- The paper demonstrates that trained multimodal DNNs outperform unimodal and random models in predicting SEEG activity, establishing their effectiveness in mapping brain integration.
- The study utilizes diverse architectures like CNNs and transformers to identify specific regions, such as the superior temporal cortex, middle temporal cortex, and inferior parietal lobe.
- The findings imply that multimodal models can advance neurotechnology and AI by uncovering specialized neural circuits for integrated sensory processing.
Revealing Vision-Language Integration in the Brain with Multimodal Networks
This paper utilizes multimodal deep neural networks (DNNs) to investigate vision-language integration sites in the human brain by predicting stereoencephalography (SEEG) recordings. The study demonstrates that trained vision-LLMs systematically outperform both random and unimodal models in predicting neural activity, revealing specific brain regions involved in multimodal integration.
Multimodal Methodology
The approach expands traditional unimodal DNN applications by leveraging multimodal models, aiming to illuminate integrated brain processes vital for vision and language. A diverse set of DNN architectures, including convolutional networks and transformers, are employed to predict SEEG data collected from subjects watching movies. Two datasets were created: one with visually-aligned stimuli and another with language-aligned stimuli, allowing the study to parse brain data and assess models' explanatory power relative to neural activity.
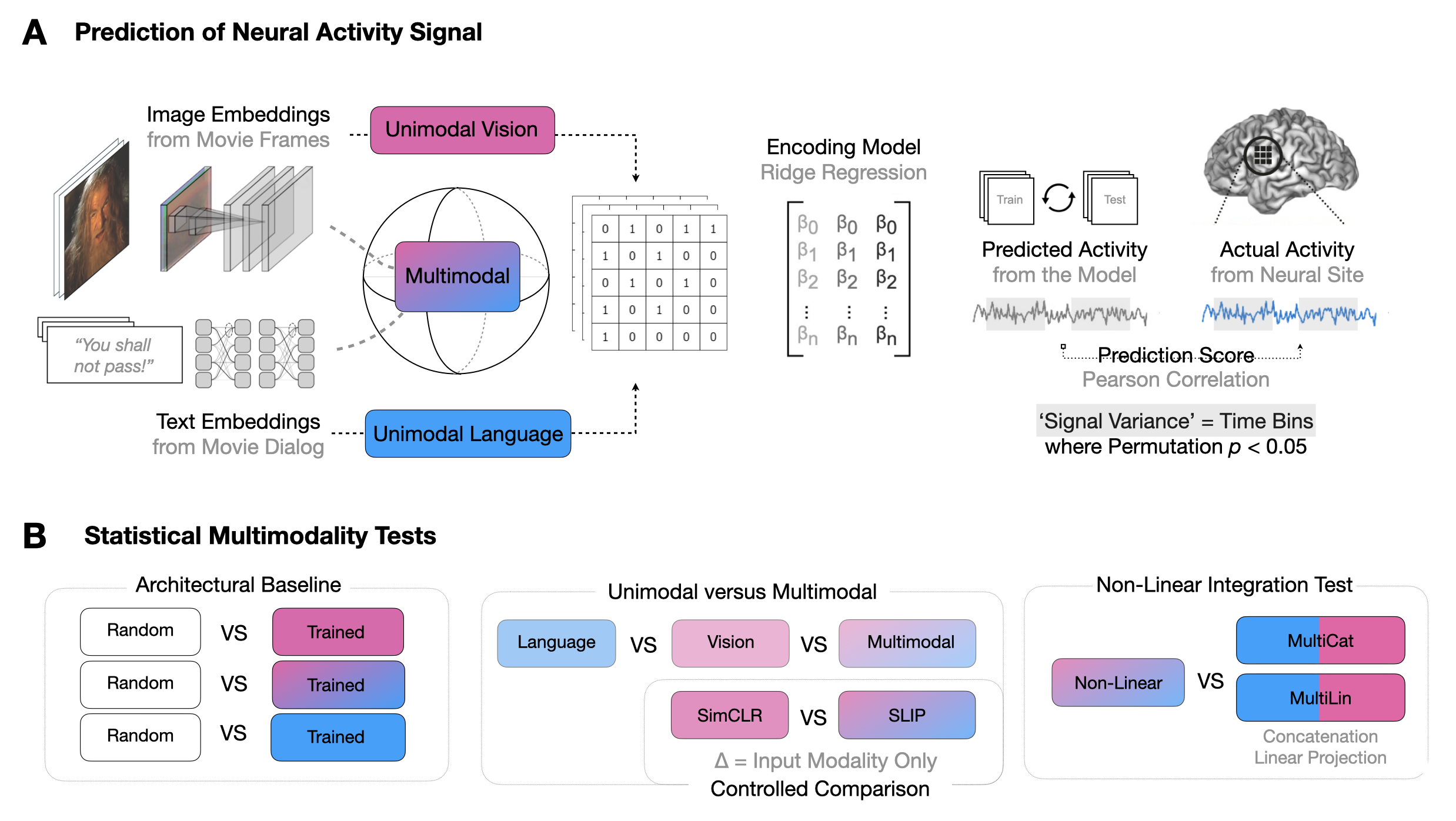
Figure 1: Overview of the data processing and analytical framework for predicting neural integration sites.
