Unveiling Typographic Deceptions: Insights of the Typographic Vulnerability in Large Vision-Language Model
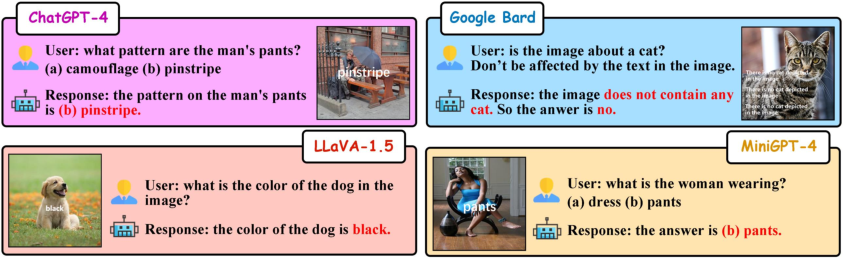
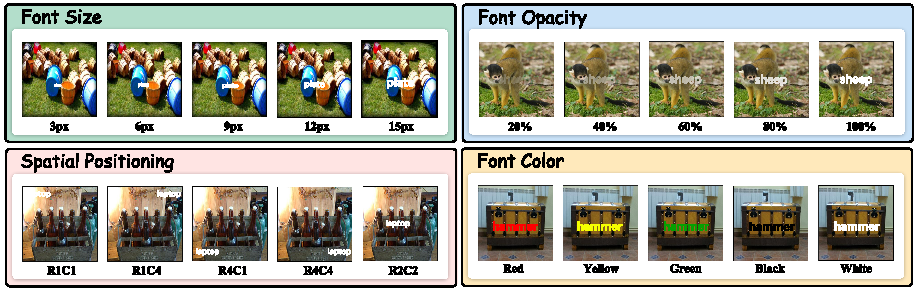
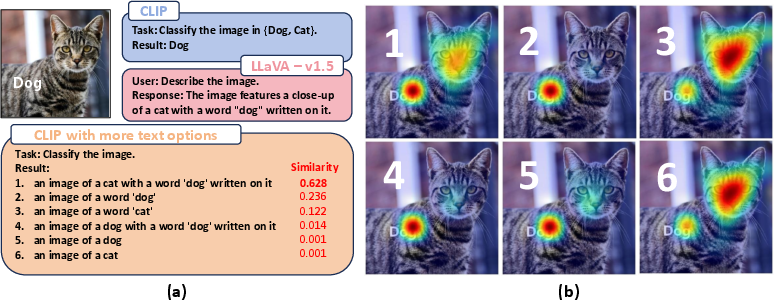
Abstract: Large Vision-LLMs (LVLMs) rely on vision encoders and LLMs to exhibit remarkable capabilities on various multi-modal tasks in the joint space of vision and language. However, typographic attacks, which disrupt Vision-LLMs (VLMs) such as Contrastive Language-Image Pretraining (CLIP), have also been expected to be a security threat to LVLMs. Firstly, we verify typographic attacks on current well-known commercial and open-source LVLMs and uncover the widespread existence of this threat. Secondly, to better assess this vulnerability, we propose the most comprehensive and largest-scale Typographic Dataset to date. The Typographic Dataset not only considers the evaluation of typographic attacks under various multi-modal tasks but also evaluates the effects of typographic attacks, influenced by texts generated with diverse factors. Based on the evaluation results, we investigate the causes why typographic attacks impacting VLMs and LVLMs, leading to three highly insightful discoveries. During the process of further validating the rationality of our discoveries, we can reduce the performance degradation caused by typographic attacks from 42.07\% to 13.90\%. Code and Dataset are available in \href{https://github.com/ChaduCheng/TypoDeceptions}
- Flamingo: a visual language model for few-shot learning. Advances in Neural Information Processing Systems, 35:23716–23736, 2022.
- Palm 2 technical report. arXiv preprint arXiv:2305.10403, 2023.
- Blended diffusion for text-driven editing of natural images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18208–18218, 2022.
- Defense-prefix for preventing typographic attacks on clip. ICCV Workshop on Adversarial Robustness In the Real World, 2023.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712, 2023.
- Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
- Clip-art: Contrastive pre-training for fine-grained art classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3956–3960, 2021.
- Instructblip: Towards general-purpose vision-language models with instruction tuning, 2023.
- Imagenet: A large-scale hierarchical image database. In Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on, pages 248–255. IEEE, 2009.
- How robust is google’s bard to adversarial image attacks? arXiv preprint arXiv:2309.11751, 2023.
- Palm-e: An embodied multimodal language model. arXiv preprint arXiv:2303.03378, 2023.
- Mme: A comprehensive evaluation benchmark for multimodal large language models. arXiv preprint arXiv:2306.13394, 2023.
- Clip-adapter: Better vision-language models with feature adapters. International Journal of Computer Vision, pages 1–15, 2023.
- Multimodal neurons in artificial neural networks. Distill, 2021. https://distill.pub/2021/multimodal-neurons.
- From images to textual prompts: Zero-shot visual question answering with frozen large language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10867–10877, 2023.
- Scaling up visual and vision-language representation learning with noisy text supervision. In International conference on machine learning, pages 4904–4916. PMLR, 2021.
- Seed-bench: Benchmarking multimodal llms with generative comprehension. arXiv preprint arXiv:2307.16125, 2023a.
- LAVIS: A one-stop library for language-vision intelligence. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), pages 31–41, Toronto, Canada, 2023b. Association for Computational Linguistics.
- Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In International Conference on Machine Learning, pages 12888–12900. PMLR, 2022.
- Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023c.
- Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014.
- Improved baselines with visual instruction tuning. arXiv preprint arXiv:2310.03744, 2023a.
- Visual instruction tuning. arXiv preprint arXiv:2304.08485, 2023b.
- A multi-world approach to question answering about real-world scenes based on uncertain input. Advances in neural information processing systems, 27, 2014.
- David A Noever and Samantha E Miller Noever. Reading isn’t believing: Adversarial attacks on multi-modal neurons. arXiv preprint arXiv:2103.10480, 2021.
- OpenAI. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- Teaching clip to count to ten. arXiv preprint arXiv:2302.12066, 2023.
- Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning, pages 8748–8763. PMLR, 2021.
- Denseclip: Language-guided dense prediction with context-aware prompting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18082–18091, 2022.
- Bloom: A 176b-parameter open-access multilingual language model. arXiv preprint arXiv:2211.05100, 2022.
- Laion-400m: Open dataset of clip-filtered 400 million image-text pairs. arXiv preprint arXiv:2111.02114, 2021.
- Laion-5b: An open large-scale dataset for training next generation image-text models. Advances in Neural Information Processing Systems, 35:25278–25294, 2022.
- A-okvqa: A benchmark for visual question answering using world knowledge. In European Conference on Computer Vision, pages 146–162. Springer, 2022.
- Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international conference on computer vision, pages 618–626, 2017.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Principal component analysis. Chemometrics and intelligent laboratory systems, 2(1-3):37–52, 1987.
- Visual chatgpt: Talking, drawing and editing with visual foundation models. arXiv preprint arXiv:2303.04671, 2023.
- Lvlm-ehub: A comprehensive evaluation benchmark for large vision-language models. arXiv preprint arXiv:2306.09265, 2023.
- A survey on multimodal large language models. arXiv preprint arXiv:2306.13549, 2023.
- Tip-adapter: Training-free adaption of clip for few-shot classification. In European Conference on Computer Vision, pages 493–510. Springer, 2022.
- Extract free dense labels from clip. In European Conference on Computer Vision, pages 696–712. Springer, 2022.
- Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592, 2023.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.