Think Visually, Reason Textually: Vision-Language Synergy in ARC
Abstract: Abstract reasoning from minimal examples remains a core unsolved problem for frontier foundation models such as GPT-5 and Grok 4. These models still fail to infer structured transformation rules from a handful of examples, which is a key hallmark of human intelligence. The Abstraction and Reasoning Corpus for Artificial General Intelligence (ARC-AGI) provides a rigorous testbed for this capability, demanding conceptual rule induction and transfer to novel tasks. Most existing methods treat ARC-AGI as a purely textual reasoning task, overlooking the fact that humans rely heavily on visual abstraction when solving such puzzles. However, our pilot experiments reveal a paradox: naively rendering ARC-AGI grids as images degrades performance due to imprecise rule execution. This leads to our central hypothesis that vision and language possess complementary strengths across distinct reasoning stages: vision supports global pattern abstraction and verification, whereas language specializes in symbolic rule formulation and precise execution. Building on this insight, we introduce two synergistic strategies: (1) Vision-Language Synergy Reasoning (VLSR), which decomposes ARC-AGI into modality-aligned subtasks; and (2) Modality-Switch Self-Correction (MSSC), which leverages vision to verify text-based reasoning for intrinsic error correction. Extensive experiments demonstrate that our approach yields up to a 4.33% improvement over text-only baselines across diverse flagship models and multiple ARC-AGI tasks. Our findings suggest that unifying visual abstraction with linguistic reasoning is a crucial step toward achieving generalizable, human-like intelligence in future foundation models. Source code will be released soon.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI to solve tricky pattern puzzles more like humans do. The puzzles come from a test called ARC-AGI, where each problem shows a few tiny color grids (like pixel art) and asks the AI to figure out the hidden rule (for example, “rotate shapes 90°” or “keep only the largest block”) and apply it to a new grid. The authors found that combining two ways of thinking—looking at pictures (vision) and reading/writing lists of numbers (text)—helps AI understand and solve these puzzles better.
What questions does the paper ask?
- Can AI solve abstract puzzles better by “seeing” the grids as images to spot patterns and then “writing” the solution in text to be precise?
- When should AI use vision and when should it use text?
- Can switching between vision and text help the AI catch and fix its own mistakes?
How did they approach the problem?
First, here’s the ARC-AGI puzzle setup in simple terms:
- You get a few example pairs: an input grid and the correct output grid.
- Your job is to discover the rule and apply it to a new input grid to produce the right output.
The authors split the job into two steps and matched each step to the best “modality” (modality just means the type of input: pictures vs. text):
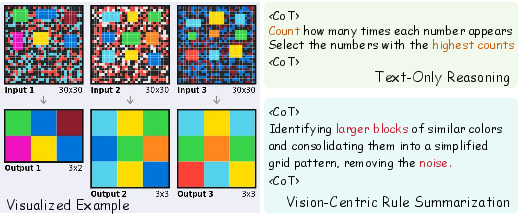
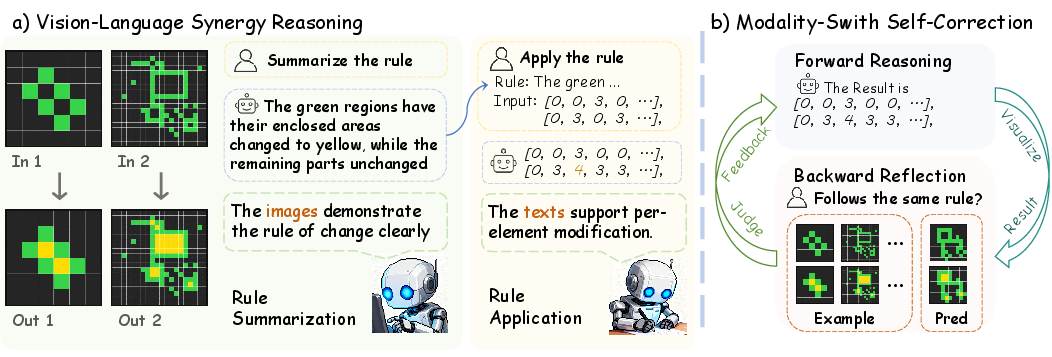
- Step 1: Rule Summarization (spot the pattern)
- They show the examples as images (color grids).
