- The paper introduces a novel document-level KG construction framework using retrieval-augmented techniques, achieving 95.81% accuracy on the MINE dataset.
- It employs semantic document chunking, sentence-level NER, and vectorization to effectively mitigate long-context forgetting and entity disambiguation.
- The framework outperforms competitors like KGGen and GraphRAG in entity density and relational richness, setting a new benchmark for knowledge graph research.
RAKG: Document-level Retrieval Augmented Knowledge Graph Construction
The paper "RAKG: Document-level Retrieval Augmented Knowledge Graph Construction" presents an advanced framework for constructing knowledge graphs (KGs) at a document level, utilizing retrieval-augmented techniques to enhance the integration of knowledge from LLMs. The primary focus is on overcoming challenges such as long-context forgetting and entity disambiguation in traditional KG construction.
Overview of the RAKG Framework
The RAKG framework streamlines the process of constructing KGs by segmenting documents for semantic processing and utilizing retrieval techniques to enhance LLM integration. It introduces pre-entities to mitigate common issues like entity disambiguation, employing a sentence-by-sentence Named Entity Recognition (NER) approach to ensure complete node coverage. The framework follows a structured method of document chunking, vectorization, and retrieval, ensuring comprehensively integrated knowledge that aligns with semantic expectations.
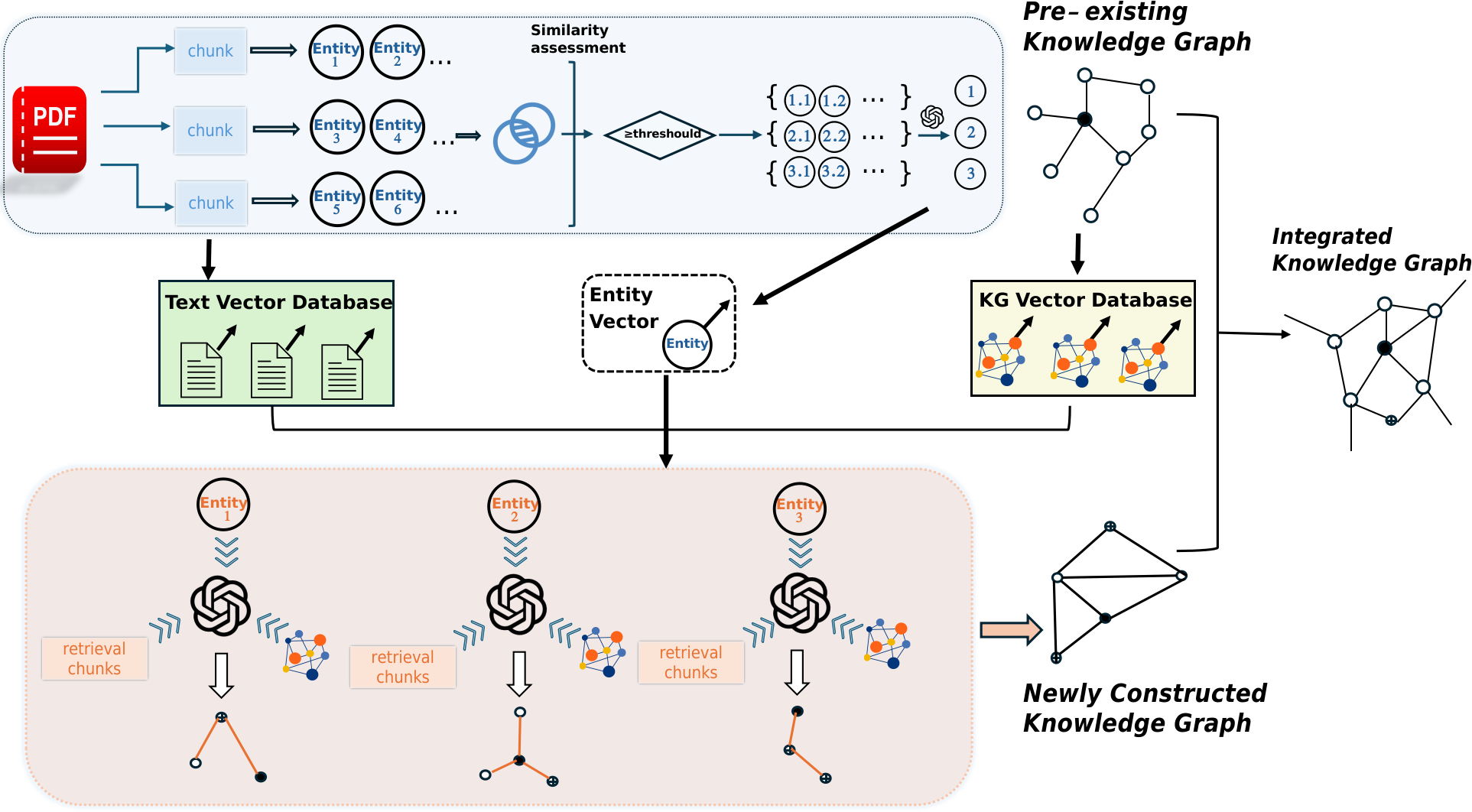
Figure 1: The RAKG framework processes documents through sentence segmentation and vectorization, extracts preliminary entities, and performs entity disambiguation and vectorization.
