- The paper introduces a unified OCR model that combines text detection and recognition using a CNN encoder and Transformer decoder.
- It employs a novel prompting mechanism for interactive text localization and multimodal token generation in resource-limited scenarios.
- Experiments show improved F1-scores on datasets like SROIE, IAM, RIMES, and MAURDOR, surpassing conventional OCR methods.
VISTA-OCR: Towards Generative and Interactive End-to-End OCR Models
Introduction
The "VISTA-OCR" paper introduces a novel approach to Optical Character Recognition (OCR) by proposing a unified generative model that integrates text detection and recognition. Traditional OCR systems often rely on separate modules for these tasks, leading to error propagation. VISTA-OCR leverages a Transformer-based architecture to jointly handle text transcription and spatial coordination, thereby addressing the constraints of conventional methods and large Vision-LLMs (VLLMs).
Model Architecture
The architecture of VISTA-OCR combines a CNN vision encoder and a Transformer decoder, which processes both visual features and textual prompts to sequentially produce text and corresponding location tokens.
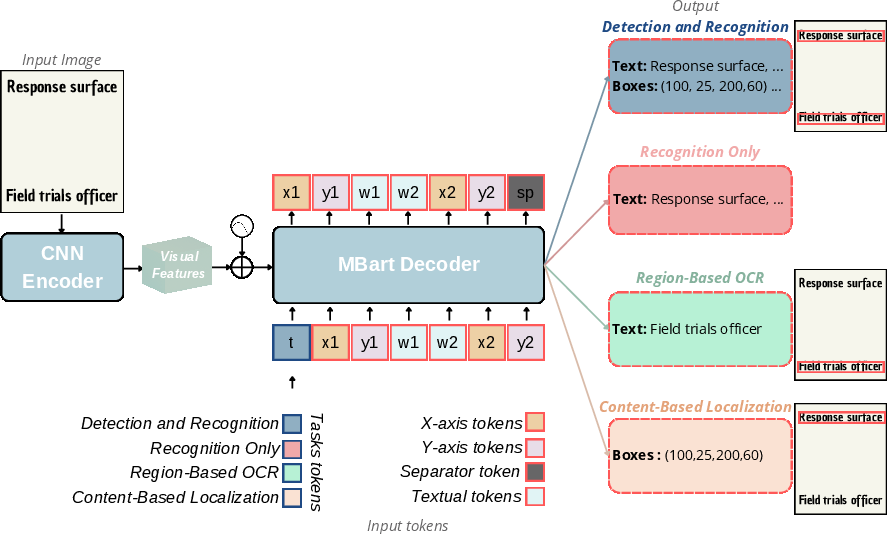
Figure 1: Overall architecture consists of a CNN vision encoder and a Transformer decoder that takes the visual features and a prompt to output sequentially the textual and location tokens.
The model utilizes a novel prompting mechanism that supports interactive and advanced OCR tasks like content-based text localization, often constrained by the computational demands of VLLMs. VISTA-OCR remains efficient with only 150M parameters, contrasting with the high resource requirements of models exceeding 0.5B parameters.
Implementation Details
The implementation of VISTA-OCR is grounded in an encoder-decoder framework enhanced with multitask learning for multimodal token generation. The model's flexibility is achieved through pre-training with diverse tasks, including region-based OCR and content-based localization, using a newly created dataset enriched with synthetic examples.
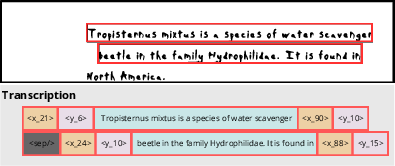
Figure 2: Synthetic image with the corresponding OCR and locations transcription. Each line transcription is delimited by the spatial tokens that encode the upper (resp. lower) position of its bounding box.
Experiments and Results
Extensive experiments on datasets such as SROIE 2019, IAM, RIMES 2009, and MAURDOR validate VISTA-OCR's competitiveness against specialized models. The paper reports improvements in text detection and recognition metrics even when evaluated on complex documents containing both printed and handwritten text.


Figure 3: Examples of Content-Based text localization, in the left the label location highlighted in green and in the right the prediction highlighted in red.
For instance, in text detection on the SROIE 2019 dataset, VISTA-OCR achieves an F1-score of approximately 94.16% when minor adjustments are made to bounding box predictions, showcasing its potential to exceed many existing methods. Additionally, the model demonstrates the ability to handle layout-aware tasks effectively.
Conclusions
VISTA-OCR represents a significant step towards developing more adaptable and efficient OCR systems, integrating generative capabilities within a unified model. While computationally modest, it exhibits the capacity to undertake complex OCR tasks, presenting it as an attractive option for resource-limited scenarios. The work opens doors for future improvements in OCR systems through further exploration of multimodal learning and prompt-controlled interactions.
Overall, VISTA-OCR lays the groundwork for more nuanced and interactive document analysis applications, addressing both text recognition and localization with a generative, end-to-end approach. The future developments could focus on expanding its capabilities beyond the limitations of traditional OCR systems, contributing significantly to the field of document understanding and analysis.