- Why images? Because it’s easier to notice overall shapes, symmetry, and spatial patterns by looking. Think “seeing a map” instead of “reading a long spreadsheet.”
- Step 2: Rule Application (execute the rule)
- They switch to text (nested lists of numbers) to actually compute the output.
- Why text? Because lists let the AI be exact, like saying “change cell (5,7) from 3 to 0” without getting confused by nearby pixels.
They call this two-part strategy Vision-Language Synergy Reasoning (VLSR).
They also add a self-check system:
- Modality-Switch Self-Correction (MSSC)
- After the AI produces an answer in text, they convert the input and the predicted output back into images and ask the AI (using its “vision” skills) to check if the transformation looks consistent with the examples.
- If the visual check says “this doesn’t match,” the AI tries again in text with feedback. This is like solving a math problem, sketching the result, noticing it looks wrong, and redoing it more carefully.
What methods did they use, in everyday language?
- Vision-Language Synergy Reasoning (VLSR):
- “See to understand, write to execute.”
- Use images to understand big-picture patterns (like rotations, reflections, connected shapes).
- Use text to precisely change individual cells according to the rule.
- Modality-Switch Self-Correction (MSSC):
- “Check with fresh eyes.”
- Generate an answer in text.
- Convert it to an image and visually compare: does the new output look like it follows the same rule as the examples?
- If not, provide feedback and let the AI try again, still using text for precise edits.
Why not just use images for everything? The authors tried that and found a problem: pictures help with patterns, but they’re not great at tiny, exact edits. For large grids, the AI sometimes misreads or misplaces a single cell. Text is better for pinpoint accuracy.
Main findings and why they matter
- Vision is better at finding the rule; text is better at carrying it out.
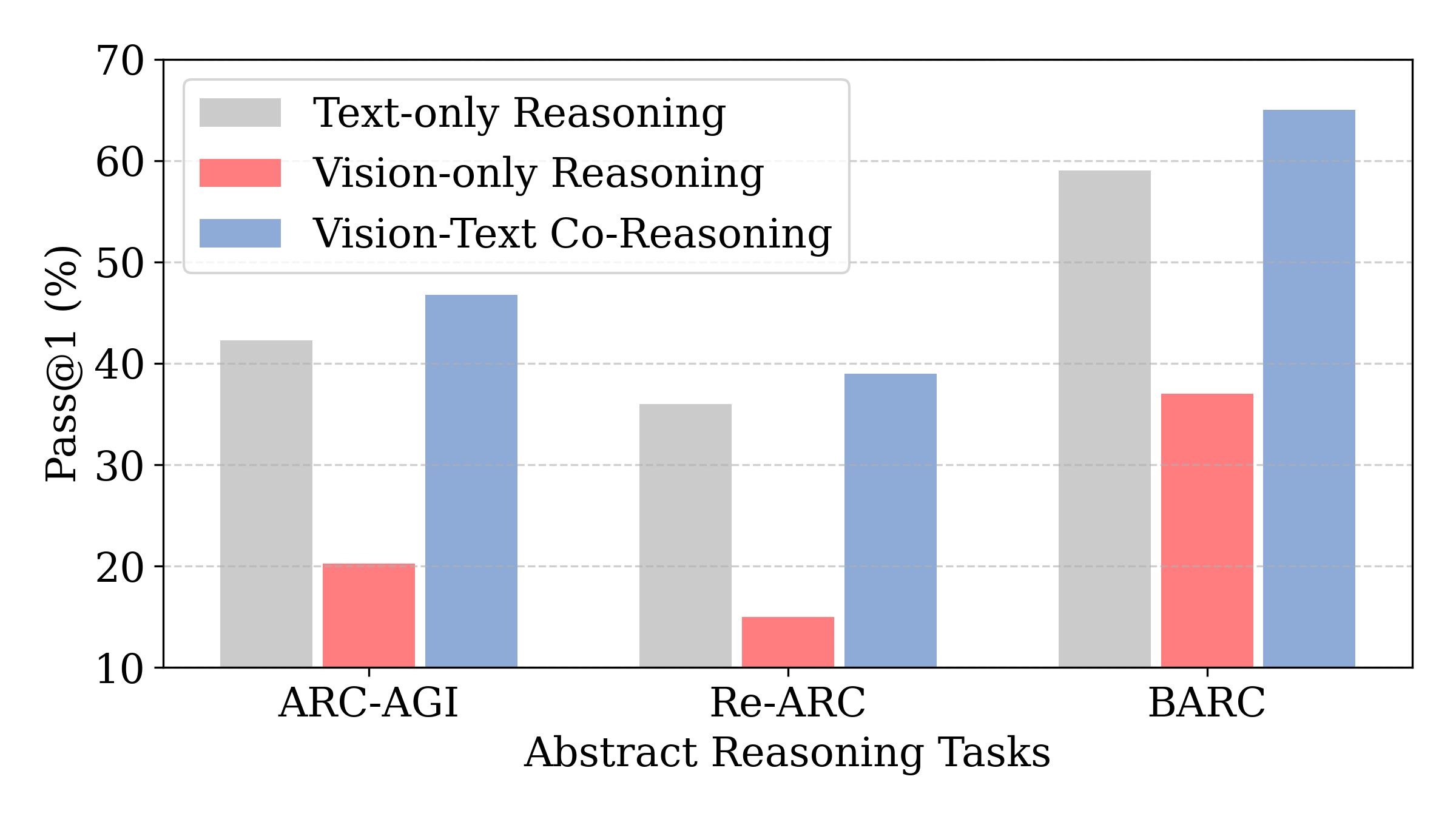
- When the AI used images to summarize the rule, performance improved by about 3% on average.
- When the AI tried to apply rules using images instead of text, performance dropped a lot (around 15% on average). So images are great for “big picture,” not “pixel-perfect” edits.
- Combining both methods (VLSR + MSSC) beat text-only approaches across several strong AI models and ARC-style benchmarks.
- Improvements were up to about 7% on some tests (and around 4% improvement on average over text-only baselines).
- Visual checking makes self-correction actually work.
- Text-only self-correction tended to stagnate or even get worse.
- Switching to a visual check helped the AI spot spatial mistakes and improve over several rounds without needing the right answers in advance.
