Better Together: Leveraging Unpaired Multimodal Data for Stronger Unimodal Models
Abstract: Traditional multimodal learners find unified representations for tasks like visual question answering, but rely heavily on paired datasets. However, an overlooked yet potentially powerful question is: can one leverage auxiliary unpaired multimodal data to directly enhance representation learning in a target modality? We introduce UML: Unpaired Multimodal Learner, a modality-agnostic training paradigm in which a single model alternately processes inputs from different modalities while sharing parameters across them. This design exploits the assumption that different modalities are projections of a shared underlying reality, allowing the model to benefit from cross-modal structure without requiring explicit pairs. Theoretically, under linear data-generating assumptions, we show that unpaired auxiliary data can yield representations strictly more informative about the data-generating process than unimodal training. Empirically, we show that using unpaired data from auxiliary modalities -- such as text, audio, or images -- consistently improves downstream performance across diverse unimodal targets such as image and audio. Our project page: https://unpaired-multimodal.github.io/
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
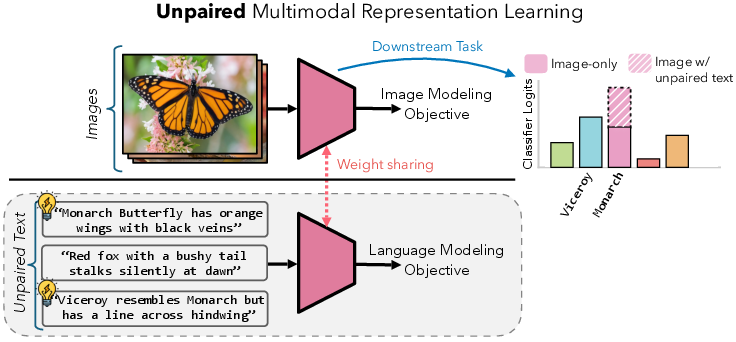
This paper asks a simple but powerful question: can learning from different types of data (like pictures, sounds, and text) make a single-type model (like an image model) better—even if the different types aren’t matched up in pairs? The authors say yes. They introduce a way to train models, called UML (Unpaired Multimodal Learning), that lets a model learn from unpaired image, text, and audio data together to improve how well it understands just one of them (like images).
What questions does the paper ask?
- Can data from another modality (like text) improve an image model even when you don’t have image–caption pairs?
- Is there a simple way to make this work in practice?
- Does this help across many tasks (like classification or robustness to data shifts)?
- Can we measure how much one picture is “worth” compared to a certain number of words for training?
- Do models naturally learn “shared concepts” across modalities—even without paired examples?
How did the researchers approach it?
The key idea: share one brain across different senses
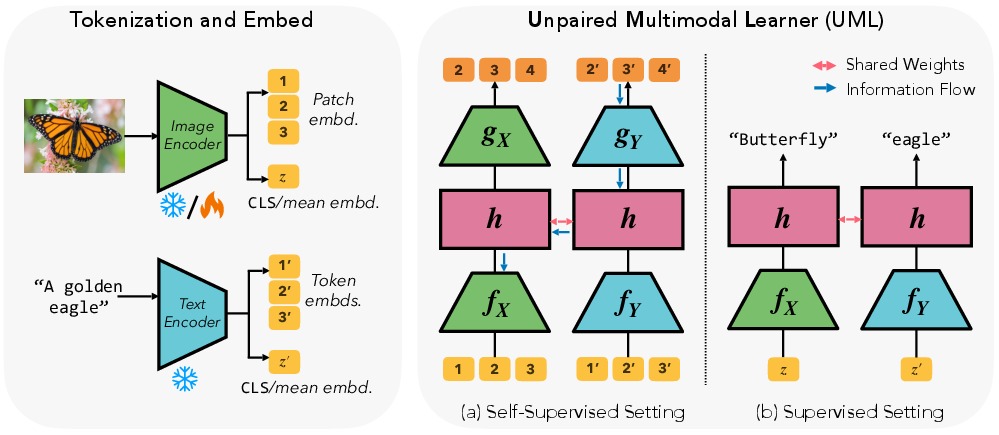
Imagine you’re learning about the world using vision and language. Even if your stories (text) don’t describe your exact photos, both still talk about the same world. UML gives a model one shared “brain” (shared weights) that is trained on multiple modalities. Each modality uses its own “eyes” or “ears” (encoders) to turn raw data into vectors, but the core layers in the middle are shared. This lets lessons from text help the shared brain, which then improves the image pathway too.
- Unpaired means: the image set and the text set aren’t matched item-by-item. They’re just separate collections.
Two training modes
- Supervised: When labels exist (like “cat,” “car”), images and texts each train through the same shared classifier head, but with their own labels. Because the head is shared, what the text teaches helps the image side.
