- The paper demonstrates a novel product of experts framework that integrates DFS and task-specific augmentations to achieve state-of-the-art ARC-AGI performance.
- The methodology leverages LLMs as both generators and scorers, using output probabilities to rank candidate solutions effectively.
- Experimental results show a 71.6% accuracy on ARC-AGI, highlighting the method's efficiency and potential for cost-effective abstract reasoning.
Abstract
The research examines the application of LLMs to the Abstraction and Reasoning Corpus (ARC-AGI), which is a challenging benchmark for assessing abstract reasoning capabilities in AI. The study introduces a novel method that integrates task-specific data augmentations with a depth-first search algorithm to generate diverse candidate solutions. This approach employs the LLM as both a generator and scorer, utilizing output probabilities to refine solution selection. The method achieves a performance of 71.6% on the ARC-AGI public evaluation set, representing state-of-the-art results for open-source models by leveraging efficient computation strategies.
Introduction
ARC-AGI tasks are designed to evaluate an AI's ability to generalize and exhibit abstract reasoning. These tasks can be deceptively simple for humans but pose significant challenges for AI models, including both algorithmic and contemporary neural architectures. Despite advances resulting from scaling up computational models, fundamental limitations in abstract reasoning persist. This study endeavors to address these challenges by tailoring its approach specifically to ARC-AGI. It achieves state-of-the-art performance not through model size, but rather through strategic leveraging of existing model architectures under augmented conditions. The methodology prioritizes transparency and reproducibility, demonstrating that efficient solutions need not involve exorbitant computational costs.
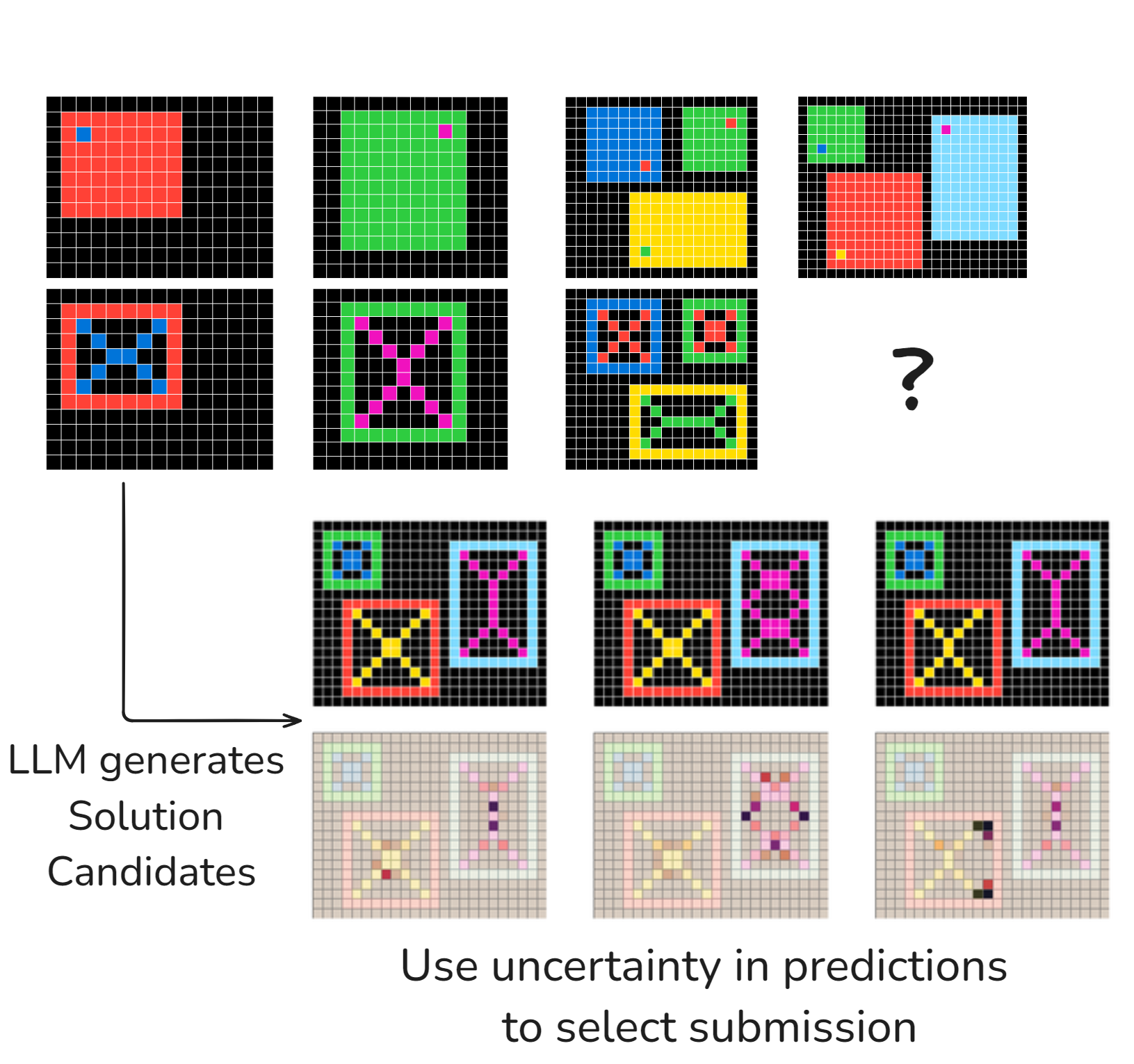
Figure 1: Example of a typical ARC-AGI task.