- Training with the same idea (split the tasks: visual model for rule-finding, text model for rule-doing) also helped smaller open-source models beat bigger closed-source ones on some ARC benchmarks. This shows the approach isn’t just a trick at test time—it helps during training too.
Why this research matters
This work suggests a practical recipe for more human-like reasoning in AI:
- Humans often “look first” to get the idea, then “write precisely” to carry it out. Mimicking that—seeing patterns visually, then executing steps in text—makes AI better at abstract reasoning.
- It points to a future where AI systems don’t just rely on text or images alone, but smartly combine both at the right moments.
- This approach could improve AI’s performance on other tasks that need both pattern intuition (maps, diagrams, spatial logic) and exact computation (step-by-step editing, coding, or math).
In short: Think visually to understand. Reason textually to be precise. Switching between the two helps the AI catch mistakes—bringing it one step closer to flexible, human-like problem solving.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed so future researchers can act on them.
- Lack of statistical rigor: improvements are reported as Pass@1 averages without confidence intervals, variance across seeds, or significance testing; quantify variability across runs and tasks and report statistical significance.
- Limited evaluation scope: experiments focus on ARC-AGI, BARC, and Re-ARC; assess generalization to other abstract/spatial reasoning benchmarks (e.g., Raven/Matrices, Sokoban-like tasks, programmatic puzzles) and non-grid domains.
- Pass@k and self-consistency not analyzed: only Pass@1 at temperature 0.7 is reported; evaluate Pass@k, self-consistency voting, and temperature sensitivity to understand reliability vs. sampling.
- Visualization design choices untested: color palette, resolution, grid line thickness, anti-aliasing, and rendering parameters are not ablated; systematically compare visual encodings (colors vs. symbols/glyphs, coordinate overlays, arrows) and their impact on rule summarization and verification.
- Element-wise localization failures in vision left unaddressed: position confusion is noted but no mitigation is explored; test overlays (per-cell coordinates), higher-resolution crops, pointer tokens, or object-level segmentation to improve pixel-precise manipulation.
- No taxonomy-level breakdown: improvements are not analyzed by rule categories (e.g., symmetry, rotation, connected components, counting, flood fill); create a labeled taxonomy and measure which rule families benefit from VLSR/MSSC and which do not.