- Self-supervised: When labels don’t exist, each modality tries to predict or reconstruct parts of itself (like next word or missing image patches) using a shared middle network. The shared layers get “dual training” from both modalities, improving general understanding.
At test time, you only use the target modality (e.g., images). The extra pathway (e.g., text) is not needed.
The theory in plain words
The authors use a simple math model to show why this works:
- Think of reality as a shared set of hidden factors (like the true concepts out there). Images show some parts of that, text shows others.
- When you combine learning signals from both, your estimate of the shared truth becomes sharper (your “guess gets less wobbly”).
- They formalize this using a measure called Fisher information—think of it as how confidently the data narrows down the right answer. Adding unpaired text increases that confidence for the shared concepts.
- Sometimes, one sample from another modality (like one sentence) can teach you more than one extra sample of the same modality (like one more image) if it covers a “blind spot.”
What did they find?
Here are the main results in everyday terms:
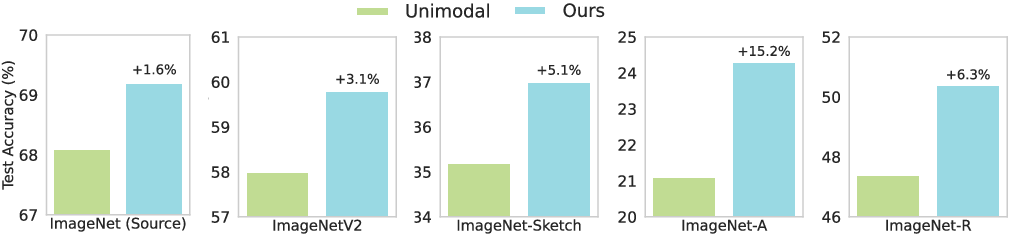
- Better accuracy with unpaired help: Image models trained with extra unpaired text or audio performed better on many benchmarks (including fine-grained tasks like recognizing car or aircraft types).
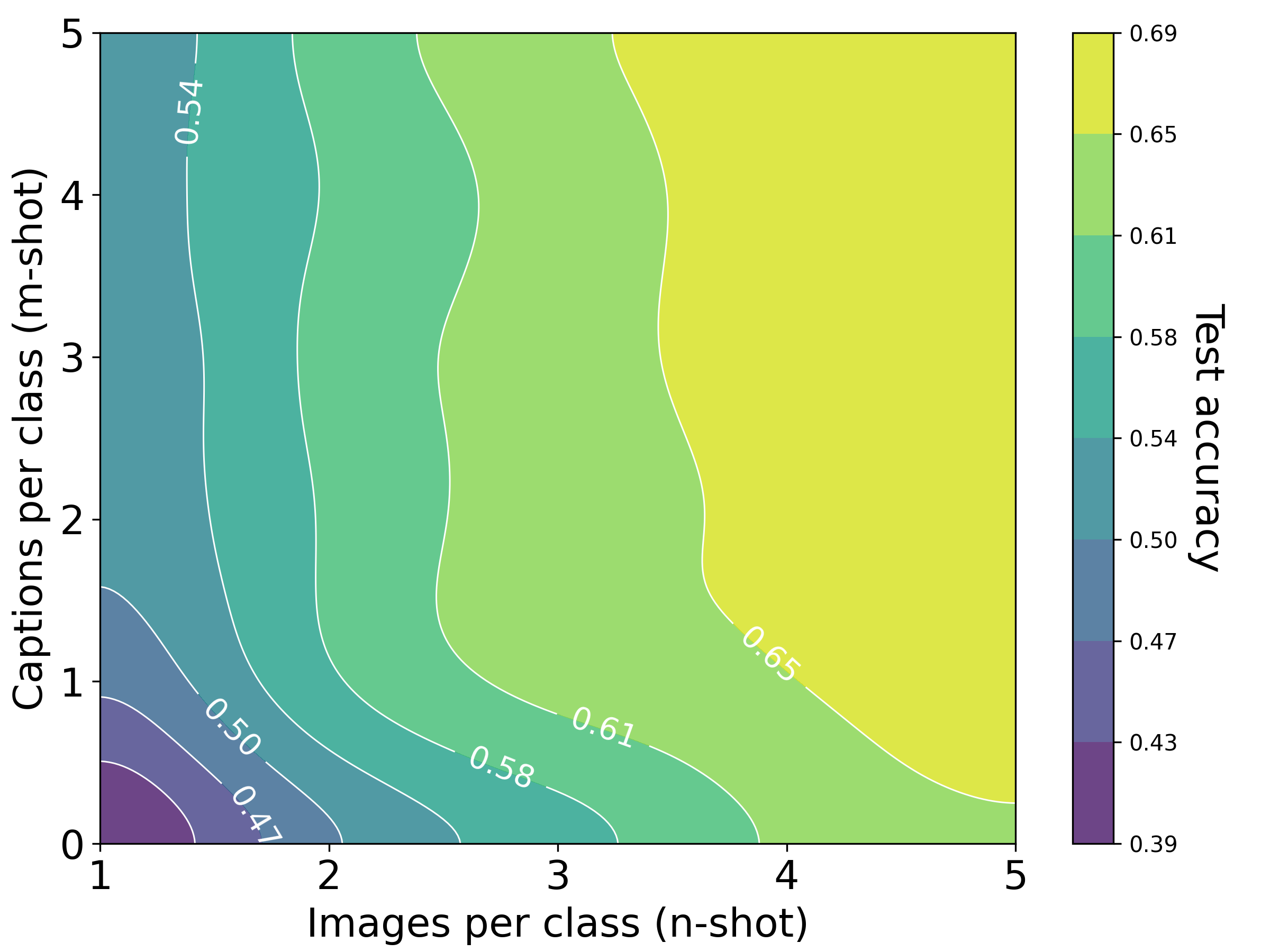
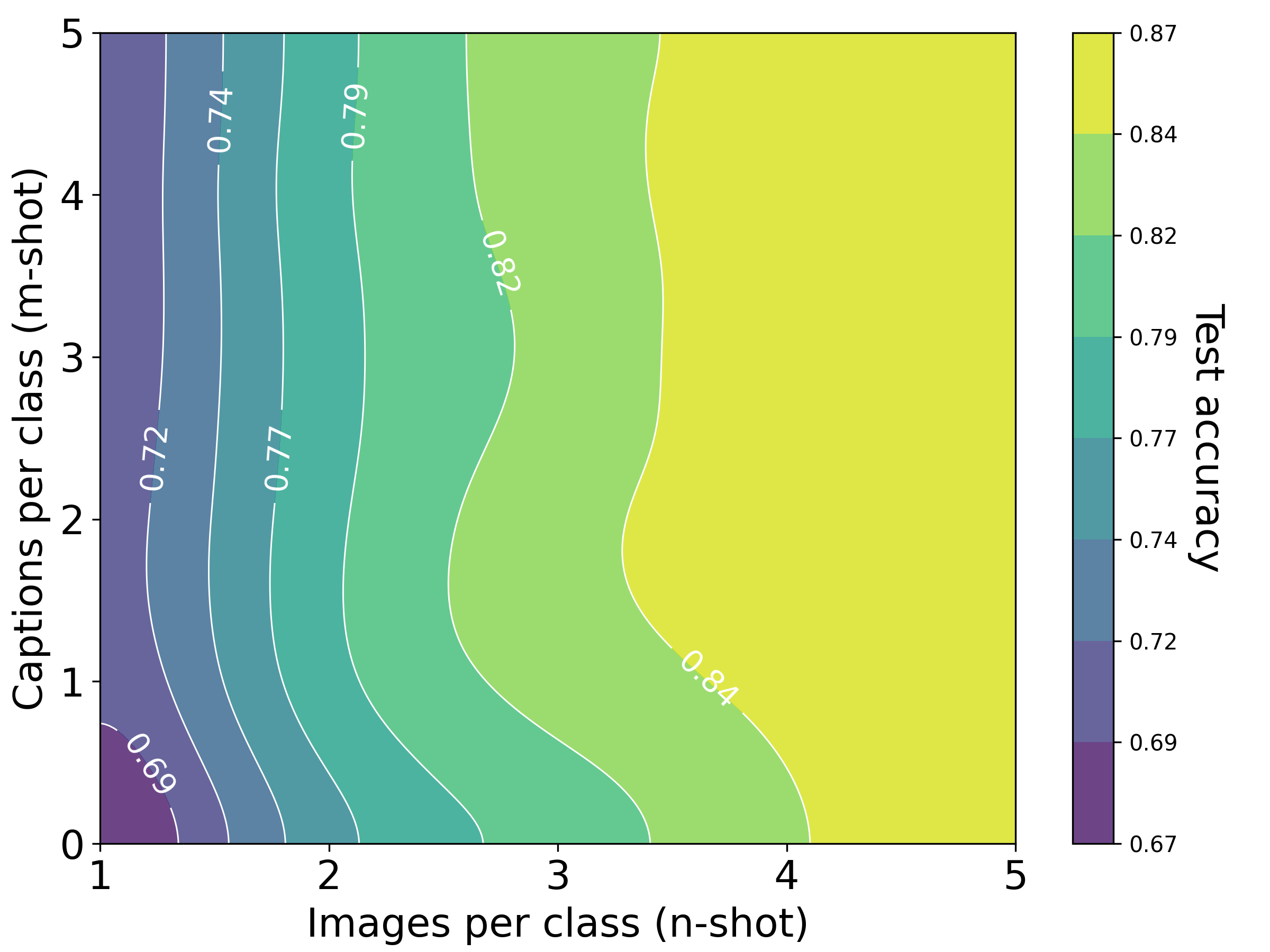
- Few examples, big gains: When only a few labeled images are available (1–16 per class), adding unpaired text helps a lot because text provides semantic clues (like names and attributes) that sharpen class boundaries.
