- The paper introduces the IEMF framework, a dynamic fusion mechanism inspired by biological inverse effectiveness that adapts learning rates based on the reliability of unimodal inputs.
- It demonstrates significant improvements in audio-visual tasks, achieving up to 4% accuracy gains and notable reductions in training computational costs across various architectures.
- The study provides theoretical insights into convergence and generalization, showing enhanced stability and reduced catastrophic forgetting in continual learning scenarios.
Brain-Inspired Multimodal Learning via Inverse Effectiveness Driven Fusion
Introduction
This work investigates the integration of brain-inspired mechanisms into multimodal learning systems within artificial intelligence, focusing specifically on the principle of inverse effectiveness observed in biological multisensory integration. Traditional artificial neural networks (ANNs) and spiking neural networks (SNNs) used for multimodal fusion typically employ static fusion schemes and do not adaptively respond to changing input reliability. In contrast, biological systems exhibit dynamic integration, strengthening fusion when unimodal cues are weak—an effect known as inverse effectiveness. This phenomenon enables robust perception under noisy or uncertain conditions.
The authors introduce the Inverse Effectiveness driven Multimodal Fusion (IEMF) framework. IEMF dynamically adjusts fusion module update rates according to the informativeness of unimodal and integrated multimodal signals, such that fusion is accentuated when unimodal streams are weak and suppressed otherwise. The mechanism, implemented as a coefficient on the fusion gradient during backpropagation, can be effectively incorporated into both ANNs and SNNs, with computational and performance gains validated across diverse audio-visual tasks.
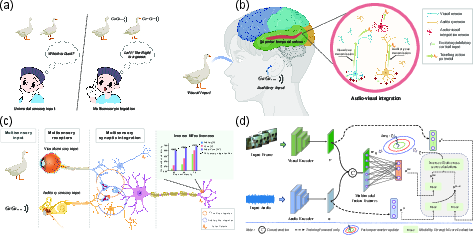
Figure 1: Multisensory integration in the brain and its computational analogue in IEMF—fusing sensory cues with dynamic weighting based on modality strength scores.
Biological Inspiration: Inverse Effectiveness Principle
Multisensory integration in mammalian cortex, particularly in the superior temporal sulcus (STS), demonstrates that multisensory gain increases when unimodal cues are degraded (inverse effectiveness). Neural evidence indicates potentiated integration in noisy environments—a concept illustrated in Figure 1, panel (c). The IEMF strategy explicitly implements this biological mechanism in artificial systems by dynamically modulating the fusion gradient as a function of unimodal versus multimodal evidence.
The implementation employs a batch-level coefficient ξt defined by the inverse effectiveness principle; specifically, ξt is elevated when the averaged unimodal confidence scores are low relative to the integrated multimodal output. This coefficient multiplicatively scales the fusion parameter update, increasing the learning rate on the fusion path in weak cue regimes and reducing it in strong cue regimes, thus directly encoding the “weak modality, strong fusion” axiom.
Cross-Architecture Universality and Implementation Details
Deployment in ANNs and SNNs
IEMF is demonstrated to generalize across both ANNs (continuous activations) and SNNs (spike-driven, event-based computation). For ANNs, integration is straightforward; ξt modulates standard fusion-layer weight updates under backpropagation. For SNNs, the mechanism is injected into the spike-driven network as an adaptive learning rate for the fusion synapses, compatible with surrogate gradient methodologies required for spike-based backpropagation.
- Network architecture: Visual and audio encoders (e.g., ResNet-18, VideoMAE/AudioMAE) yield latent representations fused via a generic operator (concatenation, MSLR, OGM_GE, LFM). IEMF calculates unimodal probabilities via linear heads and computes ξt per batch.
- Update rule: Only the fusion module’s weights receive the ξt-modulated gradient; unimodal branches remain unaffected.