Methodological Components
Document and Graph Vectorization
RAKG employs a semantic-focused document chunking strategy, vectorizing text for efficient processing. Both the initial KG and identified entities are vectorized, enabling precise entity matching and seamless relationship extraction.
Entity Recognition and Disambiguation
Pre-entities identified from text chunks undergo vectorized similarity checks to consolidate similar entities across the document. This reduces redundancy and enhances the clarity and accuracy of entities included in the constructed KG.
Construction of Relationship Networks
By using Corpus Retrospective Retrieval and Graph Structure Retrieval, RAKG establishes robust relationship networks. The relationships are generated from both the available text and pre-existing KGs, evaluated for truthfulness via "LLM as judge" mechanism, ensuring high fidelity of the generated knowledge.
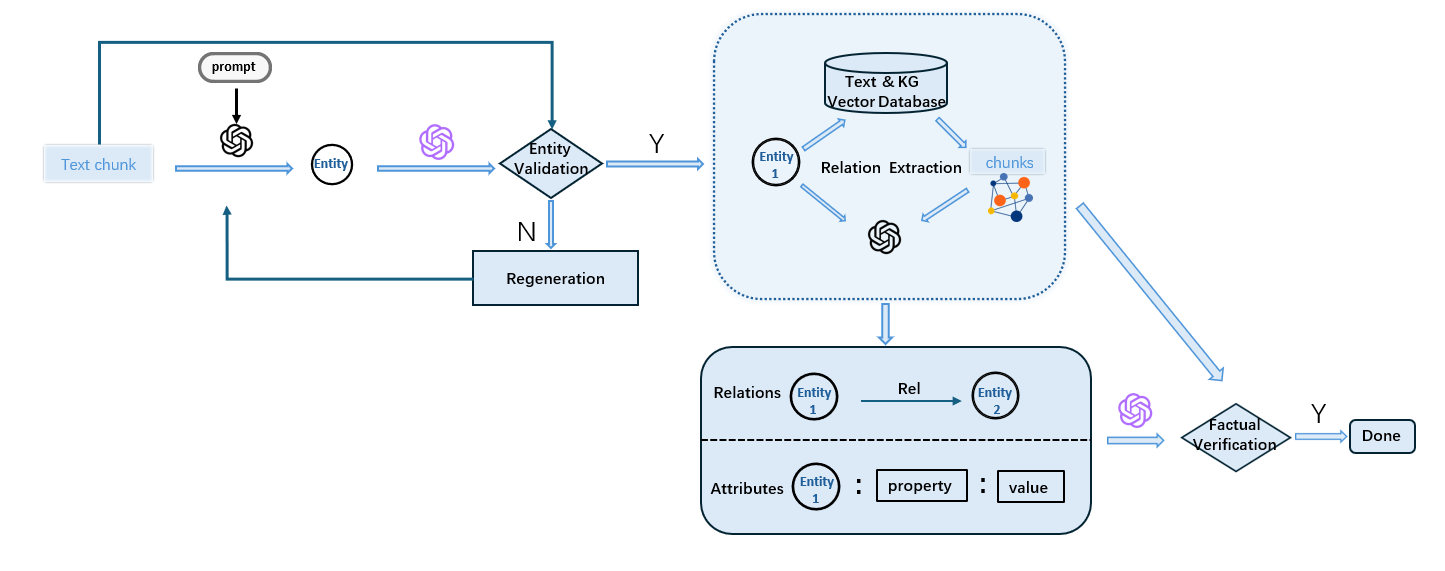
Figure 2: The process of LLM as judge: Extracted entities are checked against the source text to eliminate hallucinations.