- More robust to shifts: Models trained with unpaired text generalize better to new, harder test sets (like sketches or unusual photos), suggesting they learn more general concepts.
- Works across modalities: Using images and text improved audio classification—and vice versa—showing the benefit goes both ways.
- Three is better than two: Using three modalities together (image, text, audio) helped more than using two.
- Transfer learning across senses: Initializing a vision model with language-model weights (like starting a ViT with BERT’s layers) improved image performance, even without paired data. This means knowledge transfers across senses.
- “Exchange rates” between images and words: They measured how many words can substitute for one image during training. Depending on the setup, 1 image was roughly equal to about 228 words (with aligned encoders like CLIP) or about 1,034 words (with non-aligned encoders). In some cases, an image really is “worth a thousand words.”
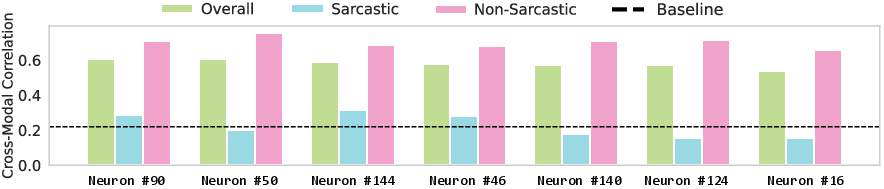
- Emergence of multimodal neurons: Even without paired data, some neurons responded to the same concepts across text and images, showing the model naturally learned shared ideas. These cross-modal links got stronger as training went on.
Why is this important?
- Paired datasets (like image–caption pairs) are expensive and limited. But unpaired data—huge amounts of images, text, and audio—are everywhere. UML lets us use that abundance to improve single-modality models.
- This can help in areas where pairing is hard, such as medical imaging (lots of scans, lots of reports, but not neatly matched), science data, and robotics (sensors, logs, and notes often aren’t paired).
- It gives a simple, practical recipe: share model weights across modalities to make each one smarter—no need to create artificial pairs or complicated alignment objectives.
Limitations and future directions
- Most experiments focus on classification. It would be interesting to test generation tasks (like producing images from text) or text-focused tasks improved by unpaired images/audio.
- The benefits depend on the auxiliary data being semantically related. Unrelated text didn’t help.
- There’s room to study richer prompts, better ways to mix modalities, and how to ensure fairness and reliability across domains.
In short, this work shows that different kinds of data are better together—even when they aren’t paired. By sharing the model’s core layers, we can turn unpaired text and audio into free upgrades for image (or audio) models, making them more accurate, robust, and efficient.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues that identify concrete directions for future research.
- Theory beyond linear-Gaussian settings: Current guarantees assume linear projections, Gaussian noise, and known design matrices; extend to deep nonlinear models with unknown mixing, non-Gaussian noise, and finite-sample generalization bounds.
- Formal link to neural training dynamics: The connection between “Fisher information addition” and gradient accumulation in non-convex, overparameterized neural networks remains heuristic; formalize conditions where shared-weight training provably improves representations.
- Identifiability without pairs in practice: Although related work is cited, the paper does not test or verify identifiability conditions on real data; develop diagnostics to assess when shared latents are recoverable from unpaired corpora.
- When unpaired data hurts (negative transfer): Characterize regimes where auxiliary modalities degrade target performance; develop predictive metrics (e.g., gradient conflict, subspace misalignment) and mitigation strategies.
- Architectural sharing choices: Only a shared head is explored; systematically study partial vs full sharing, adapters, gating, and MoE across layers to balance shared vs modality-specific factors without collapsing modality-unique information.
- Optimization and sampling: No analysis of modality sampling ratios, loss weighting, or gradient balancing; investigate curriculum schedules, dynamic weighting (e.g., GradNorm/PCGrad), and sample selection policies.
- Baseline coverage: Limited comparison to alternative unpaired strategies (pseudo-pairing, distribution alignment, co-training, contrastive alignment with pseudo-positives); add competitive baselines and ablations.
