- The paper introduces LogicRAG, a framework that dynamically builds logic dependency graphs to guide adaptive retrieval and reasoning without pre-built graphs.
- It decomposes queries into subproblems and employs context and graph pruning to reduce token cost and redundant retrieval rounds.
- Empirical results show LogicRAG outperforms state-of-the-art methods on multi-hop QA benchmarks, with accuracy improvements up to 14.7%.
LogicRAG: Retrieval-Augmented Generation with Adaptive Reasoning Structures
Introduction and Motivation
Retrieval-Augmented Generation (RAG) has become a standard paradigm for mitigating hallucinations and factual errors in LLMs by grounding generation in retrieved external knowledge. Recent advances in graph-based RAG (GraphRAG) have demonstrated that structuring the corpus as a graph can improve multi-hop reasoning and retrieval accuracy. However, these methods are hampered by the high cost and inflexibility of pre-constructing knowledge graphs, which are often misaligned with the logical structure required by diverse, real-world queries. The paper introduces LogicRAG, a framework that eschews pre-built graphs in favor of dynamically constructing a logic dependency graph at inference time, enabling adaptive, query-specific retrieval and reasoning.
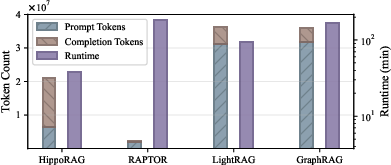
Figure 1: Token and runtime cost of the graph construction process of graph-based RAG methods on 2WikiMQA.
As shown above, the token and runtime costs of pre-constructing graphs for GraphRAG are substantial, motivating the need for more efficient, adaptive approaches.
LogicRAG Framework
LogicRAG operates by decomposing the input query into subproblems, constructing a directed acyclic graph (DAG) to model their logical dependencies, and then guiding retrieval and reasoning according to this structure. The process consists of three main stages:
- Query Decomposition and DAG Construction: The input query is segmented into subproblems using LLM-based few-shot prompting. Logical dependencies among subproblems are inferred to form a DAG, which is dynamically updated during inference if new subproblems are identified.
- Graph Linearization and Sequential Reasoning: The DAG is topologically sorted to produce a linear execution order. Subproblems are resolved greedily in this order, with each retrieval conditioned on the outputs of its dependencies, ensuring context-aware and logically consistent reasoning.
- Graph and Context Pruning: To control inference cost and redundancy, LogicRAG applies context pruning (rolling memory summarization) and graph pruning (merging subproblems with similar topological rank for unified retrieval).
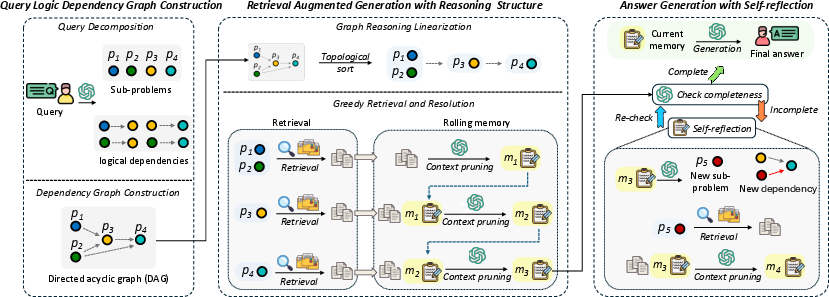
Figure 2: Illustration of the proposed LogicRAG.
This architecture enables LogicRAG to adaptively plan retrieval and reasoning steps, tightly aligning them with the logical structure of the query.
Technical Details
Query Logic Dependency Graph
Let Q be the input query, decomposed into subproblems P={p1,...,pn}, each corresponding to a node in the DAG G=(V,E). Edges in E encode logical dependencies, ensuring acyclicity and a well-defined reasoning order. The DAG is constructed and updated via LLM-based reasoning, with dynamic adaptation if retrieval for a node is insufficient.
Graph Reasoning Linearization
The acyclic property of G allows for a topological sort, yielding an ordered sequence of subproblems. Each subproblem p(i) is resolved as follows:
C(i)=R(p(i)∣{fRAG(p(j),C(j))}j<i,v(j)∈Pa(v(i)))
where R is the retrieval function and fRAG is the RAG model output. This greedy, forward-pass approach eliminates recursion and supports efficient, context-aware multi-step reasoning.
Pruning Strategies
- Context Pruning: After each subproblem is resolved, its retrieved context and answer are summarized via the LLM and incorporated into a rolling memory. This prevents context bloat and maintains only salient information for downstream reasoning.
- Graph Pruning: Subproblems with the same topological rank are merged into a unified query, reducing redundant retrievals and improving efficiency.
Sampling Strategy and Agentic RAG
LogicRAG adopts a sampling-without-replacement strategy for subquery generation, which prevents the model from stalling on uncertain subproblems and reduces token consumption without sacrificing answer quality.