Comparative Evaluation
The RAKG framework was tested on the MINE dataset, demonstrating superior performance metrics over baseline models such as KGGen and GraphRAG. RAKG achieved a 95.81% accuracy rate, highlighting its exceptional capacity for extracting and structuring knowledge from complex documents.
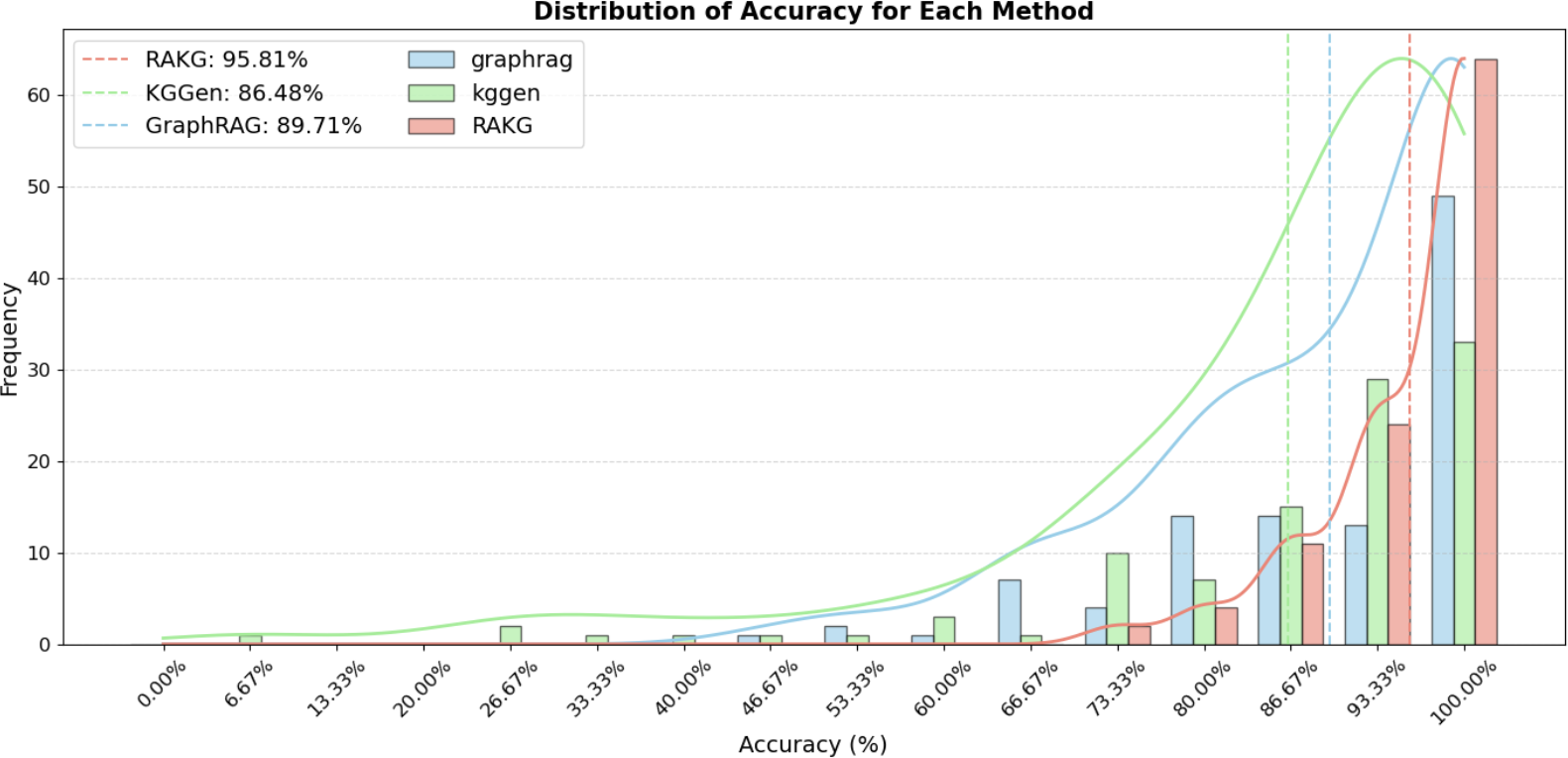
Figure 3: Distribution of SC scores across 105 articles for GraphRAG, KGGen, and RAKG on the MINE dataset.