- Auxiliary text may encode labels: Text templates likely leak class names/semantics; run controlled studies where text excludes labels and compare against equal-information image-side supervision to isolate the effect of unpaired modality structure vs extra label information.
- Task breadth: Evaluation focuses on classification; extend to detection, segmentation, retrieval, captioning, speech recognition, VQA, and generative modeling to test generality.
- Target-modality asymmetry: Benefits are shown primarily for image and audio targets; assess whether unpaired vision or audio improves purely textual tasks (e.g., GLUE/SuperGLUE, long-form QA).
- Scale and compute laws: No scaling analysis with model size, dataset size, or number of modalities; quantify compute/energy costs vs gains and identify diminishing returns.
- Exchange-rate estimation validity: Conversion ratios are measured on few datasets without confidence intervals; control for text informativeness/complexity, prompt design, and dataset bias; develop MI-based or task-agnostic measures and test cross-domain stability.
- Robustness and safety: OOD tests are limited to ImageNet variants; evaluate robustness for audio/text, multimodal shifts, corruptions, adversarial attacks, label shift, and spurious correlations across modalities.
- Multilingual and cross-domain coverage: Only English text and common benchmarks are used; test multilingual text, domain-specific corpora (e.g., clinical notes with medical images), and non-visual sensors (e.g., LiDAR, depth, tactile).
- Emergence of multimodal neurons: Neuron-level analysis is small-scale and correlational; perform broader, layer-wise, causal/intervention studies to link multimodal units to performance and generalization.
- Transfer learning scope: BERT-to-ViT initialization is shown for a single pairing; explore larger LMs, varied vision backbones/scales, convergence speed, sample efficiency, and what knowledge is transferred.
- End-to-end learning: Many experiments rely on frozen/pre-extracted encoders; assess end-to-end co-training from raw inputs to test whether benefits persist without strong pretrained priors.
- Modality selection and informativeness: Provide criteria to choose helpful auxiliary modalities/datasets and to estimate “informativeness overlap” with the target; automate selection under a fixed data budget.
- Three-plus modality interactions: Preliminary 3-modality results show monotonic gains but lack analysis of redundancy, interference, and complementarity; model interactions and optimal combinations.
- Hyperparameter sensitivity: The approach introduces choices (shared head size, decoder type, loss forms); quantify sensitivity and provide robust defaults across datasets/modalities.
- Compute/memory overhead: Training cost and memory footprint of joint unpaired co-training are not reported; benchmark resource requirements and propose efficient training recipes.
- Privacy and licensing: Combining large unpaired corpora raises privacy, licensing, and contamination concerns; assess risks (e.g., membership inference), and propose privacy-preserving/data-governance practices.
- Continual/streaming settings: Unaddressed is how to add new modalities or domains over time without catastrophic forgetting; evaluate continual unpaired multimodal learning.
- Theoretical “exchange rate” in nonlinear regimes: Provide principled predictions for per-sample value across modalities as a function of noise levels and subspace overlap in deep networks, with empirical validation.
- Generalization to temporal data: The method is not evaluated on time-aligned (but unpaired) sequences (e.g., video, speech); study temporal structure and sequence-to-sequence objectives under unpaired training.
Practical Applications
Below are practical applications derived from the paper’s findings and methods, organized by their deployability. Each item notes relevant sectors, potential tools or workflows, and assumptions/dependencies that impact feasibility.
Immediate Applications
- Healthcare: strengthen medical image classifiers with unpaired clinical text
- Use case: Improve radiology, dermatology, and pathology image classification by co-training with unpaired EHR notes, radiology reports, and literature, while using only images at inference.
- Sectors: Healthcare, medical imaging, hospital IT.
- Tools/workflows: UML shared-head trainer integrated into existing CV pipelines; frozen language encoder (e.g., BERT/OpenLLaMA) with ViT/DINOv2; BERT-to-ViT weight initialization for label-scarce deployments; few-shot linear probe protocols; OOD robustness evaluation under scanner or site shifts.
- Assumptions/dependencies: Availability of semantically related unpaired text; privacy-preserving data access and compliance; careful prompt engineering for class text templates; domain-matched corpora; validated clinical evaluation beyond general classification.
- Affective computing and customer experience: improved sarcasm/emotion detection without paired audiovisual captions
- Use case: Enhance sentiment/sarcasm detection in call centers, video platforms, and social media by leveraging unpaired transcripts and frames.
- Sectors: Affective computing, contact centers, content moderation.
- Tools/workflows: UML shared weights with separate audio, text, or video encoders; supervised labels per modality; neuron-level correlation auditing to understand emerging multimodal neurons.
- Assumptions/dependencies: Semantic relatedness across modalities; balanced datasets to mitigate bias; domain-specific text corpora.