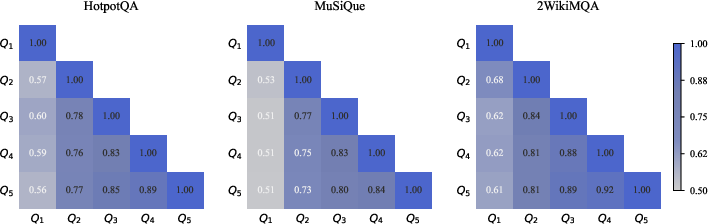
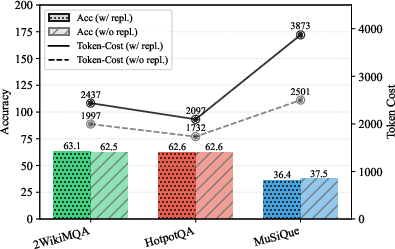
Figure 3: Word-level Jaccard similarity between subqueries across rounds in the agentic RAG process, averaging across the dataset.
This figure demonstrates that sampling without replacement reduces subquery repetition and improves efficiency.
Empirical Evaluation
LogicRAG is evaluated on three multi-hop QA benchmarks: MuSiQue, 2WikiMQA, and HotpotQA. The results show that LogicRAG consistently outperforms both vanilla RAG and state-of-the-art graph-based RAG baselines in both string-based and LLM-based accuracy metrics.
LogicRAG demonstrates particularly strong performance on comparison questions and multi-hop queries, though compositional reasoning remains a challenge.
Efficiency-Effectiveness Trade-offs
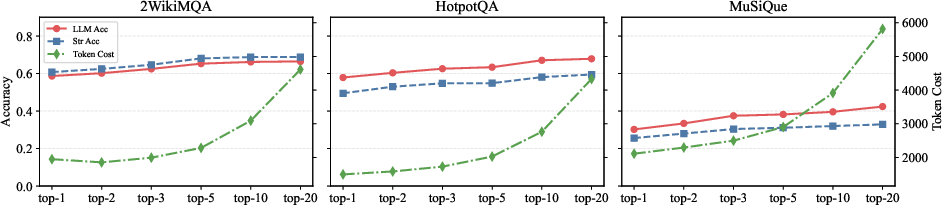
Figure 5: Pareto frontier of efficiency versus effectiveness for different k values.
Increasing the number of retrieved documents (k) improves accuracy but with diminishing returns and rapidly increasing token cost. Moderate k values (e.g., 3 or 5) offer the best trade-off, and LogicRAG's context pruning further mitigates context accumulation.
Impact of Graph Pruning
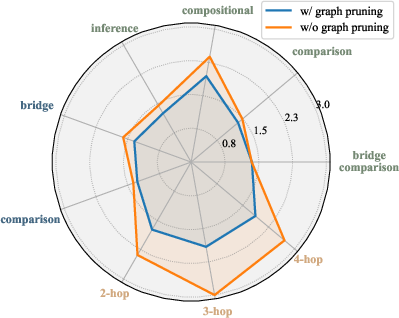
Figure 6: Impact of graph pruning, by comparing the average number of retrieval rounds with and without graph pruning.
Graph pruning consistently reduces the number of retrieval rounds, especially for compositional and multi-hop questions, confirming its effectiveness in eliminating redundant subproblem resolution.
Practical Implications and Theoretical Significance
LogicRAG's dynamic, inference-time construction of reasoning structures addresses the scalability and flexibility limitations of pre-built graph-based RAG. By aligning retrieval and reasoning with the query's logical structure, LogicRAG achieves both higher accuracy and lower token cost, making it suitable for deployment in dynamic or large-scale knowledge environments where corpus updates are frequent and query types are diverse.
Theoretically, LogicRAG demonstrates that explicit, adaptive modeling of logical dependencies at inference time can outperform static graph-based approaches, even in complex multi-hop reasoning tasks. This suggests a shift in RAG research from static, corpus-centric graph construction to dynamic, query-centric reasoning structure induction.
Future Directions
- Improved Compositional Reasoning: Enhancing the model's ability to handle compositional queries, which remain a bottleneck.
- Integration with Symbolic Reasoning: Combining LogicRAG with neuro-symbolic or program-of-thought approaches for even more robust multi-step reasoning.
- Scalability to Open-Domain and Streaming Corpora: Further optimizing the framework for real-time, large-scale, or streaming knowledge bases.
- Trust Calibration and Uncertainty Estimation: Addressing the tendency of LLMs to exhibit overconfidence in complex queries.
Conclusion
LogicRAG introduces a principled, efficient, and adaptive approach to retrieval-augmented generation by dynamically constructing and leveraging logic dependency graphs at inference time. The framework achieves superior performance and efficiency over state-of-the-art baselines, particularly in multi-hop and complex reasoning settings, and provides a foundation for future research in adaptive, logic-aware retrieval and reasoning for LLMs.

