- The paper introduces GraphRAG, extending traditional RAG by incorporating structured graph data for enhanced precision and contextual understanding.
- It details a three-stage methodology—graph-based indexing, graph-guided retrieval, and graph-enhanced generation—with hybrid approaches optimizing performance.
- Experimental evaluations across multiple domains demonstrate improved factual accuracy and practical potential in applications like question answering and information extraction.
Graph Retrieval-Augmented Generation: A Survey
Introduction
The paper "Graph Retrieval-Augmented Generation: A Survey" provides a comprehensive overview of the methodologies and applications of Graph Retrieval-Augmented Generation (GraphRAG), which is a novel extension of Retrieval-Augmented Generation (RAG). RAG integrates a retrieval component within LLMs to reference external knowledge bases, enhancing generated content with factual accuracy and domain-specific knowledge. However, traditional RAG systems encounter limitations when dealing with complex entity relationships. GraphRAG addresses these limitations by leveraging structured graph data to provide precise and context-aware responses.
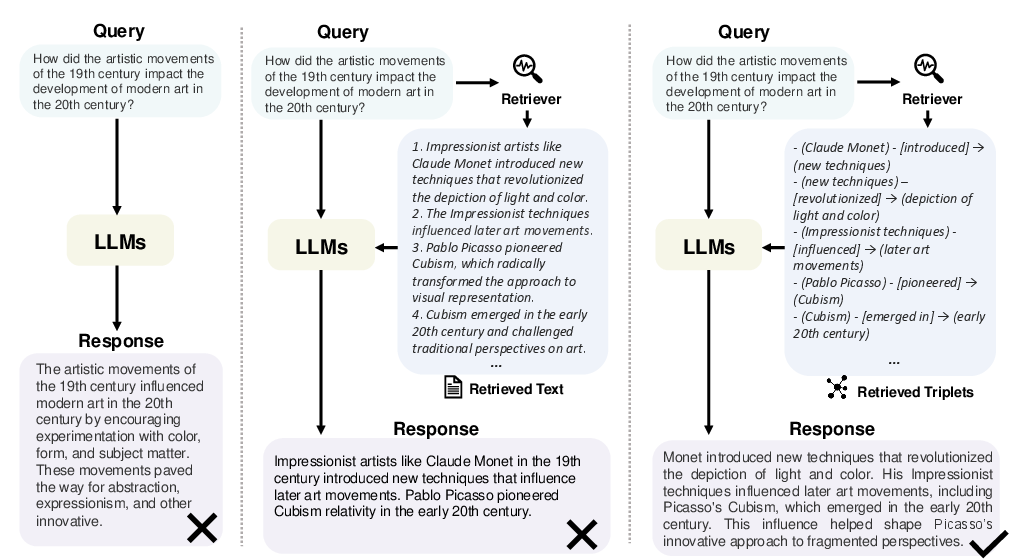
Figure 1: Comparision between Direct LLM, RAG, and GraphRAG. Given a user query, direct answering by LLMs may suffer from shallow responses or lack of specificity. RAG addresses this by retrieving relevant textual information, somewhat alleviating the issue. However, due to the text's length and flexible natural language expressions of entity relationships, RAG struggles with relationships. GraphRAG leverages explicit entity and relationship representations in graph data, enabling precise answers by retrieving relevant structured information.
GraphRAG Framework
GraphRAG is structured into three primary stages: Graph-Based Indexing, Graph-Guided Retrieval, and Graph-Enhanced Generation.
- Graph-Based Indexing (G-Indexing): This stage involves the selection or construction of graph databases, including open knowledge graphs and self-constructed graph data. Indexing techniques are applied to ensure efficient traversal and retrieval operations.
- Graph-Guided Retrieval (G-Retrieval): This stage focuses on extracting relevant graph elements (e.g., nodes, triples, paths, subgraphs) in response to user queries. Selecting appropriate retrieval models and strategies, including non-parametric and LM-based retrievers, is critical for effective retrieval.