- Audio analytics and industrial IoT: environmental sound classification improved with unpaired image/text
- Use case: Classify machine/environmental sounds in factories or smart buildings using unpaired equipment manuals, maintenance logs, and image datasets.
- Sectors: Manufacturing, IoT, smart cities.
- Tools/workflows: AudioCLIP or ES-ResNeXT for audio, DINOv2 for vision, OpenLLaMA/BERT for text; UML shared head; two- or three-modality training (audio, image, text).
- Assumptions/dependencies: Reasonable semantic overlap between sound classes and auxiliary text/images; quality and labeling of audio datasets.
- E-commerce and catalog vision: fine-grained product classification with unpaired descriptions
- Use case: Improve categorization of visually similar products (cars, aircraft, textiles, pets, flowers) by training with unpaired product descriptions/spec sheets and using images at inference.
- Sectors: Retail, e-commerce, supply chain.
- Tools/workflows: Template-based product text generation; UML shared classifier initialized by average class text embeddings; few-shot linear probes for rapidly expanding catalogs.
- Assumptions/dependencies: Access to product metadata; alignment between product classes and textual descriptors.
- ML platforms and MLOps: plug-in to exploit unpaired corpora in unimodal training
- Use case: Platform-level support to ingest unpaired auxiliary modalities to strengthen a single-target modality, with automatic selection of modality budgets using the paper’s marginal rate-of-substitution (MRS).
- Sectors: Software/ML tooling.
- Tools/workflows: “UML Shared-Head Trainer” library; “Modality Exchange Rate Estimator” to decide acquisition strategy (“how many words per image”); AutoML integration for hyperparameter and prompt selection; robustness benchmarking suite for OOD shifts.
- Assumptions/dependencies: Compatible embedding backbones; compute resources; data licensing; monitoring to avoid spurious correlations.
- Robotics perception: stronger vision from language pretraining and unpaired sensor logs
- Use case: Initialize robot vision stacks with LLM weights (BERT→ViT) and co-train with unpaired textual manuals or mission logs for better generalization in new environments.
- Sectors: Robotics, autonomous systems.
- Tools/workflows: Transformer weight transfer from language to vision; UML head with image and text encoders; few-shot adaptation for new scenes.
- Assumptions/dependencies: Task-relevant textual corpora; safety validation in deployment.
- Education and edtech: label-efficient image classifiers using textbooks and curriculum text
- Use case: Build educational vision models (e.g., lab object recognition, educational app content classification) that leverage unpaired subject descriptions from textbooks/curricula.
- Sectors: Education, edtech.
- Tools/workflows: UML with frozen language encoder and ViT backbones; few-shot training workflows for new subject modules.
- Assumptions/dependencies: High-quality domain texts; careful prompt design; adequate compute for co-training.
- Security and content moderation: improved classifiers with caption/alt-text corpora
- Use case: Moderation systems can strengthen image or video classifiers by co-training with unpaired alt-text and user reports, maintaining unimodal inference.
- Sectors: Trust & safety, social platforms, media.
- Tools/workflows: UML shared head; OOD evaluation; neuron-level analysis to audit cross-modal coupling.
- Assumptions/dependencies: Availability of alt-text; balanced datasets; fairness and bias audits.
- Policy and data strategy: prioritize unpaired auxiliary data collection
- Use case: Shift procurement and data-sharing policies to encourage collecting domain-relevant unpaired text/audio/metadata rather than expensive, tightly paired datasets.
- Sectors: Public sector, healthcare administration, research funders.
- Tools/workflows: MRS-informed acquisition plans; privacy-preserving unpaired data pipelines; documentation of modality budgets and expected gains.
- Assumptions/dependencies: Governance frameworks for unpaired multimodal data; privacy guarantees; alignment with sector-specific regulations.
- Personal photo organization and daily apps: better categorization using calendar/notes
- Use case: Improve on-device photo classifiers by co-training with unpaired personal text metadata (calendar entries, notes) while keeping only image inference.
- Sectors: Consumer apps, mobile.
- Tools/workflows: Local UML training with frozen text encoder; privacy-first on-device compute; few-shot personalized classifiers.
- Assumptions/dependencies: Opt-in data use; strict privacy controls; device compute constraints.
Long-Term Applications
- Medical decision support across modalities without pairing
- Use case: Extend beyond classification to detection, segmentation, and generation (e.g., report drafting) by leveraging abundant unpaired clinical text and medical images; integrate audio (dictations) as a third modality.
- Sectors: Healthcare, medical AI.
- Tools/workflows: Multi-task UML pipelines; standardized MRS dashboards for acquisition; clinical auditing of multimodal neurons; privacy-preserving federated training.