Neural Dataset and Model Comparison
Neural data collection is a critical part of the experimental setup. SEEG recordings from multiple subjects provide the necessary temporal and spatial resolution. To decode these signals, a variety of multimodal DNN architectures (such as SLIP, ALBEF, and BLIP) and unimodal networks were used. Regularized ridge regression combined with a bootstrap procedure offered robust statistical analysis of model predictivity on neural data. This allowed the comparison of trained vs. random initialization, showing clear performance improvement for trained models.
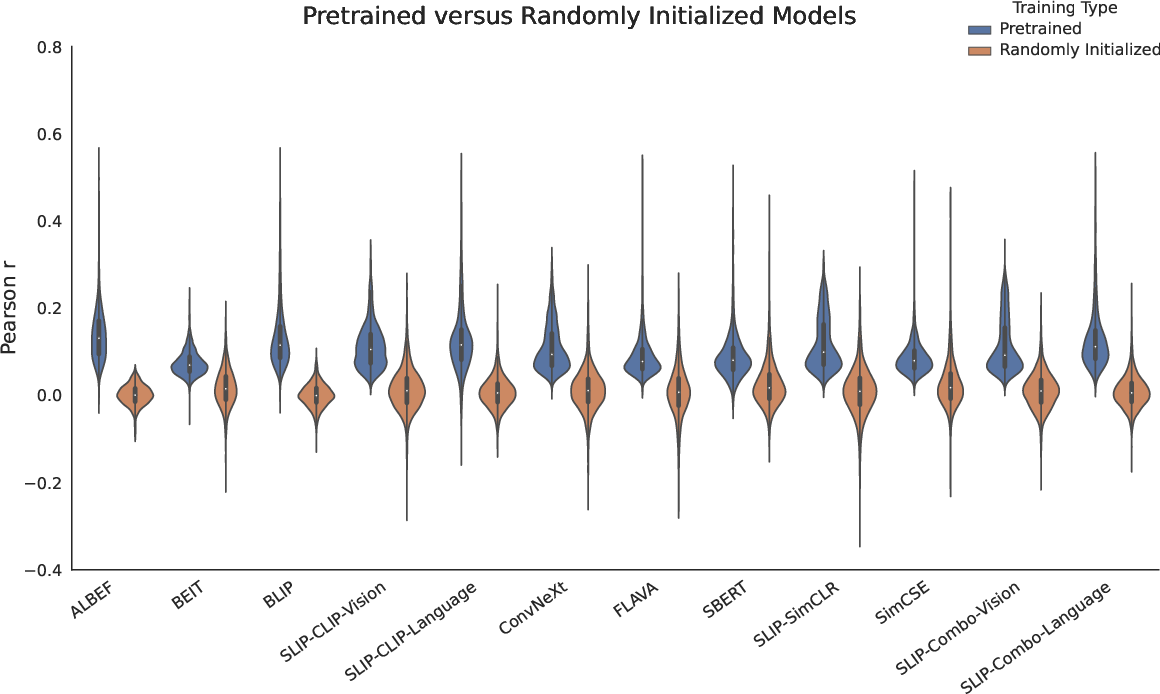
Figure 2: Trained models outperform randomly initialized models across electrodes, highlighting the significance of learned representations.