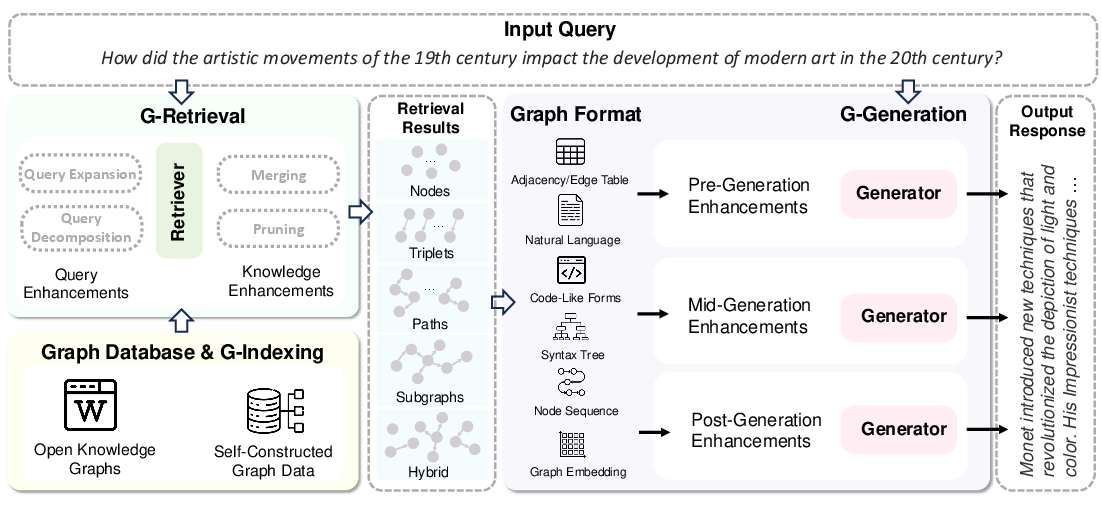
Figure 2: The overview of the GraphRAG framework for the question-answering task. GraphRAG is divided into three stages: G-Indexing, G-Retrieval, and G-Generation. Retrieval sources are categorized into open-source knowledge graphs and self-constructed graph data.
- Graph-Enhanced Generation (G-Generation): In this phase, retrieved graph data is transformed into formats compatible with generative models. Techniques such as hybrid model architectures and graph languages are employed to integrate and enhance output generation.
Implementation Strategies
To implement the concepts of GraphRAG in practice, several approaches can be adopted:
- Graph Construction: Utilize open knowledge graphs or design self-constructed graphs that reflect domain-specific data. Indexing should be optimized for fast and efficient querying.
- Efficient Retrieval Mechanisms: Apply LM-based retrievers to leverage their understanding of natural language queries, complemented by GNN-based methods for deeper graph insights. Consider hybrid retrieval paradigms for complex queries.
- Graph Integration with LLMs: Develop translators to convert graph data into text or code-like formats that LLMs can process. Enhance interactions between LLMs and graph data using techniques like prompt tuning and structured graph descriptions.
- Training and Optimization: Employ joint training strategies for retrievers and generators to improve collaboration and response quality. Consider supervised fine-tuning with specific downstream tasks to enhance performance.
Applications and Evaluation
GraphRAG is applicable in various domains from E-commerce and biomedical fields to academic, literature, and legal contexts. It supports tasks such as question answering, information extraction, fact verification, and recommendation systems. Evaluation benchmarks include datasets like WebQSP, MetaQA, and GrailQA, with metrics such as Exact Match, F1 score, and BERTScore ensuring a consistent evaluation framework.

Figure 3: The overview of graph-based indexing.
Future Prospects
Several areas for future research are identified:
- Dynamic Graph Adaptation: Develop methods for real-time updates to graph databases to accommodate new entities and relationships.
- Integration of Multi-Modality Data: Explore the inclusion of modalities beyond textual data to enrich the knowledge graphs.
- Advanced Retrieval Algorithms: Focus on scalable solutions for large-scale graphs.
- Combining Graph Foundation Models: Leverage graph foundation models to enhance existing pipelines.
- Optimizing Context Compression: Investigate lossless compression techniques for lengthy sequences.
- Standard Benchmarks: Establish unified benchmarks for GraphRAG performance evaluation.
Conclusion
GraphRAG represents a significant advancement over traditional RAG systems, offering enhanced capabilities for precise and context-aware generation by leveraging structured graph data. This survey provides a systematic overview of the methodologies, technologies, and potential future directions to stimulate further research and application of GraphRAG systems.