- The paper introduces a benchmark using nearly 3,000 real-world clinical questions to assess medical LLM capabilities.
- It employs a dual evaluation method combining GPT-4o automated scoring with detailed human validation across five key medical tasks.
- Findings reveal LLM strengths in knowledge recall but highlight limitations in complex reasoning and ethical compliance.
LLMEval-Med: A Clinical Benchmark for Medical LLMs
In advancing the field of medical AI, precise evaluation of LLMs is vital. "LLMEval-Med: A Real-world Clinical Benchmark for Medical LLMs with Physician Validation" introduces a rigorous benchmark addressing the inadequacies in existing medical LLM assessments across question types and evaluation methods. This comprehensive framework, developed using nearly 3,000 questions sourced from real-world clinical records, provides a multifaceted analysis of LLM capabilities in medical domains, emphasizing open-ended reasoning and context-driven assessments.
Dataset and Benchmark Structure
LLMEval-Med's dataset is meticulously constructed from electronic health records and clinical scenarios, capturing the multifaceted nature of medical knowledge. The dataset spans five core medical areas: Medical Knowledge (MK), Language Understanding (MLU), Medical Reasoning (MR), Medical Safety and Ethics (MSE), and Medical Text Generation (MTG). It emphasizes open-ended questions and complex reasoning, moving beyond traditional multiple-choice constraints.
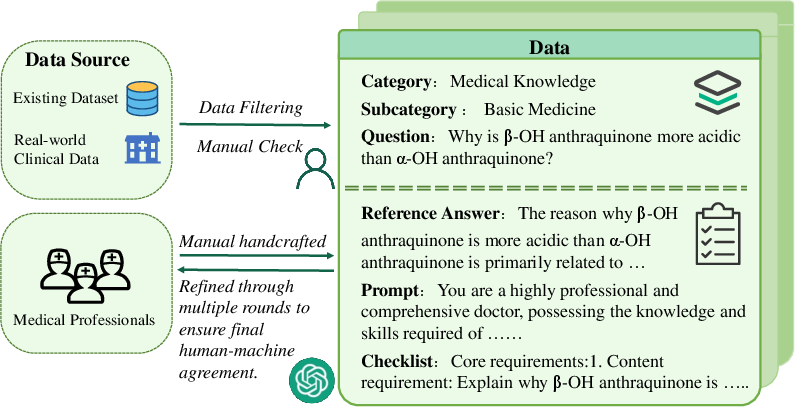
Figure 1: The data source and an instance of LLMEval-Med. Medical professionals create reference answers, prompts, and evaluation checklists through multiple refinement rounds.
Each question is evaluated using an automated pipeline that includes GPT-4o as an LLM judge. This automated scoring is complemented by human ratings to ensure accuracy and robustness. The scoring model is continuously refined based on human-machine agreement analyses, thus ensuring reliable evaluations and decreasing discrepancies between automated and human scoring.
Evaluation Methodology
The evaluation involves five categories with distinctive tasks:
- Medical Knowledge (MK): Focuses on fundamental medical concepts.
- Language Understanding (MLU): Involves parsing and extracting semantically complex information.
- Medical Reasoning (MR): Requires integration of various knowledge domains to infer outcomes.
- Medical Text Generation (MTG): Evaluates the ability to create clinically accurate, coherent narratives.
- Medical Safety and Ethics (MSE): Ensures adherence to ethical guidelines and patient safety protocols.
Each category, as shown in Figure 2, is evaluated under controlled scoring prompts and guidelines to maintain consistency and eliminate subjective variability.