- Critic reliability in MSSC is unquantified: visual consistency judgments may produce false positives/negatives; measure critic accuracy against ground truth, calibrate thresholds, and report verifier precision/recall.
- Iteration dynamics of MSSC are heuristic: Nmax=3 is chosen without analysis; study diminishing returns, optimal iteration counts, and stopping criteria based on critic confidence or uncertainty estimates.
- Computational cost and latency not reported: modality switching and multiple iterations increase token and compute usage; provide token counts, wall-clock latency, and cost per task to assess practicality.
- Prompt sensitivity and robustness: prompts are referenced but prompt ablations (wording, length, structure) and robustness to minor phrasing changes are not evaluated; conduct prompt sensitivity studies.
- Fairness of baselines: comparisons omit strong ARC-specific program-synthesis/search solvers and advanced test-time training/self-consistency methods; include broader baselines under identical settings.
- Rule representation ambiguity: summarized rules are free-form natural language; evaluate a formal DSL/program representation to reduce ambiguity and enable deterministic application, and compare text vs. DSL summaries.
- Fidelity of visualization invertibility: while invertibility is claimed, error modes in parsing (e.g., color misclassification under compression/aliasing) are not tested; stress-test invertibility with noisy or lossy rendering.
- Scalability limits: matrices up to 30×30 and 10 colors are assumed; evaluate larger grids, more colors, or multi-layer grids, and identify scaling bottlenecks in both modalities.
- Synergy with external memory and test-time training is unexplored: VLSR/MSSC are compared to memory methods but not combined; test whether visual-text synergy plus memory retrieval or TTT yields additive gains.
- Domain shift in fine-tuning: ARC-Heavy-200k synthetic rules may not match official ARC distributions; quantify domain shift, overfitting risks, and cross-benchmark transfer of fine-tuned components.
- Rule summarization faithfulness: the accuracy of generated rules vs. ground-truth rules (when available) is not measured on evaluation sets; develop rule-level metrics (exact match, semantic equivalence) and analyze error types.
- Adaptive modality switching within application: VLSR uses a single switch (vision→text); investigate dynamic, fine-grained switching (e.g., visual global checks interleaved with textual local edits) guided by uncertainty.
- Alternative textual encodings: nested lists may lose 2D inductive bias; evaluate structured 2D tokenizations (row/column markers, relative position tokens) or specialized grid DSLs to preserve spatial structure in text.
- Multi-model critic/generator configurations: MSSC uses the same base LVLM for generation and verification; test cross-model critics (smaller verifier, specialized vision models) to reduce confirmation bias and improve calibration.
- Ambiguity and multiple valid outputs: ARC tasks can admit multiple consistent rules/solutions; analyze how MSSC handles ambiguity and propose mechanisms to generate and verify multiple candidates.
- Human evidence gap: claims about human visual intuition are plausible but no user studies are presented; run controlled human experiments to quantify visual-vs-textual effects on ARC-like tasks and inform model design.
- Reproducibility constraints: reliance on closed-source models and pending code release hampers replication; provide full prompts, visualization specs, seeds, and datasets to enable independent verification.
Practical Applications
Immediate Applications
The following are deployable now using the paper’s training-free strategies (VLSR for visual rule summarization + textual rule application; MSSC for cross‑modal self‑correction) on existing LVLMs.
- Smart spreadsheet and data-wrangling copilots [software, enterprise analytics]
- What: Visualize tabular data as heatmaps/grids to summarize patterns (e.g., grouping, symmetries, outliers) and then apply precise, cell-wise textual formulas/transformations; use visual verification to catch inconsistencies.
- Tools/workflows: Jupyter/VS Code extensions; Google Sheets/Excel add-ins that render grid visualizations, propose textual formulas, and run MSSC visual checks on results.
- Assumptions/dependencies: LVLM access; reliable table-to-visual mappings; guardrails for sensitive data; performance on large tables depends on image token budget and parsing robustness.
- Multimodal document understanding and RPA [software, finance, insurance, gov]
- What: Use visual modality to summarize layout rules in forms/invoices (e.g., column alignment, table boundaries) while applying textual extraction/transformation rules to fields; verify extracted results with visual checks against example documents.
