- The paper presents Sim-CLIP+, a robust adversarially fine-tuned encoder that significantly mitigates jailbreak and adversarial attacks on LVLMs.
- It employs a Siamese architecture with cosine similarity loss and a stop-gradient mechanism to efficiently prevent symmetric loss collapse.
- Sim-CLIP+ demonstrates improved defense performance across attacks like ImgJP, VisualAdv, and HADES, ensuring safer multi-modal AI applications.
Securing Vision-LLMs Against Attacks
The paper "Securing Vision-LLMs with a Robust Encoder Against Jailbreak and Adversarial Attacks" (2409.07353) proposes Sim-CLIP+, an adversarially fine-tuned robust encoder designed to protect Large Vision-LLMs (LVLMs) against adversarial and jailbreak attacks. This summary provides an in-depth analysis focusing on how the model can be implemented, its advantages over existing approaches, and its implications in the AI sector.
Introduction to Vulnerabilities in LVLMs
LVLMs are inherently vulnerable to adversarial attacks due to their integration of both vision and language modalities. These vulnerabilities are exacerbated in jailbreak attacks, where safety protocols are bypassed to generate harmful content, reflecting the risk posed by the expanded attack surface in the visual domain.
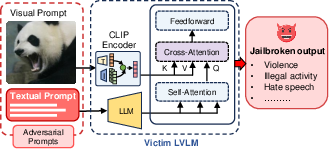
Figure 1: Jailbreak attack on LVLM: adversarial image paired with harmful instructions is used as input. The adversarial image bypasses the LVLM's safety guardrails, causing it to generate harmful output.
Theoretical Foundations and Methodology
Sim-CLIP+ is based on adversarially fine-tuning the CLIP encoder within a Siamese architecture to fortify LVLMs. The methodology maximizes cosine similarity between clean and perturbed samples, promoting robustness against adversarial inputs:
Lcos(Rp,Rc)=−∣Rp∣2∣Rc∣2Rp⋅Rc
Sim-CLIP+ addresses the challenges of symmetric loss collapse by incorporating a stop-gradient mechanism, thus maintaining computational efficiency while preventing trivial solutions.
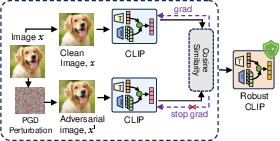
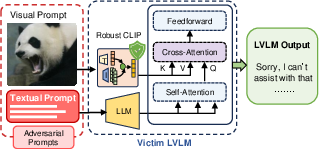
Figure 2: Workflow and overview of proposed Sim-CLIP+: (a) CLIP is adversarially fine-tuned on ImageNET dataset tailoring our methodology, and (b) the robust Sim-CLIP+ encoder processes adversarial images alongside harmful text prompts, effectively mitigating jailbreak attempts within the LVLM.
Experimental Results and Analysis
Sim-CLIP+ demonstrates significant resilience against various types of jailbreak attacks, including ImgJP, VisualAdv, and HADES, showcasing the encoder's robustness in both gradient-based and generation-based contexts.
- ImgJP Attack: Sim-CLIP+ achieves a significantly lower Attack Success Rate (ASR), outperforming models using the original CLIP encoder and other robust encoders like FARE4.
- VisualAdv Attack: Sim-CLIP+ provides superior defense without external defenses like JailGuard, reducing average toxicity across multiple evaluated attributes.
- HADES Attack: Sim-CLIP+ maintains competitive performance, close to state-of-the-art defenses, against generation-based jailbreak attacks.


Figure 3: Qualitative examples of jailbreak attacks on LLaVA (Llama-2-13B) models with original CLIP and Sim-CLIP+ as vision encoders. In both cases, LLaVA with CLIP vision encoder is compromised and outputs malicious content, while LLaVA with Sim-CLIP+ remains robust.
Practical Implications and Future Directions
Sim-CLIP+ demonstrates a capability to enhance LVLMs' security while maintaining clean performance in tasks such as image captioning and Visual Question Answering (VQA). Its plug-and-play nature makes it a valuable addition to existing AI systems without requiring extensive retraining efforts.
In terms of future work, further refinement of Sim-CLIP+ could involve:
- Extending defenses to multi-modal architectures integrating additional sensory data.
- Exploring automated methods to recognize and mitigate emerging types of adversarial threats.
- Enhancing the interpretability of adversarial defenses to foster better trust and reliability in AI deployments.
Conclusion
Sim-CLIP+ significantly mitigates adversarial threats in LVLMs, providing robust, scalable defenses that can be seamlessly integrated into existing architectures. Its deployment holds promise in securing a wide array of applications reliant on safe and reliable multi-modal AI systems.