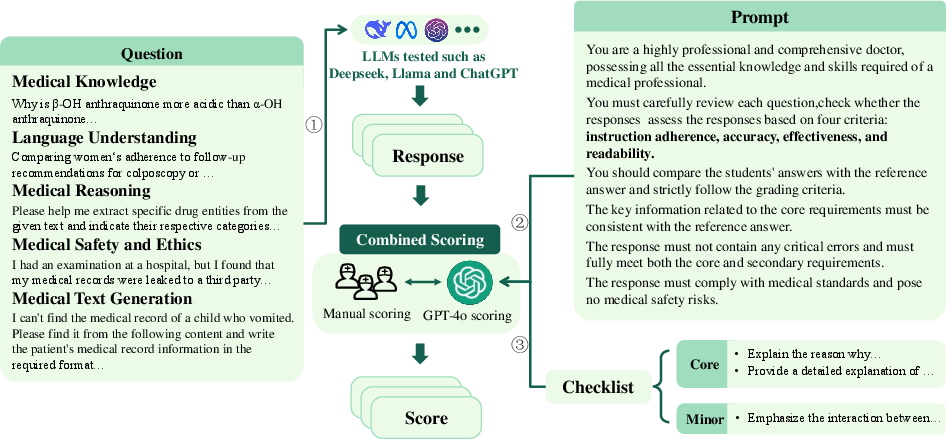
Figure 2: Evaluation flowchart of LLMEval-Med, illustrating the automated scoring mechanism complemented by human inputs.
Testing 13 LLMs, the benchmark revealed that models show varied proficiency across different dimensions. For instance, the best-performing LLMs excelled in knowledge retrieval but struggled in generating detailed text with contextual appropriateness and ethical considerations.
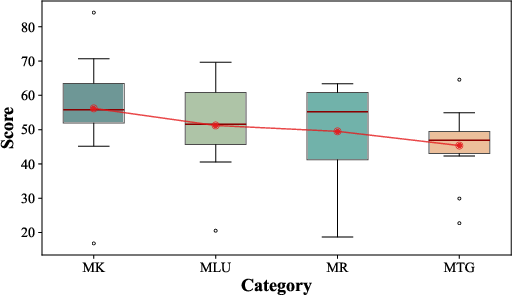
Figure 3: Scoring performance trends across various tasks, indicating relative strengths and weaknesses of LLMs.
The performance trends suggested a hierarchy in task difficulty, with simpler knowledge recall outperforming complex text generation and ethical reasoning tasks, reinforcing the necessity for focused improvements in reasoning and ethical compliance.
Challenges in LLM Evaluation
Despite the benchmark's robustness, discrepancies in human-machine assessments, especially for open-ended tasks, highlight the challenges ahead. LLMs often fail in logical consistency and context adherence, with automated systems showing high false-positive usability rates when compared to human evaluators (Figure 4).
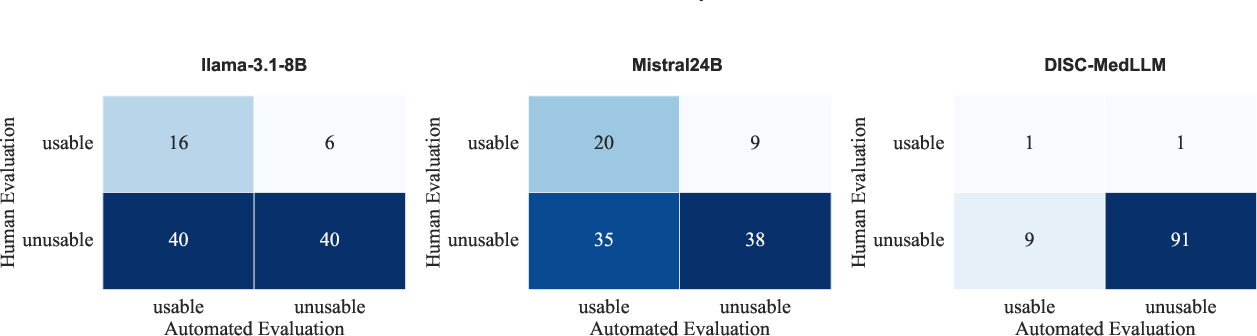
Figure 4: Confusion matrix highlighting the discrepancies in automated evaluation judgments compared to human assessments.
Conclusion
LLMEval-Med sets a precedent for rigor in medical AI evaluation, ensuring high accuracy in safety-critical applications. Its framework not only assesses current LLM capabilities but also identifies critical areas for development, paving the way for safer and more effective AI in healthcare. Moving forward, integrating multimodal tasks and ensuring global applicability remain key considerations to enhance the benchmark's reach and relevance.