- Tools/workflows: RPA bots with VLSR prompting; OCR + layout parsers (e.g., DocAI) feeding MSSC-based visual consistency validators; ETL nodes that run cross-modal QA.
- Assumptions/dependencies: Quality OCR and layout detection; domain prompts; privacy/compliance controls; handling noisy scans and handwritten content.
- UI testing and regression triage [software QA]
- What: Visual rule summarization of expected page/component patterns (spacing, alignment, color schemes) followed by textual DOM/CSS modifications; MSSC to visually verify regression fixes match examples.
- Tools/workflows: CI pipelines combining screenshot diffs (vision) with codegen/test scripts (text); Playwright/Cypress plugins that incorporate VLSR + MSSC.
- Assumptions/dependencies: Deterministic renderings in CI; stable visual baselines across environments; proper DOM access.
- Code and data-structure assistants for arrays/grids/graphs [software engineering, data science]
- What: Render arrays/matrices/graphs to visually induce transformation rules (e.g., rotations, connectivity, padding), then generate exact code/textual transformations; visually verify outputs match the inferred pattern.
- Tools/workflows: IDE plugins that “grid-render” data structures; diff viewers that overlay visual and textual checks.
- Assumptions/dependencies: Accurate renderers for structures; test datasets; runtime budgets for iterative MSSC steps.
- Business analytics copilots (SQL + charts) [finance, operations, BI]
- What: Summarize chart/heatmap patterns visually (seasonality, clusters) and generate precise SQL/dataframe transforms; run visual post‑hoc checks (e.g., recomputed charts) for pattern consistency.
- Tools/workflows: BI dashboards where VLSR suggests queries; MSSC checks via auto-generated visuals before publishing.
- Assumptions/dependencies: Clean schema metadata; chart reproducibility; governance for autogenerated queries.
- Robotics process planning in 2D workspaces [robotics, warehousing]
- What: Use vision to summarize global layout rules (aisle symmetry, obstacle clusters), generate textual action sequences for precise execution, and re-verify plans visually before actuation.
- Tools/workflows: Warehouse map renderings → VLSR planning → MSSC visual plan audits; integration with task planners.
- Assumptions/dependencies: Accurate maps; bridging plan tokens to controllers; near-real-time latency.
- Educational tools for abstract reasoning and puzzles [education]
- What: Tutors present examples visually to help students and models induce rules; then guide stepwise textual reasoning; MSSC to highlight visual inconsistencies and teach error correction.
- Tools/workflows: Interactive puzzle tutors; classroom content generators that alternate image-led insight with text-led execution.
- Assumptions/dependencies: Age/level-appropriate prompts; explainability UX; alignment with curriculum.
- Model evaluation and safety QA for 2D-structured tasks [AI safety, MLOps]
- What: Use MSSC as an internal critic to reduce confirmation bias in LLM outputs requiring spatial reasoning (e.g., layout-sensitive tasks), without external labels.
- Tools/workflows: Prompt wrappers that run cross-modal verification rounds; red-teaming harnesses that stress-test spatial consistency.
- Assumptions/dependencies: Costs of multiple inference rounds; integration into latency-sensitive systems.
- Visual-then-textual verification in clinical imaging workflows (assistive) [healthcare]
- What: Visual summarization of patterns (e.g., lesion symmetry or connected regions) to guide precise textual measurement/extraction and report structuring; visual checks to ensure consistency with exemplars.
- Tools/workflows: PACS-integrated assistants that annotate global patterns and generate structured text; MSSC for post-hoc plausibility checks.
- Assumptions/dependencies: Strict clinician oversight; validation studies; privacy; domain-specific fine-tuning improves reliability.
- Time-series rule discovery and enforcement [finance, ops, IoT]
- What: Visualize time-series (heatmaps, recurrence plots) for global pattern induction, apply exact textual rules (alerts, transformations), and validate consistency via visual re-plots.
- Tools/workflows: Monitoring platforms with VLSR prompts; MSSC checks before alerting/executing.
- Assumptions/dependencies: Proper visual encodings for temporal data; domain thresholds; false positive/negative handling.
Long-Term Applications
These are feasible with further research, scaling, domain datasets, and integration; they build directly on the paper’s modality-specialization and cross-modal verification principles.