- Assumptions/dependencies: Clinical validation and regulation; extended benchmarks beyond classification; robust safeguards against leakage and bias.
- Foundation model training strategies that systematically leverage unpaired data
- Use case: Train unimodal foundation models (vision-only, audio-only) that exploit large unpaired corpora from other modalities to gain generalization and robustness.
- Sectors: AI research, platform providers.
- Tools/workflows: Scaling laws and MRS-based curriculum; integrated modality-budget optimization; shared-weight architectures generalized to multiple modalities (incl. metadata, tabular).
- Assumptions/dependencies: Large-scale compute and distributed training; careful control of domain shift and spurious alignments.
- Cross-modal retrieval and generation without paired supervision
- Use case: Retrieve or synthesize content across modalities using shared-weight encoders trained unpaired; e.g., text-to-image retrieval or audio-to-text hints for search.
- Sectors: Search, media, enterprise knowledge management.
- Tools/workflows: Unpaired alignment objectives layered atop UML; downstream adapters for retrieval/generation.
- Assumptions/dependencies: Additional research validating unpaired retrieval/generation; evaluation protocols; safety filters.
- Autonomous systems and smart cities: policy text and sensor fusion for robust perception
- Use case: Improve perception in autonomous driving by co-training camera models with unpaired traffic codes, map text, and community reports; extend to audio (road noise) as another auxiliary modality.
- Sectors: Transportation, urban tech.
- Tools/workflows: UML with domain-specific text encoders; OOD robustness suites; policy-linked prompts.
- Assumptions/dependencies: High-quality corpora; safety certification; city-level data governance.
- Scientific discovery workflows: microscopy and lab imaging improved by literature and notebooks
- Use case: Enhance specialized scientific image models by co-training with unpaired lab notebooks and scientific papers, reducing labeled data requirements.
- Sectors: Pharma, materials, biology.
- Tools/workflows: UML shared head with domain encoders; active learning using MRS to decide whether to acquire images or texts; experiment tracking.
- Assumptions/dependencies: Access to domain literature; domain adaptation methods for highly specialized imagery; reproducibility standards.
- Enterprise compliance and finance analytics: speech and document models enhanced via unpaired corpora
- Use case: Stronger unimodal speech models (compliance call monitoring) or document classifiers (KYC/AML) trained with unpaired textual policies and historical documents; maintain unimodal inference for scalability.
- Sectors: Finance, enterprise compliance.
- Tools/workflows: UML head combining audio and text/document embeddings; neurally-audited feature sharing; risk and fairness checks.
- Assumptions/dependencies: Regulatory approval; domain-specific corpora; secure data infrastructures.
- Standard-setting and governance for unpaired multimodal data use
- Use case: Develop standards to measure modality value (MRS), fairness audits for multimodal neurons, and guidelines for privacy-preserving unpaired co-training.
- Sectors: Policy, standards bodies, auditing.
- Tools/workflows: Open benchmarks; audit toolkits; best-practice documents for modality budgets and documentation.
- Assumptions/dependencies: Stakeholder consensus; formal privacy guarantees; public datasets and shared tooling.
- Dataset acquisition optimization and marketplaces
- Use case: Marketplaces and internal procurement systems that optimize for unpaired auxiliary modality data (e.g., curated domain text) when images are scarce, guided by empirically estimated exchange rates.
- Sectors: Data vendors, AI ops.
- Tools/workflows: MRS dashboards; cost-benefit analyzers; auto-curation pipelines.
- Assumptions/dependencies: Transparent data provenance; ongoing monitoring of performance vs. acquisition cost.
Notes on overarching assumptions and dependencies that recur:
- Semantic relatedness between target and auxiliary modalities is critical; gains diminish with unrelated data.
- Gains are larger with aligned encoders (e.g., CLIP); still present with non-aligned encoders but may require careful prompt and dataset curation.
- Theoretical results rely on linear assumptions for Fisher information; while empirically validated for classification, extension to generation/detection tasks needs further research.
- Data governance (privacy, licensing, bias mitigation) and robust evaluation under distribution shift are essential for production use.
- Compute and MLOps integration matter: shared-head training should be resource-aware, and freezing auxiliary encoders often stabilizes training.
Glossary
- Affective computing: A research area focused on understanding and modeling human emotions using computational methods across modalities like vision, audio, and text. "Empirically, we evaluate Uml on diverse image–text tasks in healthcare, and affective computing, as well as 10 standard visual benchmarks."
- AudioCLIP: A multimodal model that extends CLIP to incorporate audio alongside images and text. "For audio encoding, we use AudioCLIP with an ES-ResNeXT backbone."