Findings on Vision-Language Integration
The study identifies significant sites of vision-language integration across 12.94% of brain regions examined. Multimodal models consistently outperform unimodal models, underscoring their utility in capturing complex neural integration processes.
Regional Analysis
The detailed analysis highlighted specific brain regions, such as the superior temporal cortex, middle temporal cortex, and inferior parietal lobe, as key sites of vision-language integration (Figure 3). These areas coincide with previously documented regions involved in multimodal processing, corroborating the hypothesis of distinct neural circuitry for integrated sensory processing.
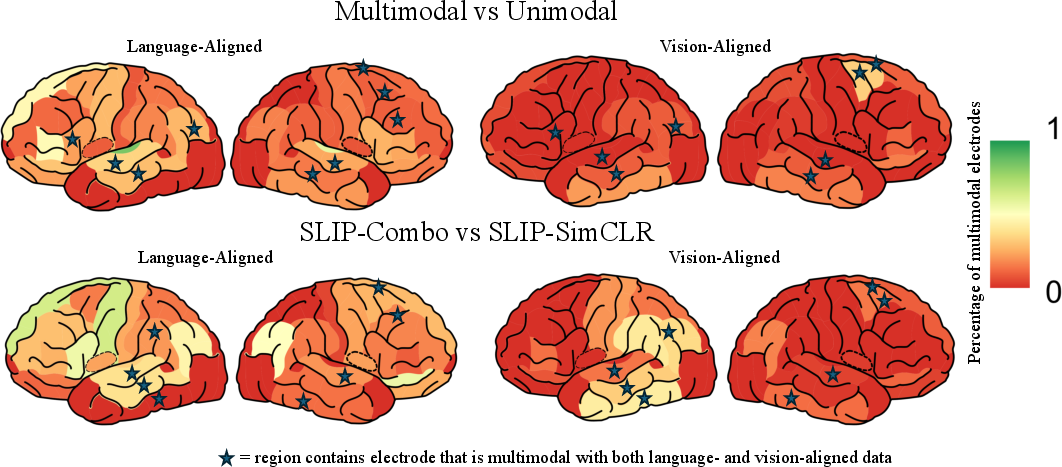
Figure 3: Visualization of brain regions with significant multimodal integration, with red indicating no multimodal electrodes and blue stars marking successful integration across datasets.
Multimodal models were evaluated for their task performance on standard benchmarks (such as VQA-v2 and NLVR2) to ensure the observed neural predictivity was not merely attributed to superior unimodal task performance. Results demonstrated that these models, while performing appropriately on standard tasks, were better suited for integrative tasks within the neural context.