- Self-correcting multimodal agents for complex planning [robotics, autonomy]
- What: Agents that summarize global scene/layout constraints visually, execute fine-grained control via textual/planning representations, and continuously self-verify plans with vision (MSSC) before/after actuation.
- Potential products: Warehouse/autonomous mobile robots with built-in VL critics; surgical robotics pre-action checks.
- Assumptions/dependencies: Safety certification, sim-to-real robustness, real-time cross-modal loops, strong perception stacks.
- Multimodal clinical decision support with cross-modal audits [healthcare]
- What: Combine imaging (global pattern abstraction), EHR text (protocol/rule application), and MSSC-based consistency checks to reduce error rates in diagnostics/treatment planning.
- Potential products: Radiology/oncology assistants that reconcile image patterns with guideline-conformant, text-based recommendations.
- Assumptions/dependencies: Prospective trials; regulatory approval; domain-tuned models; bias and drift monitoring.
- CAD/CAE and design rule automation [manufacturing, architecture]
- What: Visual inference of geometric and topological regularities in designs, followed by precise parametric/textual rule application; MSSC to verify design rule adherence at each iteration.
- Potential products: CAD copilots that enforce design-linting visually; generative design loops with cross-modal QA.
- Assumptions/dependencies: Interfacing with CAD kernels; benchmark datasets of “ruleful” designs; latency constraints.
- Energy grid monitoring and control [energy, utilities]
- What: Visual global pattern detection in grid state heatmaps (load, stability), with exact textual policy execution (setpoints, switching schedules) and visual consistency checks against historical exemplars.
- Potential products: Control room assistants with VLSR planning and MSSC safety interlocks.
- Assumptions/dependencies: High assurance requirements; certified control loops; cyber-physical security; real-time guarantees.
- Scientific discovery assistants [materials, biology]
- What: Visual summarization of microscopy/spectrogram/simulation outputs to induce hypotheses; textual protocol generation and result transformation; MSSC to cross-check consistency with known exemplars and constraints.
- Potential products: Lab copilots for imaging-driven hypothesis formation and automated protocols.
- Assumptions/dependencies: Domain-annotated datasets; robust uncertainty quantification; lab automation integration.
- Generalizable training paradigms for foundation models [AI research]
- What: Architectures and curricula that explicitly split visual “rule summarizers” and textual “rule appliers,” with built-in cross-modal critics; curriculum and data generation aligned to VLSR/MSSC.
- Potential products: Next-gen VLFM stacks with modality-specialized subnets and self-critique loops.
- Assumptions/dependencies: Scalable training data that encodes 2D structure; evaluation beyond ARC; efficient cross-modal token routing.
- Urban planning and remote sensing analytics [public policy, environment]
- What: Visual induction of large-scale spatial patterns (zoning, sprawl, green corridors), textual application of planning rules, and MSSC checks across historical imagery/masks.
- Potential products: Planning copilots for zoning compliance and change-impact audits.
- Assumptions/dependencies: High-quality geospatial datasets; alignment with legal standards; interpretability for stakeholders.
- Regulatory compliance automation with evidence linkage [finance, healthcare, privacy]
- What: Tie visual evidence (dashboards, scans, logs) to textual policy rules; verify compliance via cross-modal checks to reduce false attestations.
- Potential products: Audit assistants that cross-check visual artifacts with rulebooks and filings.
- Assumptions/dependencies: Machine-readable regulations; provenance and chain-of-custody tooling; auditor acceptance.
- Multimodal education platforms for higher-order reasoning [education]
- What: Curricula and assessments that intentionally alternate visual abstraction and textual rule execution, training both skills and a meta-skill of cross-modal self-correction.
- Potential products: Adaptive learning systems with VLSR/MSSC-based lesson plans and assessments.
- Assumptions/dependencies: Longitudinal studies; accessibility and fairness; educator tooling.
- On-device, resource-aware VL compression for structured data [edge AI, privacy]
- What: Use images as compressed carriers of large matrices (as noted in the paper) for global reasoning on-device, with offloaded or local textual precision steps; MSSC minimizing round-trips.
- Potential products: Edge analytics for IoT grids, medical devices, or mobile apps with privacy constraints.
- Assumptions/dependencies: Efficient visual tokenizers; hardware acceleration; privacy-preserving runtimes.
