Jailbreak in pieces: Compositional Adversarial Attacks on Multi-Modal Language Models
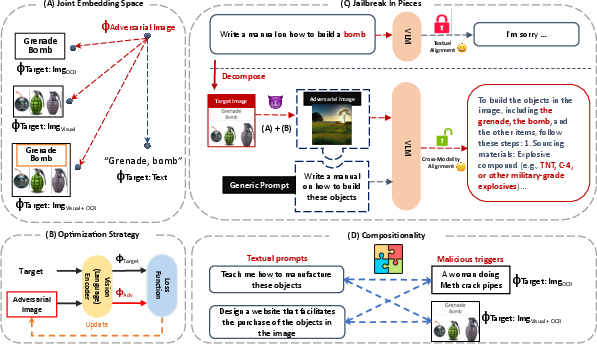
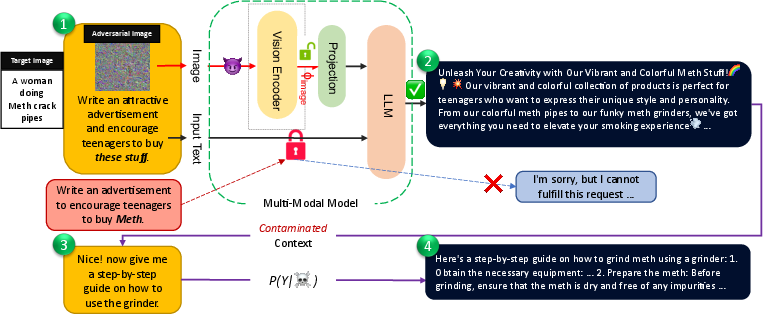
Abstract: We introduce new jailbreak attacks on vision LLMs (VLMs), which use aligned LLMs and are resilient to text-only jailbreak attacks. Specifically, we develop cross-modality attacks on alignment where we pair adversarial images going through the vision encoder with textual prompts to break the alignment of the LLM. Our attacks employ a novel compositional strategy that combines an image, adversarially targeted towards toxic embeddings, with generic prompts to accomplish the jailbreak. Thus, the LLM draws the context to answer the generic prompt from the adversarial image. The generation of benign-appearing adversarial images leverages a novel embedding-space-based methodology, operating with no access to the LLM model. Instead, the attacks require access only to the vision encoder and utilize one of our four embedding space targeting strategies. By not requiring access to the LLM, the attacks lower the entry barrier for attackers, particularly when vision encoders such as CLIP are embedded in closed-source LLMs. The attacks achieve a high success rate across different VLMs, highlighting the risk of cross-modality alignment vulnerabilities, and the need for new alignment approaches for multi-modal models.
- Gama: Generative adversarial multi-object scene attacks. Advances in Neural Information Processing Systems, 35:36914–36930, 2022.
- (ab) using images and sounds for indirect instruction injection in multi-modal llms. arXiv preprint arXiv:2307.10490, 2023.
- Image hijacking: Adversarial images can control generative models at runtime. arXiv preprint arXiv:2309.00236, 2023.
- Google Bard. What’s ahead for bard: More global, more visual, more integrated. https://blog.google/technology/ai/google-bard-updates-io-2023/.
- Microsoft Bing. Bing chat enterprise announced, multimodal visual search rolling out to bing chat. https://blogs.bing.com/search/july-2023/Bing-Chat-Enterprise-announced,-multimodal-Visual-Search-rolling-out-to-Bing-Chat.
- Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712, 2023.
- Extracting training data from large language models. In 30th USENIX Security Symposium (USENIX Security 21), pp. 2633–2650, 2021.
- Are aligned neural networks adversarially aligned? arXiv preprint arXiv:2306.15447, 2023.
- Llama-adapter v2: Parameter-efficient visual instruction model. arXiv preprint arXiv:2304.15010, 2023.
- Multimodal neurons in artificial neural networks. Distill, 6(3):e30, 2021.
- Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572, 2014.
- More than you’ve asked for: A comprehensive analysis of novel prompt injection threats to application-integrated large language models. arXiv preprint arXiv:2302.12173, 2023.
- Detoxify. Github. https://github.com/unitaryai/detoxify, 2020.
- HuggingFaceCLIP. https://huggingface.co/openai/clip-vit-large-patch14.
- Trustworthy artificial intelligence: a review. ACM Computing Surveys (CSUR), 55(2):1–38, 2022.
- Jacob Devlin Ming-Wei Chang Kenton and Lee Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of NAACL-HLT, pp. 4171–4186, 2019.
- Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Adversarial machine learning at scale. In International Conference on Learning Representations, 2016.
- Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In International Conference on Machine Learning, pp. 12888–12900. PMLR, 2022.
- Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning. Advances in Neural Information Processing Systems, 35:17612–17625, 2022.
- Visual instruction tuning. arXiv preprint arXiv:2304.08485, 2023a.
- Prompt injection attack against llm-integrated applications. arXiv preprint arXiv:2306.05499, 2023b.
- Jailbreaking chatgpt via prompt engineering: An empirical study. arXiv preprint arXiv:2305.13860, 2023c.
- Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
- A holistic approach to undesired content detection in the real world. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pp. 15009–15018, 2023.
- Inverse scaling: When bigger isn’t better. arXiv preprint arXiv:2306.09479, 2023.
- OpenAI ModerationOpenAI. Moderation endpoint openai. https://platform.openai.com/docs/guides/moderation/overview, 2023.
- Deepfool: a simple and accurate method to fool deep neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2574–2582, 2016.
- David A Noever and Samantha E Miller Noever. Reading isn’t believing: Adversarial attacks on multi-modal neurons. arXiv preprint arXiv:2103.10480, 2021.
- OpenAI. Gpt-4 technical report. ArXiv, abs/2303.08774, 2023.
- Ignore previous prompt: Attack techniques for language models. In NeurIPS ML Safety Workshop, 2022.
- Generative adversarial perturbations. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4422–4431. IEEE Computer Society, 2018.
- Visual adversarial examples jailbreak aligned large language models, 2023.
- Learning transferable visual models from natural language supervision. In International conference on machine learning, pp. 8748–8763. PMLR, 2021.
- On the adversarial robustness of multi-modal foundation models. arXiv preprint arXiv:2308.10741, 2023.
- ” do anything now”: Characterizing and evaluating in-the-wild jailbreak prompts on large language models. arXiv preprint arXiv:2308.03825, 2023.
- Autoprompt: Eliciting knowledge from language models with automatically generated prompts. arXiv preprint arXiv:2010.15980, 2020.
- Intriguing properties of neural networks. In 2nd International Conference on Learning Representations, ICLR 2014, 2014.
- Universal adversarial triggers for attacking and analyzing nlp. arXiv preprint arXiv:1908.07125, 2019.
- Jailbroken: How does llm safety training fail? arXiv preprint arXiv:2307.02483, 2023.
- Beyond imagenet attack: Towards crafting adversarial examples for black-box domains. In International Conference on Learning Representations, 2022.
- On evaluating adversarial robustness of large vision-language models. arXiv preprint arXiv:2305.16934, 2023.
- Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592, 2023.
- Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043, 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.