The development of solutions for ARC typically involves solutions like program search over domain-specific languages (DSLs) and more recently, LLMs that leverage test-time training (TTT). Inductive and transductive reasoning approaches have also been explored, where the former involves inferring functions to solve tasks, while the latter directly generates solutions through LLM tokenization. The presented work builds upon these strategies by adopting a product of experts approach that combines multiple augmentation perspectives to mitigate single-augmentation biases.

Figure 2: Our standard tokenization approach for LLMs with ARC tasks.
Methodology
The methodology employs a Bayesian perspective, treating each ARC task as a subset of a broader distribution of potential solutions. A critical innovation in this work is the use of depth-first search (DFS) for solution candidate generation, improved by employing a high-probability threshold to ensure that only the most promising solutions are explored. Candidates are re-evaluated under different augmentations, with their probabilities combined using a product of experts approach to refine solution rankings.
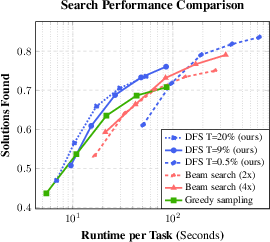
Figure 3: Number of solutions found by various sampling algorithms as a function of runtime.
Experimental Results
The approach demonstrates that combining solutions across multiple augmentation perspectives significantly enhances solution accuracy. In test scenarios, the product of experts method outperformed conventional sampling strategies, achieving superior accuracy in both ARC and Sudoku tasks. The researchers also quantify the efficiency of their DFS and selection strategies, underscoring the computational feasibility and effectiveness of their approach compared to more resource-intensive models.
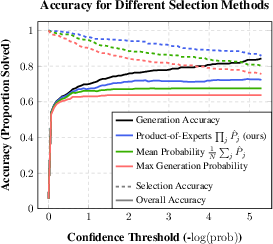
Figure 4: Top-2 accuracy and coverage of different selection methods as a function of confidence threshold T.
Discussion
This work highlights the potential of leveraging LLMs' latent capacities through strategic augmentation and scoring, proving that abstract reasoning tasks like ARC-AGI can be tackled effectively by relatively modest-sized models. The dual role of LLMs as both generator and scorer offers a unique technique to ensure that the generated solutions are both relevant and contextually viable. The methods showcased in this study have implications for a variety of domains, suggesting that similar strategies could be generalized to other complex reasoning tasks requiring structured problem-solving approaches.
Conclusion
The study successfully demonstrates an innovative application of LLMs to abstract reasoning tasks through a combination of DFS candidate generation and a product of experts selection strategy. This approach not only achieves state-of-the-art results for open-source models on ARC-AGI but does so in a cost-effective and reproducible manner. Future research can extend these concepts to other domains, exploring different augmentation strategies to further enhance LLM performance in abstract reasoning.
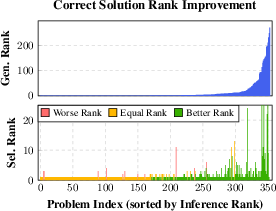
Figure 5: Comparison of solution rankings using generative and ensemble methods.
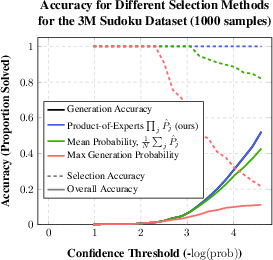
Figure 6: Results of the Sudoku experiments indicating the advantage of the product of experts approach.

