- The paper presents a novel pre-training strategy that offloads entity-level factual knowledge to an external database.
- The methodology reduces memorization by excluding factual tokens from loss computation, resulting in lower perplexity during training.
- Empirical evaluations demonstrate enhanced factual precision and efficient unlearning while maintaining robust natural language understanding.
Pre-training Limited Memory LLMs with Internal and External Knowledge
This paper introduces a novel framework for LLM pre-training that strategically offloads factual knowledge into an external database rather than encoding it in model parameters. This approach generates Large Memory LLMs (LmLms) that efficiently manage factual knowledge and maintain language processing capabilities.
Introduction to LmLms
LmLms are designed to separate factual knowledge from linguistic competency by leveraging external databases to store entity-level factual information. Unlike conventional LLMs, which entangle knowledge within weights, LmLms facilitate explicit retrieval of facts, enhancing the model's ability to ground outputs on verifiable knowledge.

Figure 1: A schematic illustration of LmLm. Unlike RAG (left), which exclusively adds knowledge from external sources, LmLm offloads knowledge from the LLMs to the external database during pre-training.
Data Preparation and Annotation
Data preparation involves annotating the training corpus with database lookup calls for entity-level facts, efficiently creating a structured external database. This involves distilling annotations from GPT-4o utilizing a small, specialized Annotator model.

Figure 2: Training the Annotator model. We distill high-quality annotations from GPT-4o into a lightweight model that learns to identify and externalize factual knowledge from raw pre-training text, enabling scalable annotation of the full corpus.
Pre-training Methodology
The pre-training strategy excludes tokens corresponding to retrieved factual values from loss computation. This encourages the model to perform database queries for specific entity-related facts, effectively reducing dependency on memorization. Empirical results show lower perplexity during training when leveraging secure factual lookups, demonstrating enhanced training efficiency.
Inference Mechanism
During inference, LmLms generate text with interleaved database queries, triggering lookups when necessary. This ensures that retrieved factual information appropriately grounds generated outputs. This innovative mechanism offers efficient real-time lookups and integrates retrieved facts seamlessly into text generation.
Experimental Evaluation
Factual Precision and Efficiency
Experiments reveal that LmLms improve factual precision without degrading general NLU performance. Evaluations on benchmarks like FactScore and T-REx show significant gains in factual accuracy, even when compared to larger models.
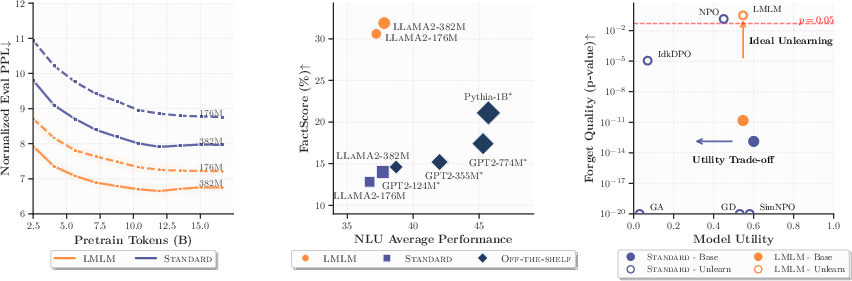
Figure 3: Results overview. (Left) LmLm achieves consistently lower perplexity during pre-training, indicating that offloading factual knowledge improves pre-training efficiency. (Middle) LmLm significantly improves factual precision over its Standard counterparts while maintaining NLU performance. (Right) On the TOFU machine unlearning benchmark, LmLm forgets targeted facts while preserving general model utility.
Machine Unlearning Capabilities
LmLms inherently support simple and efficient unlearning by removing entries from the external database. On the TOFU benchmark, LmLms demonstrate instant forgetting of targeted facts without compromising general model performance, highlighting the practical scalability and adaptability of LmLms.
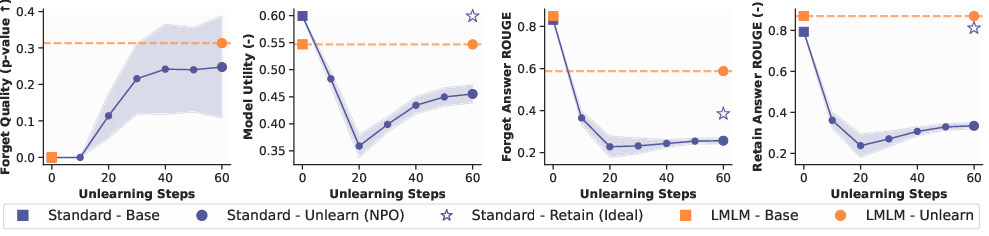
Figure 4: Evaluation of Machine Unlearning. We compare LmLm with NPO on the TOFU benchmark. Unlike prior methods, LmLm performs unlearning without any additional training. (a–b) Forget quality vs. utility trade-off. LmLm achieves ideal forgetting (p-value > 0.05) without sacrificing general utility. (c–d) LmLm retains knowledge outside the forget set, unlike other methods that degrade retain-set performance due to parameter entanglement.
Discussion
Implications for Scaling and Knowledge Management
LmLms offer a parameter-efficient approach to maintaining high factual precision by externalizing knowledge. This model architecture presents integrations with fields like knowledge representation and mechanistic interpretability. These capabilities suggest a transformative impact on deploying LLMs in fact-sensitive scenarios, ensuring verifiable updates and scalable learning.
Conclusion
The introduction of LmLms represents a shift towards utilizing structured external memory for factual knowledge management, enhancing both factual accuracy and linguistic competency. This framework opens avenues for next-generation LLMs, facilitating real-time, efficient knowledge updates, and improving robustness against factual inaccuracies.
Overall, LmLms demonstrate a promising direction for LLM development, emphasizing efficient use of model capacity while ensuring precise control and verification over factual content.