RAKG's entity density and relational richness metrics notably surpassed competitors, indicating a more comprehensive and interconnected entity network.
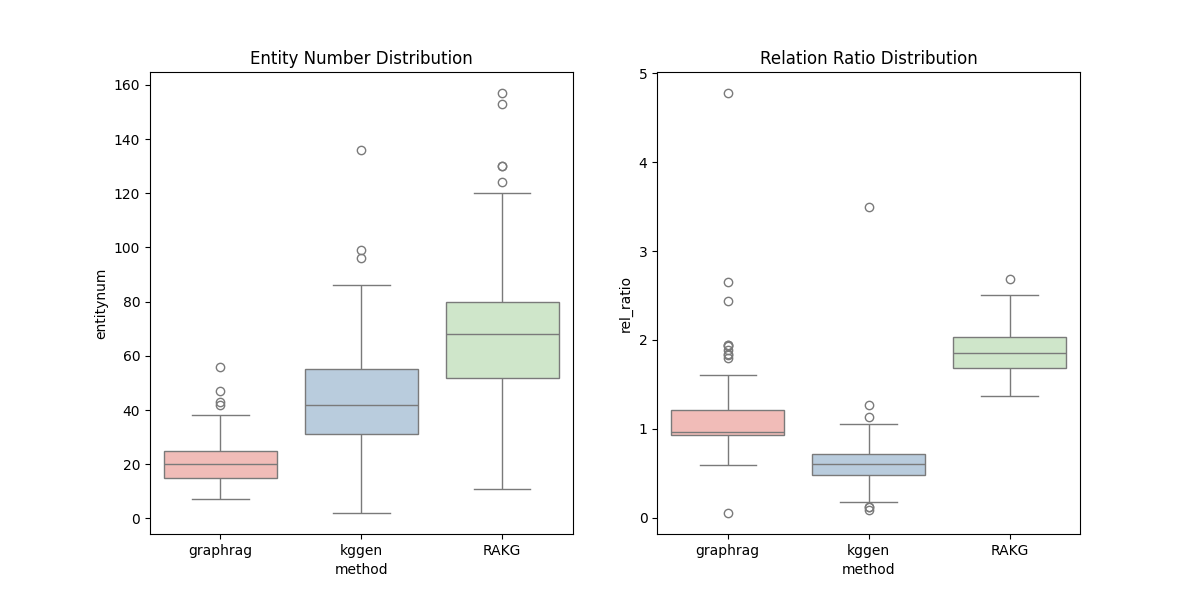
Figure 4: This visualization shows the entity density and relation richness of knowledge graphs generated by RAKG, GraphRAG, and KGGen.
Practical Implications and Future Directions
RAKG revolutionizes document-level KG construction by effectively addressing traditional limitations through innovative methodologies in vectorization, entity recognition, and retrieval-enhanced generation. Its impact is profound in fields demanding high-fidelity knowledge representations, with potential expansions into areas such as automated content curation and improved information retrieval systems.
Future research could explore the scalability of the RAKG approach to larger datasets and its adaptation to evolving LLM capabilities, potentially incorporating real-time data processing for dynamic KG updates in various application domains.
Conclusion
The RAKG framework offers a robust, methodical approach to document-level knowledge graph construction, significantly enhancing the accuracy and breadth of knowledge integration from documents. With rigorous experimental validation, it sets a benchmark for future innovations in knowledge graph research, paving the way for comprehensive knowledge systems in AI applications.