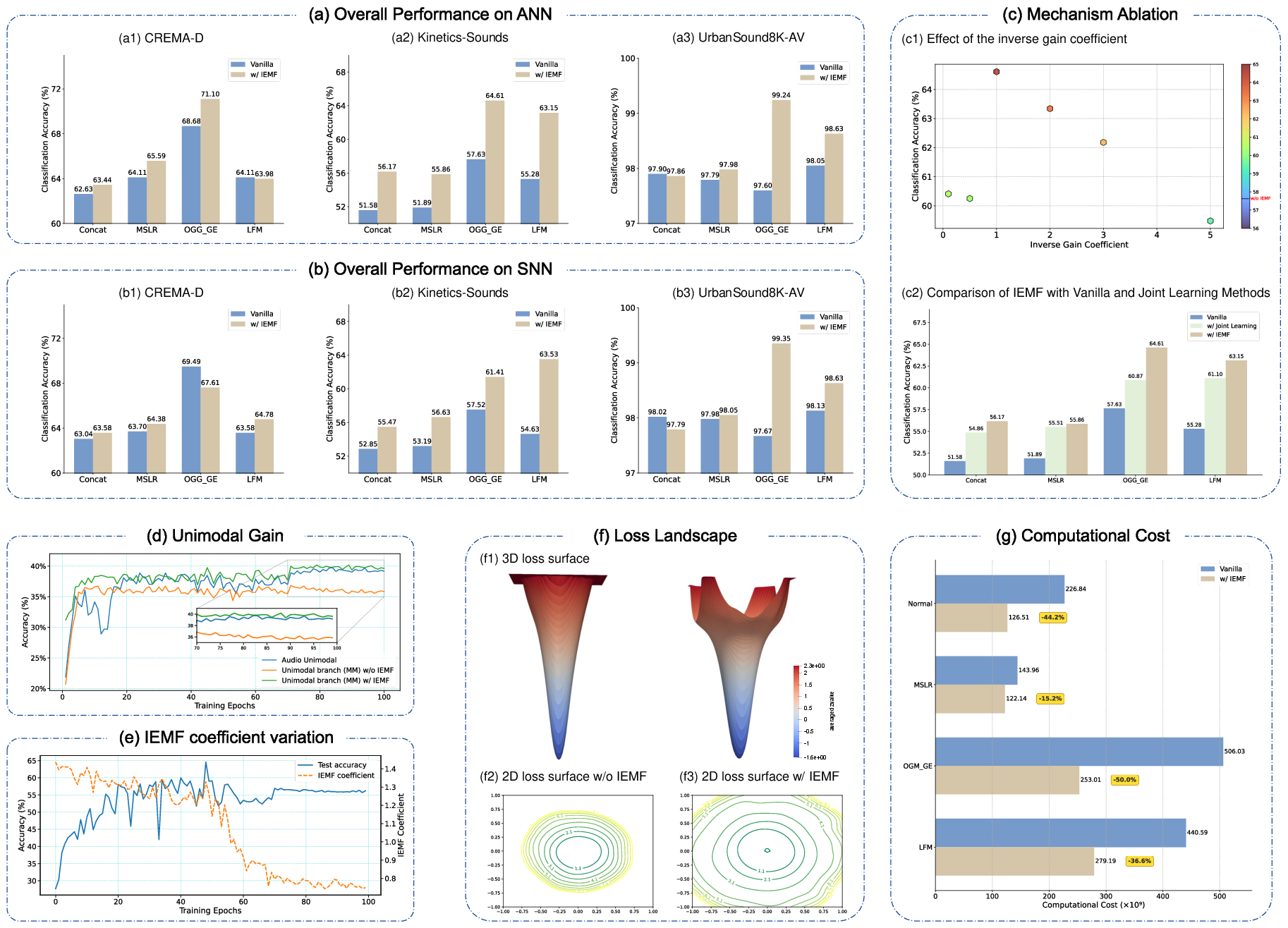
- Computational cost: IEMF introduces negligible overhead, as the principal addition is the calculation of batch means and a simple coefficient.
Empirical Evaluation Across Multimodal Tasks
Audio-Visual Classification
On multiple datasets (CREMA-D, Kinetics-Sounds, UrbanSound8K-AV) and fusion schemes, IEMF consistently yields 1-4% absolute improvements in Top-1 accuracy for challenging benchmarks, with negligible or minor differences in high-accuracy saturation regimes. Notably, on Kinetics-Sounds (ANN, Concat fusion), accuracy rises from 51.58% to 56.17%, and in SNN settings, IEMF enables SNNs to slightly outperform their ANN counterparts when fusion is critical.
Audio-Visual Continual Learning
In class-incremental learning frameworks, IEMF-enhanced models show consistent accuracy improvements (1–3%) and reduced average forgetting rates. Accuracy decay curves are flatter across tasks, indicating improved retention of previous knowledge—a direct result of adaptive regulation of fusion gradients as category/task distributions change incrementally.
