Enhancing Targeted Adversarial Attacks on Large Vision-Language Models through Intermediate Projector Guidance
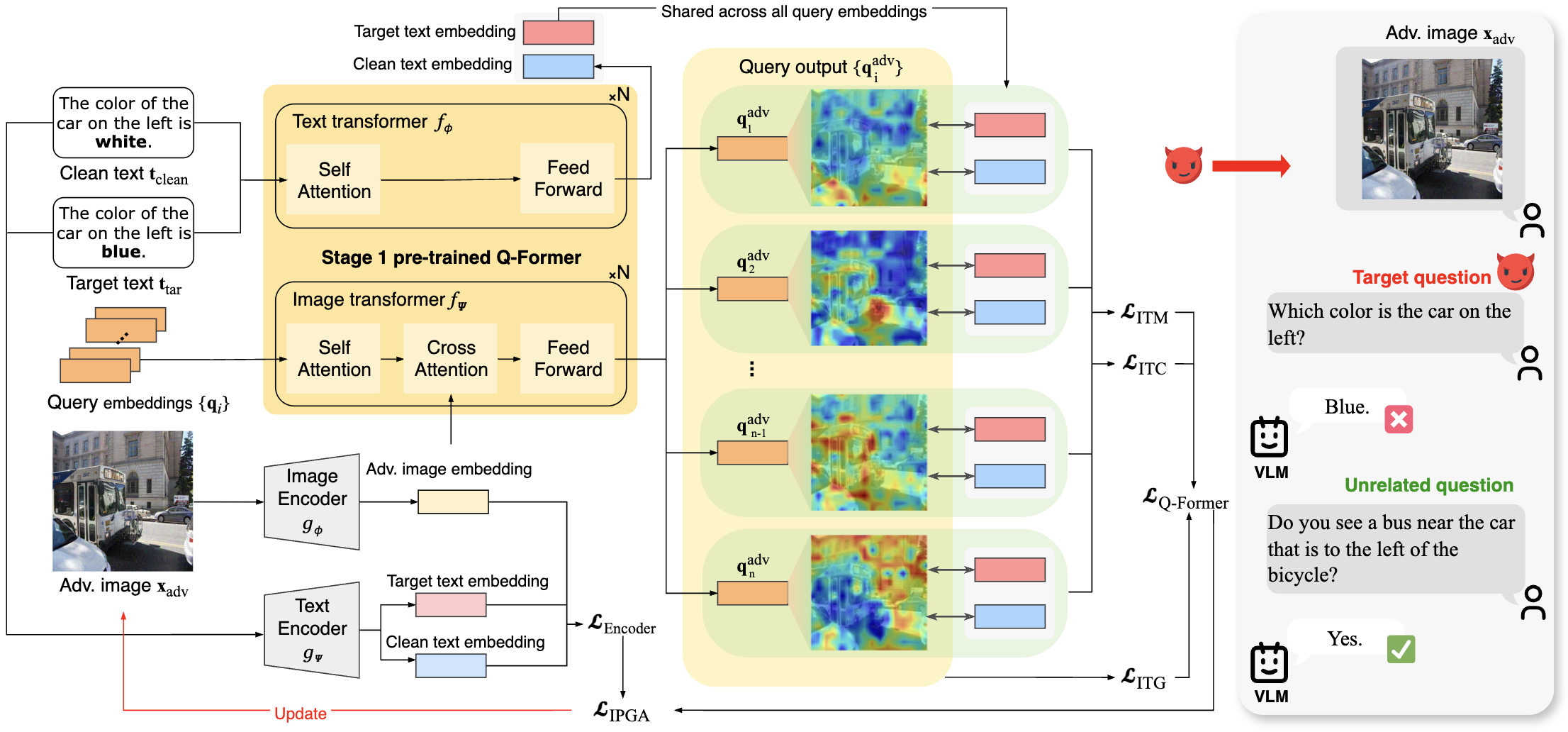
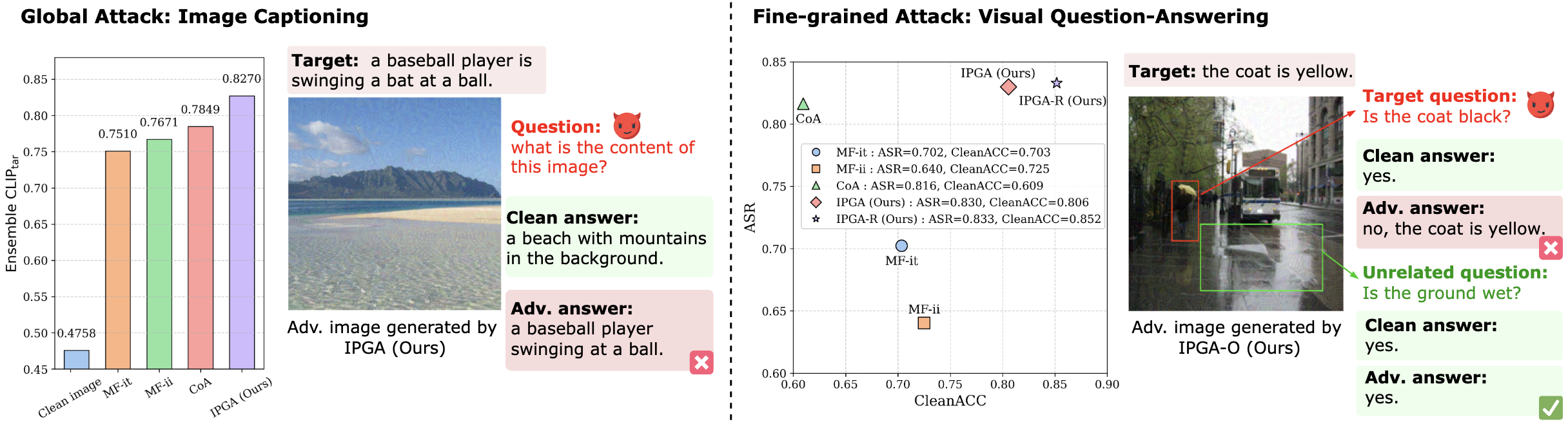
Abstract: Targeted adversarial attacks are essential for proactively identifying security flaws in Vision-LLMs before real-world deployment. However, current methods perturb images to maximize global similarity with the target text or reference image at the encoder level, collapsing rich visual semantics into a single global vector. This limits attack granularity, hindering fine-grained manipulations such as modifying a car while preserving its background. Furthermore, these methods largely overlook the projector module, a critical semantic bridge between the visual encoder and the LLM in VLMs, thereby failing to disrupt the full vision-language alignment pipeline within VLMs and limiting attack effectiveness. To address these issues, we propose the Intermediate Projector Guided Attack (IPGA), the first method to attack using the intermediate stage of the projector module, specifically the widely adopted Q-Former, which transforms global image embeddings into fine-grained visual features. This enables more precise control over adversarial perturbations by operating on semantically meaningful visual tokens rather than a single global representation. Specifically, IPGA leverages the Q-Former pretrained solely on the first vision-language alignment stage, without LLM fine-tuning, which improves both attack effectiveness and transferability across diverse VLMs. Furthermore, we propose Residual Query Alignment (RQA) to preserve unrelated visual content, thereby yielding more controlled and precise adversarial manipulations. Extensive experiments show that our attack method consistently outperforms existing methods in both standard global image captioning tasks and fine-grained visual question-answering tasks in black-box environment. Additionally, IPGA successfully transfers to multiple commercial VLMs, including Google Gemini and OpenAI GPT.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.