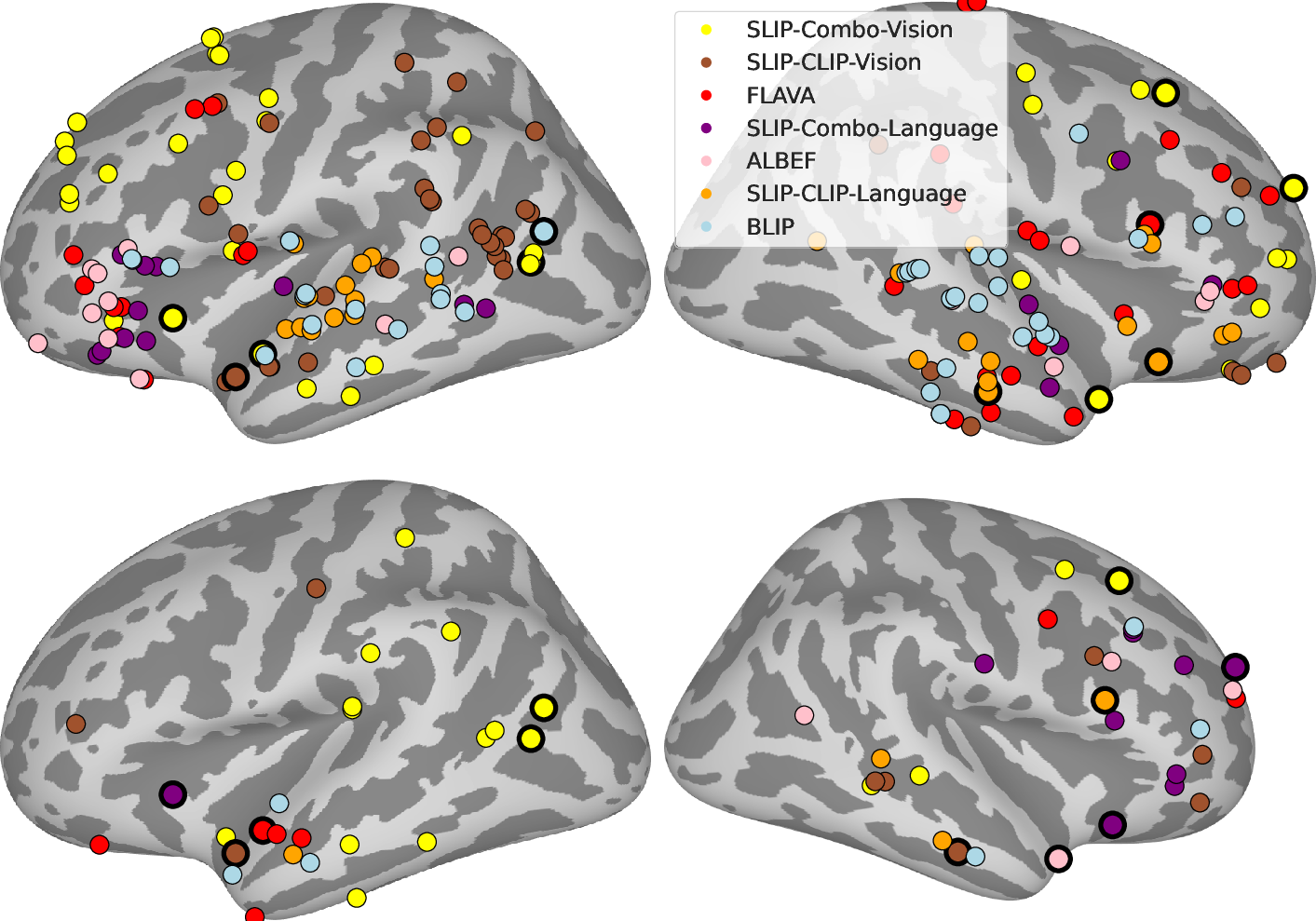
Figure 4: Best models of multimodal integration, showcasing electrodes where multimodal models exhibit superior predictivity.
Conclusion and Future Directions
The integration of multimodal DNNs for brain data analysis provides compelling evidence for specialized neural circuits engaged in processing combined sensory information. This methodology elucidates the alignment of biological and artificial neural networks, paving the way for future studies aimed at further unveiling the mechanisms of sensory integration and improving AI systems' understanding of brain-like processing.
The implication of these findings suggests a broader application in both neurotechnology and AI, including the enhancement of machine multimodal processing capabilities and potential interventions for neurological conditions involving sensory integration dysfunction.
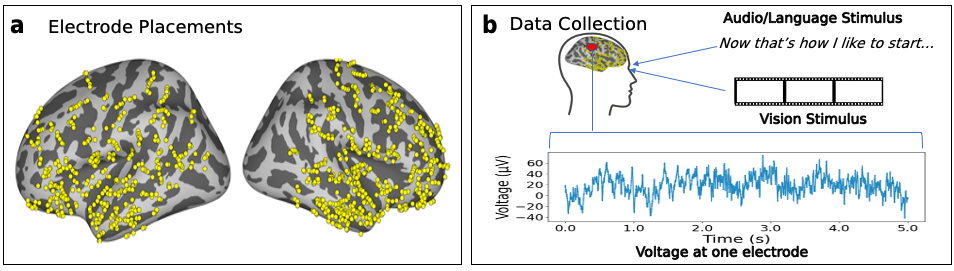
Figure 5: Medial region analysis showing extended regions of vision-language integration, supplementing lateral findings and indicating a network structure across the brain.