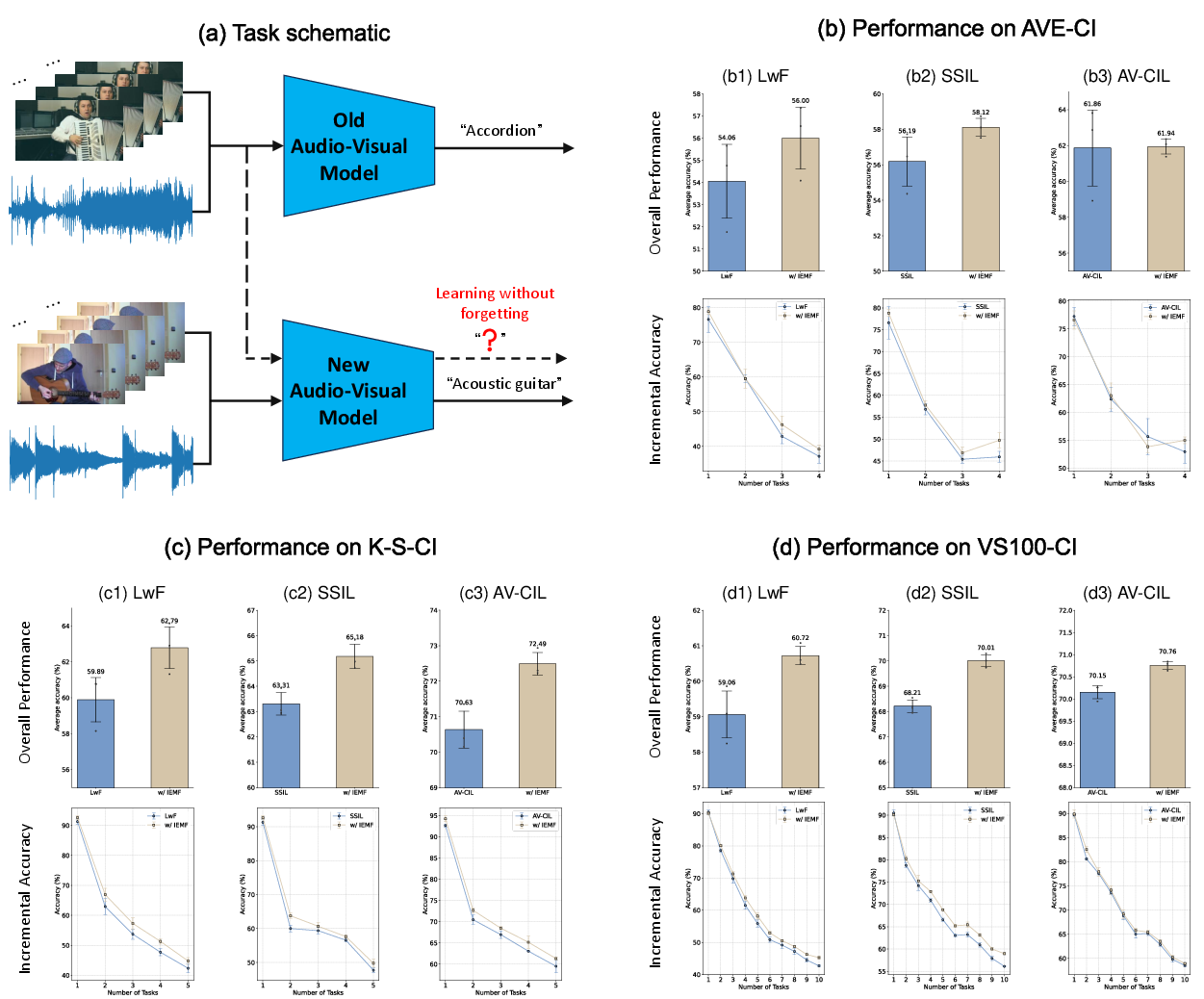
Figure 3: In continual learning, IEMF improves mean accuracy and reduces catastrophic forgetting by adaptively regulating fusion updates.
Audio-Visual Question Answering
In AVQA, IEMF delivers consistent gains across all question types in both simple and advanced QA models (e.g., ST-AVQA). For audio-only and audio-visual questions, improvements of up to 2.6% are observed. Qualitative examples demonstrate improved fine-grained reasoning (instrument counting, spatial localization), suggesting that IEMF’s dynamic fusion is especially beneficial under ambiguous or conflicting cues.
