- The paper presents VEAttack, a novel attack strategy that perturbs image tokens using cosine similarity to compromise LVLM vision encoders.
- It achieves remarkable performance drops, with a 94.5% decrease in image captioning and 75.7% in visual question answering, demonstrating cross-task generalization.
- The method minimizes computational costs by exclusively targeting vision encoders, offering scalable insights into LVLM vulnerabilities.
VEAttack: Downstream-agnostic Vision Encoder Attack against Large Vision LLMs
The paper "VEAttack: Downstream-agnostic Vision Encoder Attack against Large Vision LLMs" (2505.17440) explores a novel approach to compromising the integrity of Large Vision-LLMs (LVLMs) through targeted attacks on their vision encoders. LVLMs, which integrate vision encoders with LLMs, are vulnerable to adversarial perturbations, particularly from the vision inputs that propagate errors into multimodal outputs. VEAttack strategically attacks the vision encoder, minimizing computational overhead, and demonstrating generalization across diverse tasks such as image captioning and visual question answering.
Attack Overview
VEAttack addresses the limitations of traditional white-box attacks, which often rely on full-model access and are task-specific. These attacks require significant gradient computations, making them computationally expensive, particularly in LVLMs designed for multiple downstream tasks. By solely targeting the vision encoder and optimizing perturbations through cosine similarity between clean and perturbed visual features, VEAttack presents a significant reduction in dependency on task-specific data and computational costs, achieving enhanced attack effectiveness across diverse LVLM applications.

Figure 1: The illustration of different attack paradigms where the white modules are accessible to the attacker, while the dark gray modules are inaccessible during the attack.
Methodology
The central innovation of VEAttack is its focus on perturbing image tokens rather than class tokens. Given that LVLMs utilize image token features during inference, this strategy ensures broader and more effective perturbations. The attack objective is redefined from full access on LVLMs to a vision encoder-centric approach, leveraging the shared representations of vision encoders across tasks to improve generalization. By minimizing the cosine similarity of encoded clean and perturbed images, VEAttack robustly affects downstream tasks without specific task dependencies.
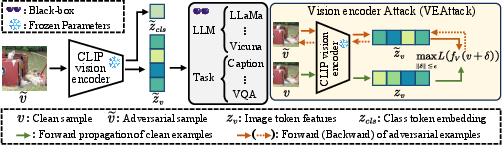
Figure 2: The illustration of the overall framework of VEAttack, where it solely attacks the vision encoder of LVLMs within a downstream-agnostic context.
Experimental Results
Empirical evaluations reveal the effectiveness of VEAttack across several benchmark datasets. It achieves extreme performance degradation on image captioning tasks by 94.5% and on visual question answering by 75.7%. Moreover, VEAttack demonstrates strong transferability across tasks, aligning with Proposition 1's theoretical expectations regarding lower-bound perturbation impacts on aligned features.

Figure 3: Quantitative results on image captioning of clean samples, traditional white-box APGD attack, and VEAttack on LLaVa1.5-7B.
Observations
VEAttack reveals several key insights into LVLM vulnerabilities:
- Hidden Layer Variation: Attacking the vision encoder induces notable deviations in the LLM's hidden layers, affecting downstream output.
- Token Attention Differential: There is a significant differential in how LVLMs pay attention to image versus instruction tokens across tasks, impacting vulnerability.
- Möbius Band Phenomenon: Strengthening the robustness of vision encoders can inadvertently enhance the adversarial sample transferability, suggesting an intertwined pathway of robustness and vulnerability.
- Low Sensitivity to Attack Steps: Demonstrates efficiency as reducing the number of attack iterations does not significantly impact VEAttack's effectiveness.
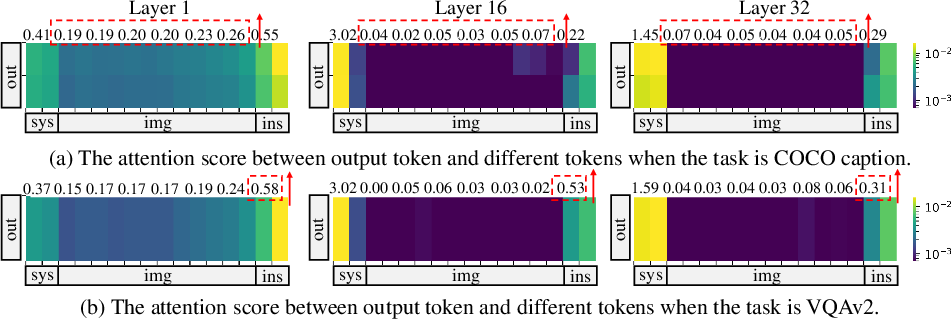
Figure 4: Illustration of attention maps across different layers of the LLM for two tasks.
Conclusion
VEAttack offers a computationally efficient and highly effective adversarial attack strategy against LVLMs by targeting vision encoders in a downstream-agnostic manner. This method not only highlights the vulnerabilities of LVLMs to adversarial inputs but also proposes a scalable attack mechanism, reducing traditional computation overheads by an order of magnitude. Future work can focus on developing countermeasures to improve the robustness of LVLMs against such attacks, potentially by reinforcing vision encoder resistance without sacrificing system performance.

