: dense search, BM25 pruning, and cross-encoder reranking, to ensure high relevance.
- Context Aggregation: Aggregates top-ranked passages with appropriate truncation.
- Answer Generation: Applies Falcon3-10B-Instruct for generating answers grounded in the retrieved context.
Experimental Setup and Evaluation
To evaluate DoTA-RAG, the researchers constructed an internal test set using the DataMorgana API to generate a diverse set of Q{content}A pairs, covering a broad spectrum of user intents and question complexities. This diversity was ensured by tagging documents using WebOrganizer's classifiers, maintaining balanced coverage across various domains and formats.
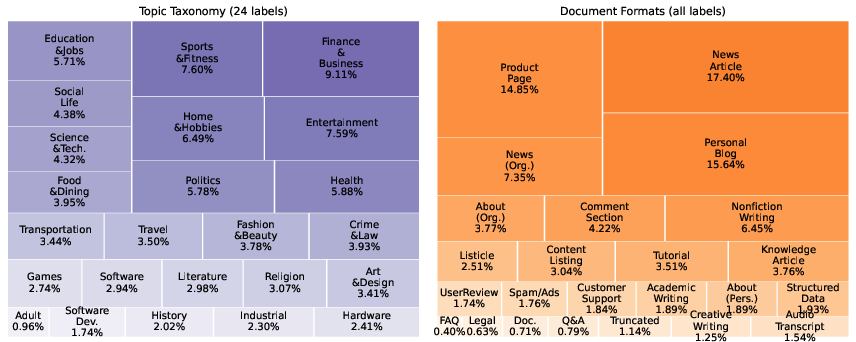
Figure 3: Distribution of topics (left) and document formats (right) in Fineweb-10BT, based on WebOrganizer classifiers. The area of each block reflects the number of documents per domain in the corpus.
Results and Analysis
The evaluation metrics employed were Correctness and Faithfulness, measuring the relevance and grounding of generated answers, respectively. Subsequent to initial pipeline configuration, the team explored multiple enhancements, each showing incremental improvements.
Ultimately, during the SIGIR 2025 LiveRAG Challenge, DoTA-RAG achieved a correctness score of 0.929, validating its effectiveness in producing quality answers. However, faithfulness was adversely impacted, largely due to an oversight regarding the 300-word output cap during tuning. Further assessments revealed that faithfulness decreased from 0.702 to 0.336 due to this constraint.
Limitations and Future Work
Notable challenges include the scope of multi-source routing and the limitations of context size within the retrieval and generation windows. Future research directions involve addressing these limitations by incorporating graph-based knowledge bases into routing strategies and developing techniques to compact context beyond an 8,000-token capacity.
Conclusion
The study delineates the DoTA-RAG system, which integrates dynamic elements and hybrid retrieval to enhance the retrieval process across expansive, mutable knowledge bases. The pipeline's construction enabled high-quality, efficient retrieval, suggesting its potential for practical applications in high-demand environments. This research underscores the significant benefits of strategic query routing and document selection to bolster the relevance and reliability of RAG-based systems.

