Adaptive Guidance Accelerates Reinforcement Learning of Reasoning Models
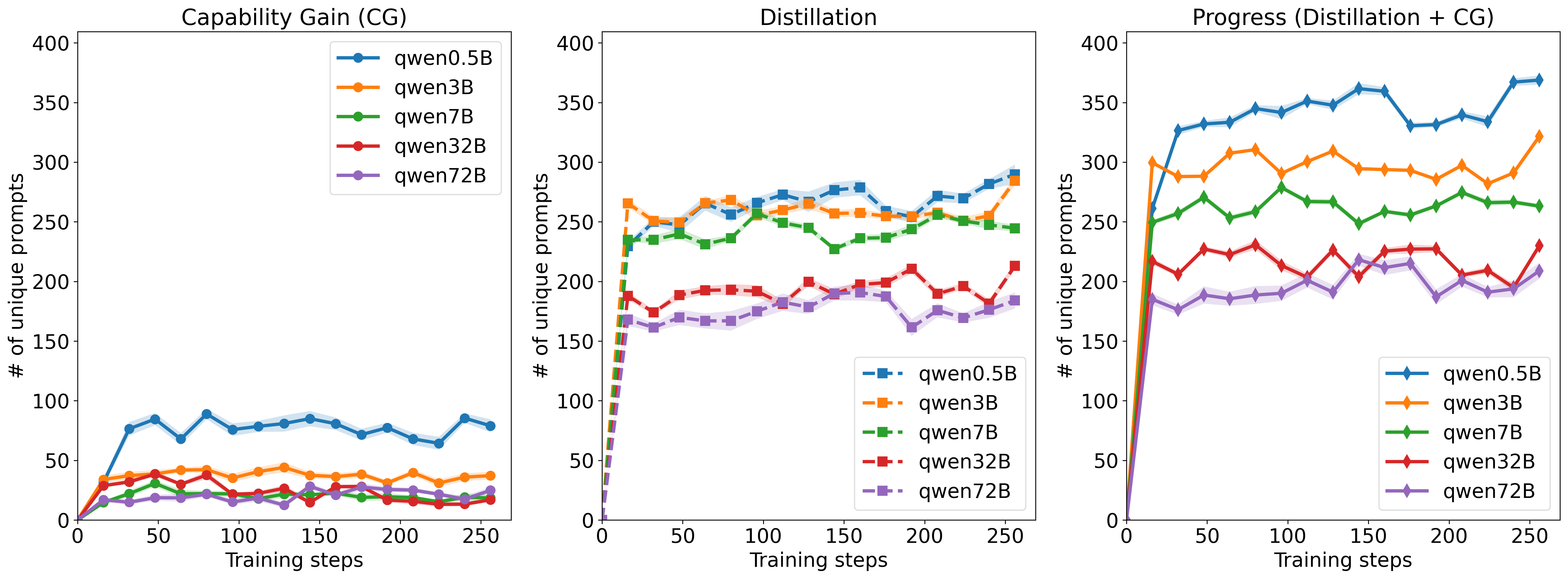
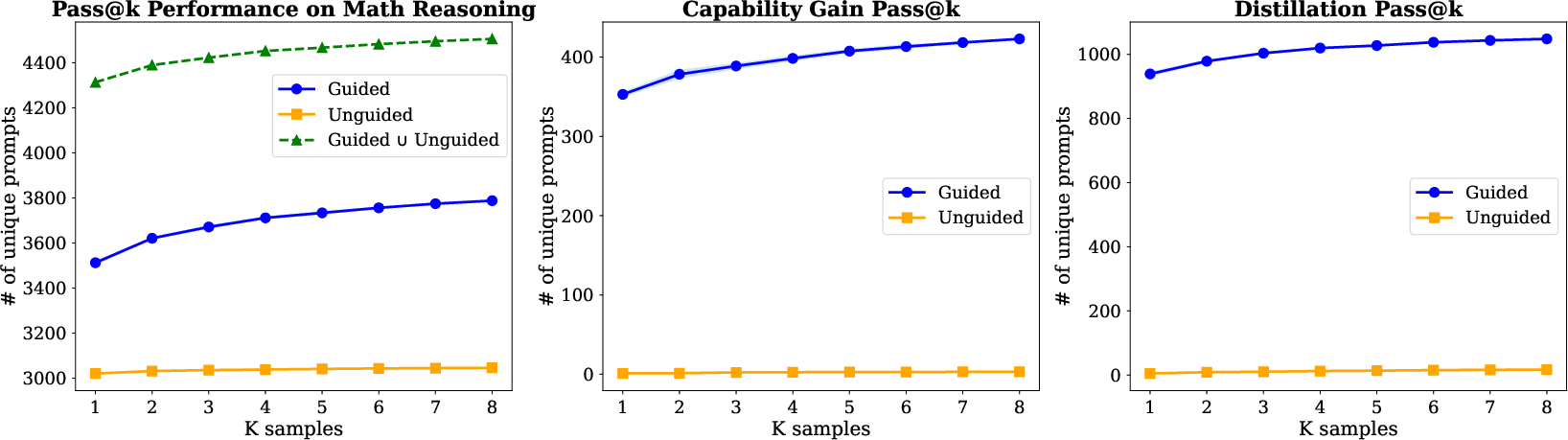
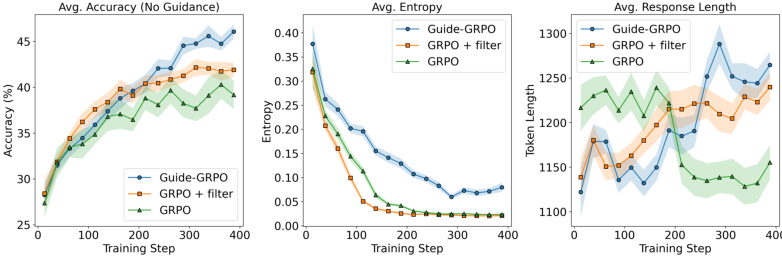
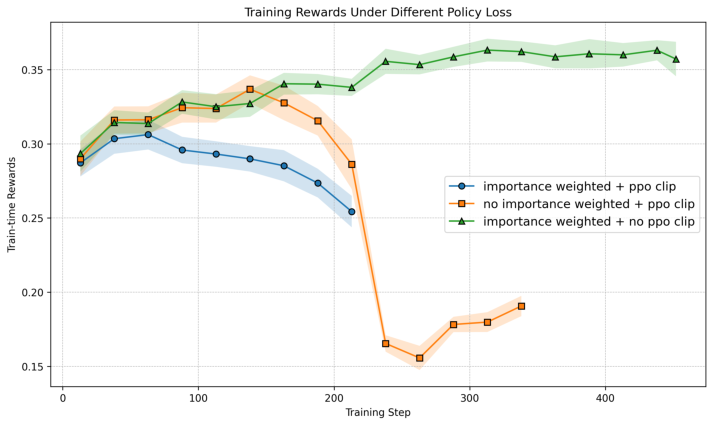
Abstract: We study the process through which reasoning models trained with reinforcement learning on verifiable rewards (RLVR) can learn to solve new problems. We find that RLVR drives performance in two main ways: (1) by compressing pass@$k$ into pass@1 and (2) via "capability gain" in which models learn to solve new problems that they previously could not solve even at high $k$. We find that while capability gain exists across model scales, learning to solve new problems is primarily driven through self-distillation. We demonstrate these findings across model scales ranging from 0.5B to 72B parameters on >500,000 reasoning problems with prompts and verifiable final answers across math, science, and code domains. We further show that we can significantly improve pass@$k$ rates by leveraging natural language guidance for the model to consider within context while still requiring the model to derive a solution chain from scratch. Based of these insights, we derive $\text{Guide}$ -- a new class of online training algorithms. $\text{Guide}$ adaptively incorporates hints into the model's context on problems for which all rollouts were initially incorrect and adjusts the importance sampling ratio for the "off-policy" trajectories in order to optimize the policy for contexts in which the hints are no longer present. We describe variants of $\text{Guide}$ for GRPO and PPO and empirically show that Guide-GRPO on 7B and 32B parameter models improves generalization over its vanilla counterpart with up to 4$\%$ macro-average improvement across math benchmarks. We include careful ablations to analyze $\text{Guide}$'s components and theoretically analyze Guide's learning efficiency.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.