- Autoregressive transformer: A transformer architecture that predicts the next token or patch in a sequence, modeling data in a step-by-step generative manner. "we use an autoregressive transformer as the shared network ()."
- BERT: A pretrained bidirectional transformer-based LLM used for transfer learning across tasks and modalities. "initializing the transformer layers of a ViT~\citep{dosovitskiy2020image} with pretrained BERT~\citep{devlin2019bert} weights"
- CLIP: Contrastive Language–Image Pretraining; a model that learns aligned image-text representations via contrastive learning. "since CLIP embeddings are already aligned, the gains from Uml\ are even stronger"
- CLS token: A special classification token prepended to transformer inputs to aggregate sequence information for downstream classification. "augmented by a CLS token and positional embeddings."
- Contrastive methods: Learning techniques that pull semantically related pairs together and push unrelated pairs apart in embedding space. "Contrastive methods encourage instances of the same concept (such as an image and its text label) to be close together"
- Cross-entropy: A loss function commonly used for classification over discrete targets, measuring the difference between predicted and true distributions. "where is the mean squared error for continuous targets or cross-entropy for discrete tokens."
- Cross-modal retrieval: Retrieving data in one modality (e.g., text) using a query from another modality (e.g., image) via shared representations. "zero-shot transfer, cross-modal retrieval, and downstream classification"
- Data Generating Process: A formal specification of how observed data arise from underlying latent variables and noise. "Data Generating Process. Assume that all factors of variation in reality live in a single -dimensional space"
- DINOv2: A self-supervised vision transformer model used as a strong image encoder. "using ViT-S/14 DINOv2 as the vision encoder"
- Distribution shift: A difference between training and test data distributions, which can degrade model performance. "We also evaluate the robustness of Uml-trained models under test-time distribution shifts."
- Fisher information matrix: A measure of how much information an observable random variable carries about unknown parameters, tied to the curvature of the likelihood. "is governed by the Fisher information matrix "
- ImageNet-ESC benchmark: A multimodal benchmark linking ImageNet images/captions with ESC-50 environmental audio classes for cross-modal evaluation. "We extend Uml\ to an audio–vision–text setting using the ImageNet-ESC benchmark~\citep{lin2023multimodality}, which links ImageNet objects and captions with ESC-50 environmental sounds."
- Least-squares estimator: An estimator that minimizes the sum of squared residuals, often used in linear models. "Let be the least-squares estimators for "
- Linear probe: A simple linear classifier trained on frozen embeddings to evaluate the quality of learned representations. "Uml (Ours) achieves higher top-1 linear probe accuracy than unimodal baselines"
- Loewner ordering: A partial order on symmetric matrices where one matrix is considered greater if their difference is positive semidefinite. "the common-factor covariance satisfies the strict Loewner ordering i.e. "
- Marginal Rate-of-Substitution (MRS): The rate at which data from one modality can be traded for another while maintaining the same performance. "Marginal Rate-of-Substitution Between Modalities"
- Modality-agnostic: A design or training paradigm that is not specialized to any single modality, enabling shared processing across different types of data. "a modality-agnostic training paradigm in which a single model alternately processes inputs from different modalities"
- Multimodal neurons: Network units that respond coherently to the same concept across different modalities, such as vision and language. "Models like CLIP, trained with paired image–text supervision, are known to develop multimodal neurons~\citep{goh2021multimodal}"
- OpenLLaMA: An open-source reproduction of the LLaMA LLM used as a text encoder. "with diverse encoders including CLIP, DINOv2, OpenLLaMA, and others."
- Pearson correlation: A statistic measuring linear correlation between two variables, ranging from -1 to 1. "We compute the Pearson correlation "
- Positional embeddings: Learned vectors added to token or patch embeddings to encode their positions in a sequence. "augmented by a CLS token and positional embeddings."
- Self-supervised learning: Training that leverages inherent structure or proxy tasks in unlabeled data to learn representations. "We consider two regimes to train these networks: (a) self-supervised learning for fully unpaired data"
- Shared embedding space: A common vector space into which different modalities are mapped to capture shared semantics. "mapping each modality into a shared embedding space "
- Vision Transformer (ViT): A transformer-based architecture for image processing that treats images as sequences of patches. "initializing the transformer layers of a ViT~\citep{dosovitskiy2020image}"
- Weight sharing: Using the same parameters across multiple inputs or modalities to encourage common structure and transfer. "By nothing more than weight sharing, i.e., without surrogate objectives or inferred alignments"
- Zero-shot transfer: Applying a model to a new task or dataset without any task-specific training, relying on generalizable representations. "often surpassing their unimodal counterparts in zero-shot transfer, cross-modal retrieval, and downstream classification"
Collections
Sign up for free to add this paper to one or more collections.