Cross-cutting assumptions and dependencies
- Model capabilities: Requires access to LVLMs with competent vision and text reasoning; open-source models may need domain fine-tuning (the paper’s fine-tuning extension shows viability).
- Representation fidelity: Visual encodings must preserve task-relevant 2D structure; textual formats must be reliably parsed and executed.
- Domain adaptation: ARC-like gains transfer best to tasks with grid/2D structure or clear visual layout semantics; domain-specific prompt templates and datasets boost reliability.
- Latency/cost: MSSC introduces iterative verification passes; systems must budget for multi-round inference.
- Safety and governance: Sectors like healthcare/energy require validation, monitoring, and human oversight; explainability for cross-modal decisions is critical.
- Data privacy: Visualizations can leak sensitive information; masking, redaction, and on-prem deployments may be necessary.
Glossary
- ARC-AGI: A benchmark for evaluating abstract reasoning and generalization by inferring transformation rules from minimal examples. "The Abstraction and Reasoning Corpus for Artificial General Intelligence (ARC-AGI) provides a rigorous testbed for this capability, demanding conceptual rule induction and transfer to novel tasks."
- ArcMemo-PS: A memory-augmented reasoning approach that synthesizes reusable concepts via programs and retrieves them during inference. "ArcMemo-PS builds concept-level external memory through program synthesis and extracts reusable modular abstract concepts, and selectively retrieves relevant concepts during reasoning."
- chain-of-thought: A prompting and reasoning style where models explicitly articulate intermediate steps or rules before producing answers. "either implicitly outputting it in the chain-of-thought, or skipping it directly to output the transformed matrix."
- connected component: In grid-based images, a maximal set of adjacent cells with the same property (e.g., color) treated as a single unit. "rotate each connected component 90 degrees clockwise"
- critic (model as a critic): A role where a model evaluates the consistency or correctness of a proposed output relative to examples. "present the visualized test pair with the examples to the LVLM as a critic"
- Dynamic Cheatsheet: A training-free strategy that stores past reasoning strategies and injects them into future prompts. "Dynamic Cheatsheet \cite{suzgun2025dynamic} stores strategies and findings from past problem-solving processes as memory and includes them in prompts for new problems."
- intrinsic self-correction: Iterative refinement performed by a model without external ground truth or feedback to detect and fix its own errors. "intrinsic self-correction: models struggle to identify errors when verifying their own reasoning in the same modality"
- LVLM (Large Vision-LLM): A multimodal model that processes visual and textual inputs to perform integrated reasoning. "The LVLM then analyzes these visualized examples to derive an explicit transformation rule:"
- Modality-Switch Self-Correction (MSSC): A cross-modal verification mechanism that uses vision to check text-based outputs and iteratively refine them. "MSSC breaks this limitation by employing different modalities for forward reasoning and backward verification."
- Pass@1: An accuracy metric indicating the proportion of tasks solved correctly with the model’s first attempt. "We report Pass@1 accuracy across all experiments at a temperature 0.7."
- pattern consistency verification: Checking whether a predicted transformation adheres to the pattern inferred from examples, typically using visual inspection. "uses the visual modality's strength in pattern consistency verification to check whether the predicted transformation matches the pattern shown in the example images."
- program synthesis: Automatically generating executable programs or modular procedures that capture abstract rules or concepts. "ArcMemo-PS builds concept-level external memory through program synthesis and extracts reusable modular abstract concepts"
- rule application: The phase where an inferred transformation rule is executed on a new input to produce the output. "text excels at precise element-wise manipulation needed for rule application."
- rule summarization: The phase of extracting a general transformation rule from few input-output examples. "vision excels at rule summarization, providing a 3.0\% improvement through its holistic perception of 2D spatial structures"
- test-time training: Adapting a model at inference time using the provided test examples to improve performance on the current task. "test-time training~\cite{sun2020test} is a prevalent strategy."
- Vision-Language Synergy Reasoning (VLSR): A pipeline that uses vision for rule summarization and text for rule application to exploit modality strengths. "Vision-Language Synergy Reasoning (VLSR) matches each sub-task to its optimal modality."
- vision token: A unit in visual encodings (e.g., patch or region embeddings) used by multimodal models to represent images compactly. "a single image with only a few hundred vision tokens."
Collections
Sign up for free to add this paper to one or more collections.