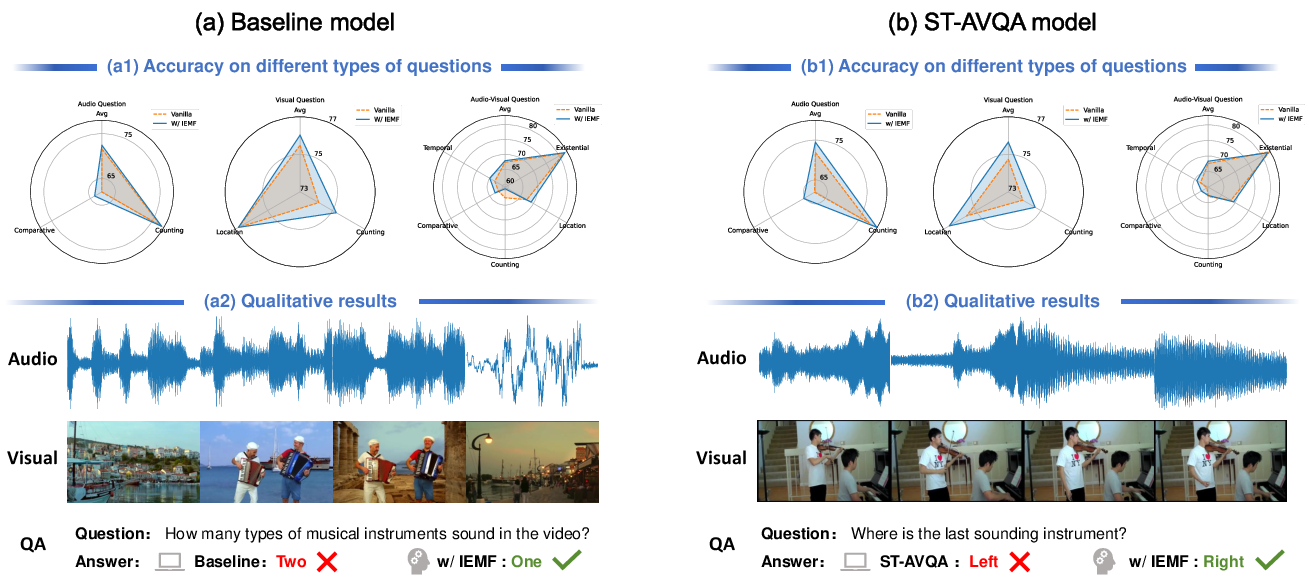
Figure 4: IEMF improves AVQA accuracy across question types and enables robust cross-modal inference in ambiguous settings.
Theoretical Analysis
- Convergence: Under standard smoothness and Lipschitz assumptions, IEMF’s dynamic step-size modulation preferentially reduces sharpness along high-curvature directions, promoting convergence to flatter minima.
- Stability: The fusion pathway’s learning rate is strictly bounded by construction; stability is theoretically guaranteed even for aggressive modulation.
- Modal Compensation: When Sta−v≪Stav (weak unimodal cues), gradient amplification accelerates learning of compensatory fusion weights. Conversely, strong unimodal cues automatically curtail unnecessary fusion updates.
Discussion and Broader Implications
The IEMF strategy directly encodes a biologically validated mechanism of robust perception into AI. Its plug-and-play nature enables broad applicability across architectures and tasks and can be integrated with state-of-the-art fusion modules. The observed computational efficiency is notable: the reduction in optimization steps without performance loss is congruent with metabolic efficiency targets in biological perceptual evolution.
While this study isolates inverse effectiveness—complementing but not replacing other biological constraints such as temporal and spatial congruence—future work can explicitly model these additional factors for asynchronous or spatially misaligned multimodal scenarios.
Limitations and Future Directions
- Task selection: Current evaluation assumes tight temporal and spatial alignment of modalities. Explicit modeling of asynchrony and misalignment remains open.
- Extension: Application to large-scale multimodal language/vision models and streaming data will further elucidate scalability.
Conclusion
The IEMF framework robustly enhances multimodal learning by integrating the inverse effectiveness principle into neural fusion mechanisms. It enables networks to dynamically balance unimodal and integrated evidence, yielding tangible improvements in accuracy, robustness, and computational efficiency. The methodology is applicable to diverse network paradigms (ANNs, SNNs) and multimodal learning benchmarks, supporting the broader thesis that grounded biological principles can catalyze advances in machine learning architectures and their real-world deployments.